

背景介绍
在 OceanBase 数据库 2.x 和 3.x 版本中,采用基于主备库的方法进行容灾管理,其 cluster_name 对应一组主备集群。用户登录时默认主集群登陆(cluster_id=0),如果登陆连接串中携带 cluster_id,可以标识主/备集群登录,而 cluster_id 对应的主备关系通过 OCP 进行维护。
但随着 OceanBase 数据库架构的演进,自 4.1.0 版本起将主备的管理方式下放到租户级别,集群级不再有主备角色的概念,集群仅用于管理租户,集群名唯一标识一个集群,对两个不同租户,可以互为主备关系。同时,租户的主备关系将不在数据库中进行维护,数据库中的主备租户相互不记录对方身份,而是通过外部组件(OCP)进行记录维护。为了实现租户级主备的自动路由,OceanBase 数据库引入了服务的概念。一个服务下可以有多个同集群或跨集群的租户,用户在通过 ODP 连接数据库时,可以使用指定服务名的方式将连接自动路由到主租户。
在当前的大环境下,越来越多的企业重视数据库容灾能力,如果经常和客户打交道就应该对"容灾演练","业务快速切换"这些词不陌生,所以在了解到OB通过Service_Name实现业务0修改的快速切换后,这篇文章的也就顺水推舟般发表。
关键点
-
服务名的定义 :服务名是一个逻辑标识符,用于管理和路由租户的连接。它通过 OCP 创建和维护,最终通过 SQL 命令(
ALTER TENANT)实际设置到租户上,OCP 负责在切换、创建备租户等操作时,通过 API 同步设置对端租户的服务名,以确保主备一致。一个服务名下可以有多个备租户,但最多只能有一个主租户。 - 主备租户的服务名 :对于具有主备关系的租户,主租户和备租户的服务名必须相同。
- 非主备租户的服务名 :非主备租户的服务名可以不同,具体取决于业务需求。
- 自动路由 :通过指定服务名,ODP 可以自动将连接路由到主租户,用户无需手动切换连接串。
技术原理
OceanBase 数据库中主备租户路由的基本框架如下图。用户通过特定的连接串登录 ODP,ODP 识别主备租户登录,通过向 OCP 获取相关的租户信息,完成自动路由到主租户,并发往对应的 OBServer 节点。OBServer 节点将校验对应的租户信息,校验通过后 ODP 进行建联,完成整个登录流程。
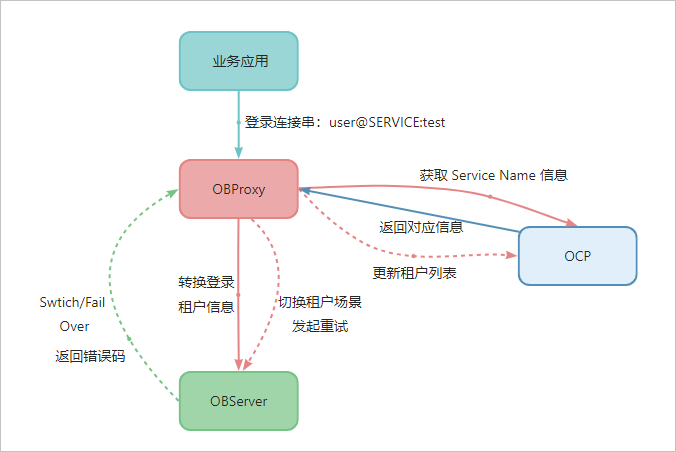
