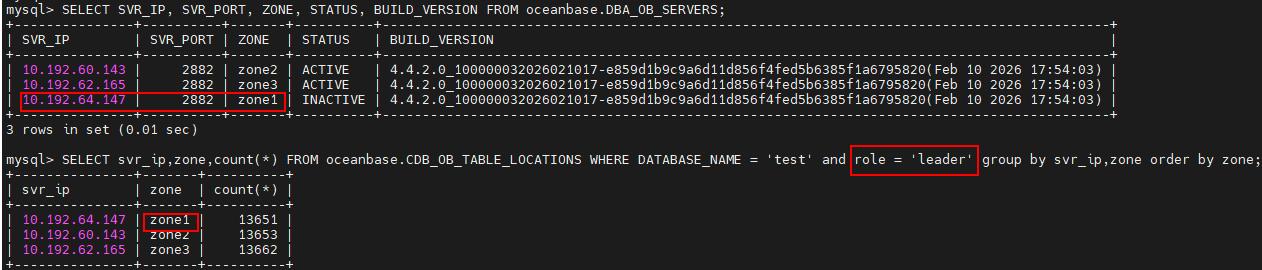
查内部表的切主的事件,确定下日志流具体的切主时间
SELECT value4,svr_ip,svr_port,event,name3,value3 FROM __all_server_event_history WHERE module=“ELECTION” AND value1=$tenant_id AND value2=$ls_id ORDER BY value4;
查看 election.log 里 message not in time、lease expired;查 __all_server_event_history 选举事件OceanBase。
SELECT * FROM oceanbase.__all_server_event_history WHERE module=‘ELECTION’;
SELECT * FROM __all_server WHERE status = 'active';
2. 检查日志流(Partition)的状态
查看所有分区的日志流状态:
SELECT * FROM gv$ob_log_stat;
检查特定租户和日志流的切主事件:
SELECT value4, svr_ip, svr_port, event, name3, value3
FROM __all_server_event_history
WHERE module = 'ELECTION'
AND value1 = $tenant_id
AND value2 = $ls_id
ORDER BY value4;
3. 检查Leader副本分布
查看所有分区的Leader副本分布情况:
SELECT * FROM gv$partition WHERE role = 1;
4. 检查Root Service的心跳状态
查看Root Service与OBServer节点之间的心跳状态:
SELECT * FROM __all_virtual_server_stat;
5. 检查数据一致性
验证数据的一致性:
-- 比较不同节点上的数据
SELECT * FROM table_name LIMIT 100;
故障中和故障后的检查
故障中
监控网络状况:
使用 tsar 工具检查网络抖动:
tsar --tcp -i 1 -dYYYYMMDD
检查是否有丢包或重传:
ifconfig | grep "errors"
检查OBServer进程状态:
确认OBServer进程是否正常运行:
ps -ef | grep observer
检查日志文件:
查看OBServer的日志文件,查找错误信息:
tail -f /path/to/observer/logfile
故障后
检查节点是否重新加入集群:
确认节点是否重新上线并恢复正常工作:
SELECT * FROM __all_server WHERE status = 'active';
检查分区Leader是否正确切换:
验证Leader副本是否已经切换到其他节点:
SELECT * FROM gv$partition WHERE role = 1;
检查数据副本完整性:
确认所有数据副本都已同步:
SELECT * FROM gv$ob_log_stat;
检查系统配置项:
确认 server_permanent_offline_time 配置项是否合适:
SHOW PARAMETERS LIKE 'server_permanent_offline_time';