为了让读者更清晰地理解路由决策与连接建立的全过程,我们以一个全新的连接请求为例,梳理其内部的交互步骤:
- 客户端使用
SYS@SERVICE:obora_service连接串连接 ODP。 - ODP 解析出服务名
obora_service,首先检查本地缓存文件obproxy_service_name_info.json。 - 若缓存未命中或已过期,ODP 会依据
config_server_refresh_interval配置的间隔,从 OCP 查询该服务名对应的最新元信息(主租户ID、所属集群等)。 - OCP 返回主租户所在集群(即
ClusterA)的具体 OBServer 地址列表。 - ODP 根据此列表向目标 OBServer 发起建连请求。
- OBServer 进行用户鉴权和租户状态校验。
- 校验通过,连接建立成功,业务请求被正确导向主租户。
Service_Name:
定义了一个服务,通过 SQL 指令将服务名指定给某个租户,OCP 保证主备租户的服务名相同,非主备租户的服务名不同。具体主备租户如下表所示。
| 租户名 | 角色 | 所属 OceanBase 集群 | Service Name |
|---|---|---|---|
| oboracle | PRIMARY | ClusterA | obora_service |
| oboracle | STANDBY | ClusterB | obora_service |
版本限制
OCP、OceanBase、OBProxy 需同时满足如下版本要求:
- OCP:[V4.3.1, +∞)。
- OceanBase:V4.2.1.9、[V4.2.4.0, V4.3.0.0)、[V4.3.3.0, +∞)。
- OBProxy:[V4.3.1.0, +∞)。
功能使用
自动路由
实现自动路由需要如下两个条件,缺一不可:
- 主备租户拥有相同的服务名。
- 主备租户所属的 OceanBase 集群关联同一个 OBProxy 集群,该 OBProxy 集群在访问主备租户时可实现切主自动路由。
设置服务名
当前使用的产品版本:
- OCP:V4.3.2
- OceanBase:V4.2.1.10bp1
- OBProxy:V4.3.1.0
在 OCP 上为租户设置服务名后,可以通过服务名连接该租户。
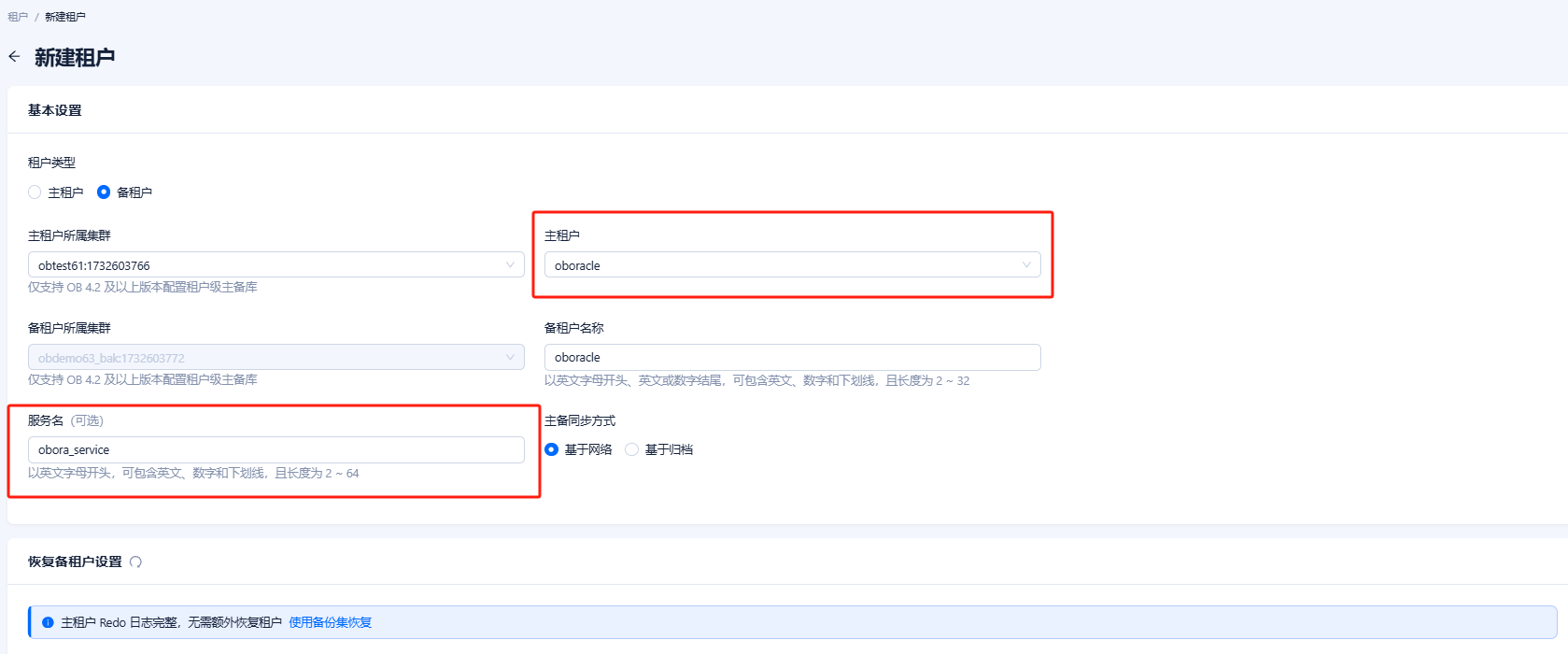
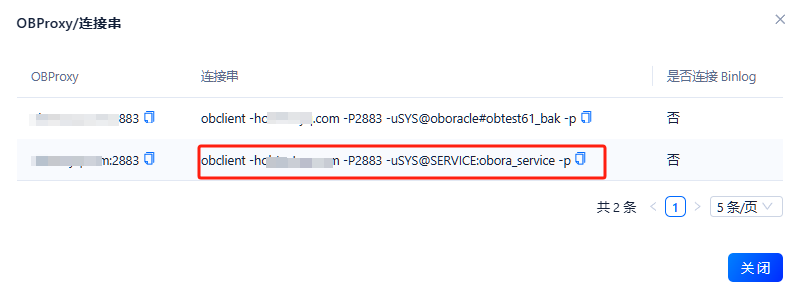
通过OCP–租户–概览–连接串 可以看到已生成带service_name的连接串信息
obclient -hxxxx.com -P2883 -uSYS@SERVICE:obora_service -p

其中 SERVICE_NAME 为关键字,如下方式管理服务名
- 创建租户时指定 :创建租户时可直接指定服务名。
- 租户详情页设置 :在租户详情页为租户添加服务名,并支持对已有服务名进行 编辑 或 删除 。
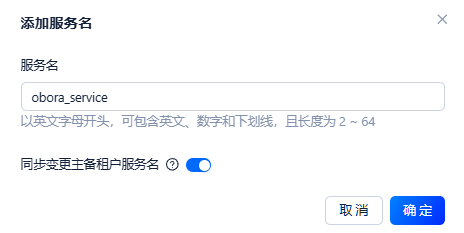
–打开"同步变更主备租户服务名"后,创建该主租户的备租户时会自动带入服务名
同步服务名 :OCP 每分钟会进行一次租户信息同步,将 OceanBase 内部表/视图中的租户信息与 OCP 中的元信息进行对比,并进行更新,此时租户服务名会随之更新。
ODP 路由
ODP 支持配置 Service Name 登录后,支持主租户的自动路由能力。具体如下:
- **路由重试:**当后端发生 Switchover/Failover 时,ODP 根据协商的错误码,主动重试可用租户列表(支持跨集群重试)。切换到主租户重试时将不会返回错误,从而实现业务无感知的路由切换。
事务中路由行为深度分析
ODP 不会切换租户,依然将请求发往事务开启的租户。
事务中路由
begin;
create table t1(idint);
insert into t1 values('1'),('2'),('3');
select * from t1;

–UNDECIDED 一般表示未决定最终态
此时进行主备租户切换,主备租户上均无法找到此事务。
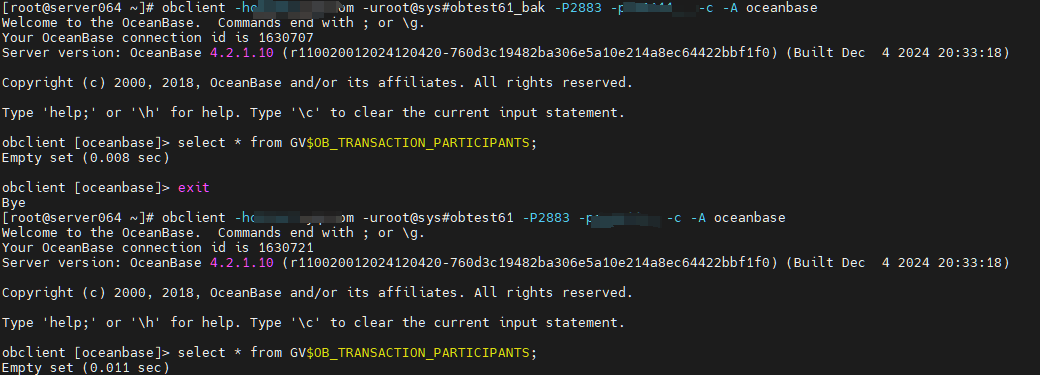
出现的问题
此时commit会出现以下报错,连接已断开,事务已被回滚。
ErrorCode = 1220, SQLState = 08000, Details = (conn=1612466) Connection is closed
日志信息如下:
grep ‘txid:2215996’ observer.log
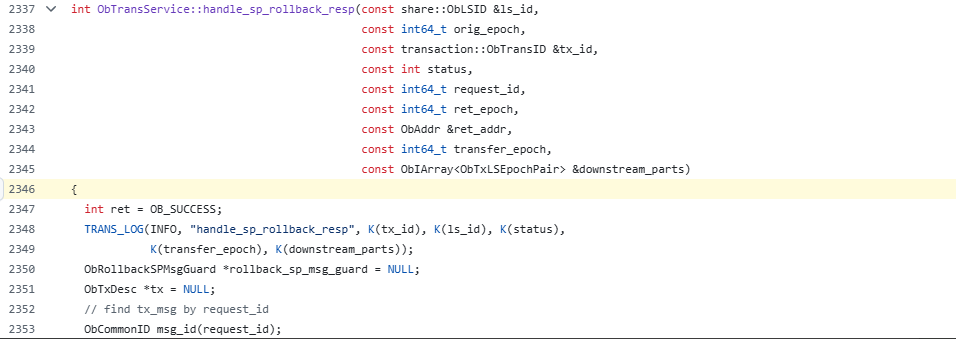
observer.log.20241219151030995:[2024-12-1915:09:04.864304] WDIAG [STORAGE.TRANS] process (ob_trans_rpc.cpp:147) [18605][T1006_L0_G0][T1006][YB420A00003D-000629861CD6FF55-0-0] [lt=10][errcode=-4038] handle txn message fail(ret=-4038, ret="OB_NOT_MASTER", msg={txMsg:{type:62, cluster_version:17180000522, tenant_id:1006, tx_id:{txid:2215996}, receiver:{id:1001}, sender:{id:9223372036854775807}, sender_addr:"10.0.0.61:2882", epoch:-1, request_id:1734592144862283,timestamp:1734592144863119, cluster_id:1732603766}, status:-6224})
observer.log.20241219151030995:[2024-12-1915:09:04.864573] WDIAG [STORAGE.TRANS] handle_trans_msg_callback (ob_trans_service_v4.cpp:2346) [17107][pnio1][T1006][YB420A00003D-000629861CD6FF55-0-0] [lt=16][errcode=0] handle trans msg callback(ret=0, elapsed_ts=0, tx_id={txid:2215996}, sender_ls_id={id:9223372036854775807}, receiver_ls_id={id:1001}, msg_type=62, status=-4038, receiver_addr="10.0.0.61:2882", request_id=1734592144862283)
关键日志项解读:
-
tx_id={txid:2215996}:事务 ID。 -
receiver_ls_id={id:1001}:接收方日志流 ID。 -
status=-4038:状态码,表示OB_NOT_MASTER,即接收方已不是主节点。 -
handle_trans_msg_callback:事务消息回调处理函数,见于ob_trans_service_v4.cpp:2346。 -
status=-6224:表示transaction need rollback,需要回滚。
问题原因
原因非常明确:-4038 错误表示接收节点不再是主节点,无法继续为事务协调日志提交,导致事务失败回滚。-6224 则是此结果下的标准化内部错误码。
最佳实践与应对策略
基于此测试,可以得出核心结论:SERVICE_NAME 自动路由方案不具备事务级的无缝切换能力 。在切换瞬间,活跃事务必然会中断。因此,为保障核心业务连续性,必须做到:
-
应用层改造 :应用程序必须实现事务重试机制。当捕获到
Connection is closed或错误码OB_NOT_MASTER时,应捕获异常,重建连接,并重试整个事务逻辑。 - 客户端配置 :利用数据库驱动自身的故障转移机制。例如,OceanBase Connector/J (Java) 支持连接黑名单与自动重连,可在连接 URL 中配置相关参数,使驱动在发现连接断开时自动剔除故障节点并尝试获取新连接,这有助于加速重试过程。
运维方法
可通过如下两个配置项控制 Service Name 功能的使用:
- enable_standby 配置项控制是否开启主备租户路由能力。默认为 True,如果配置为 False,ODP 将不会使用 Service Name 路由能力。(对 OceanBase 数据库 V4.2.4 及之后版本生效)
- config_server_refresh_interval 配置项控制 ODP 从 OCP 中获取 config server 信息的时间间隔,默认为 60s。Service Name 相关信息也使用此配置
注意事项
通过 Service Name 登录时不受 enable_cloud_full_username 和 enable_full_username 配置项影响。
当出现主备租户相关问题时,可查看 Service Name 租户缓存信息或错误码进行排查:
- 对通过 Service Name 登录的用户,在 ODP 安装目录下的 etc 目录下会生成缓存文件 obproxy_service_name_info.json,通过此文件可以排查 ODP 获取的 Service Name 转换是否正确。
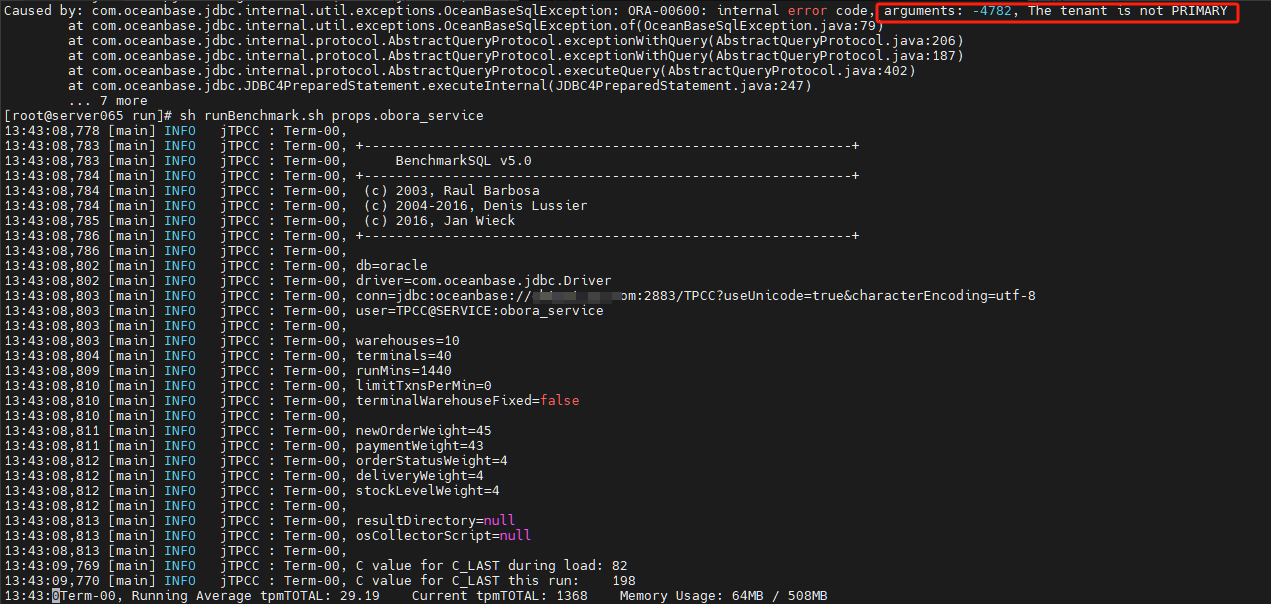
- 错误码 OB_NOT_PRIMARY_TENANT(-4782) 表示 SQL 请求发给了备租户,此时可能执行了 SwitchOver。
- 错误码 OB_SERVICE_NAME_NOT_FOUND(-4780) 表示此 Service Name 在 OceanBase 数据库中不存在,此时 ODP 缓存信息可能过期。
- obclient -hxxx.com -P2883 -usys@SERVICE:obora_service1 -p
- ERROR4780(HY000): service name not exist
- obclient -hxxx.com -P2883 -usys@SERVICE:obora_service1 -p
切主场景应用
日常切换
注意事项
通常业务是通过域名+端口的方式访问数据库,只有在此情况下才能实现业务主备租户切换时,业务程序不需要任何修改,无感知的切换。
日常切换新增如下两项预检查:
- 主备租户都未配置服务名,或配置了一致的服务名。
- 主备租户有服务名时,不能与其他无主备关系的租户服务名相同。
日常切换前,如果备租户所在的 OceanBase 集群没有关联主租户所在 OceanBase 集群关联的 OBProxy,OCP 会给出明确警告: 日常切换后可能无法自动路由,但不会强行禁止日常切换。日常切换不会修改租户的服务名,业务应用使用 用户名@Service_Name的方式通过 OBProxy 访问 OceanBase 租户,不需要修改连接串。
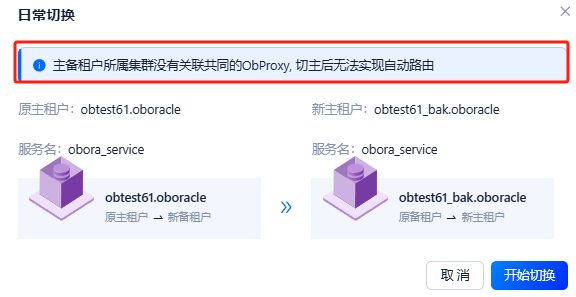
将主备租户所属集群关联至同一个obproxy集群后,没有此提示

容灾切换
OceanBase 在执行容灾切换时,会将新主租户的服务名删除,业务将无法通过服务名连接新主租户,因此必须修改连接串。为了实现不修改连接串,OCP 进行了功能包装,即在 OCP 上执行容灾切换前选择是否为新主租户设置服务名,此为可选操作。您可保持新主租户的服务名与原来一致,此时 Failover 后业务可不修改连接串直接访问新主租户。
验证主备切换
- 对主租户进行压测
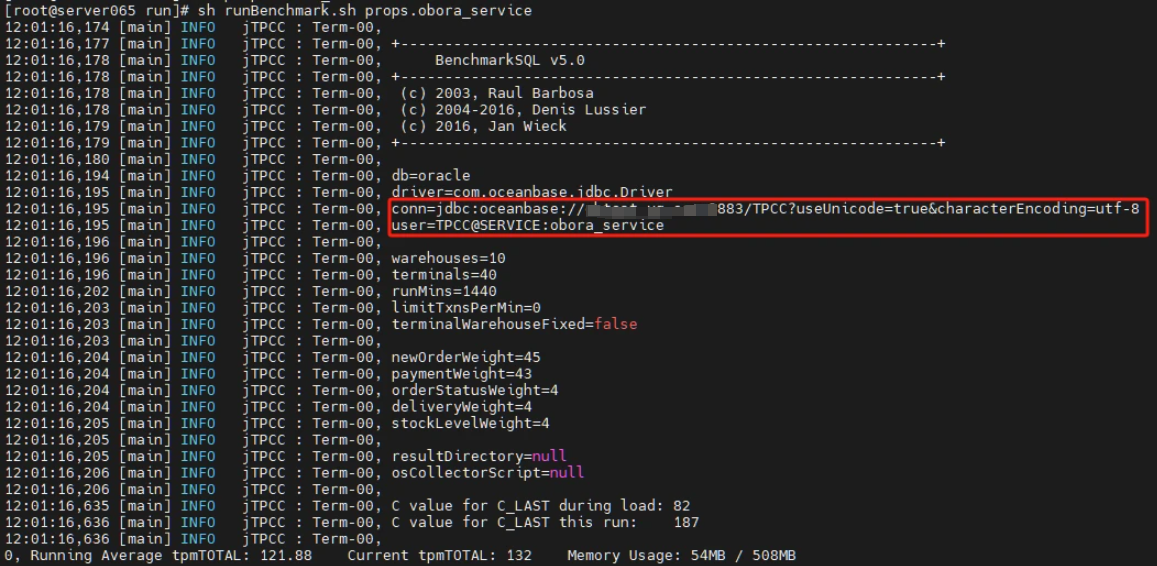
- 切换主备租户

- 正在跑的压测由于主备租户切换,导致原来的会话访问到备租户上,无法读写,导致压测终端,不修改任何参数,模拟应用切换,可以继续压测。此时压力都打在主租户(原备租户)
正在跑的压测由于主备租户切换,导致原来的会话访问到备租户上,无法读写,压测中断。不修改任何参数,模拟应用重启/重连,可以继续压测。此时压力都打在原备租户(新主租户)上。
切换后,流量平滑转移到新主租户
整体主备租户切换,人为感知大约在 1 秒左右,业务理论上无感知。
中断原因:由于此时正在进行主备租户切换,SQL 请求发送给了备租户,报错 OB_NOT_PRIMARY_TENANT 。
结论与适用场景
基于 Switchover 与 Failover 的实际表现,其特性与风险总结如下:
- Switchover (计划内切换)
- 可控环境下的主备切换,通常用于运维操作(如滚动升级)。
- 切换前可主动检查备租户的 RPO,确保其为 0。
- 风险点:切换前若未确认备租户已同步完成,可能导致短暂的数据不一致。
- Failover (故障切换)
- 主节点故障后系统自动将备租户提升为主租户。
- 此过程不可控,可能存在 RPO > 0 的情况。
- 风险点:业务连接可能被路由到尚未完全同步的新主租户上,造成数据丢失或不一致。
优化方案
-
针对 Switchover :建议在切换前确保备租户的 RPO 等于 0。可通过调小 OCP 参数
ocp.standby.tenant.delay.threshold(单位毫秒)来实现,使得备租户延迟尽可能小,确保数据完全一致后再切换。需注意,此参数可在 OCP 系统参数中调整,但调得过小可能因轻微网络抖动导致切换一直无法进行,需权衡。 - 针对 Failover :Failover 不可控,需要在平时加强巡检与监控,对主备租户同步延迟配置告警,提升对延迟的可控性。此外,应定期进行容灾演练,将 Failover 切换过程标准化,并结合事后数据校验(select count(*)或外部工具),确保新主租户的数据完整性和一致性。
适用场景推荐
- 强烈推荐 :互联网应用、微服务、单元化架构等,能接受极短时间中断且应用层有成熟重试机制的读写业务。Service Name 方案可极大简化其异地多活架构下的容灾切换逻辑。
- 需谨慎评估 :核心金融交易、账务系统等强一致性业务。此类系统必须在上层事务重试、严密的数据校验及 RPO=0 保证下使用,仅靠路由切换是不足的。
- 不适用 :无事务管理的简单脚本、无法在连接断开时自动重试的遗留应用。自动路由带来的瞬间闪断依旧会导致此类应用直接报错退出。