吉利蛋
2026 年5 月 26 日 16:16
#1
【 使用环境 】生产环境
[root@cdh85-138 .ssh]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/centos-root 8.8T 820G 8.0T 10% /
devtmpfs 126G 0 126G 0% /dev
tmpfs 126G 12K 126G 1% /dev/shm
tmpfs 126G 1.6G 125G 2% /run
tmpfs 126G 0 126G 0% /sys/fs/cgroup
/dev/sda2 1014M 143M 872M 15% /boot
cm_processes 126G 384K 126G 1% /run/cloudera-scm-agent/process
tmpfs 26G 0 26G 0% /run/user/0
tmpfs 26G 0 26G 0% /run/user/1000
tmpfs 26G 0 26G 0% /run/user/1002
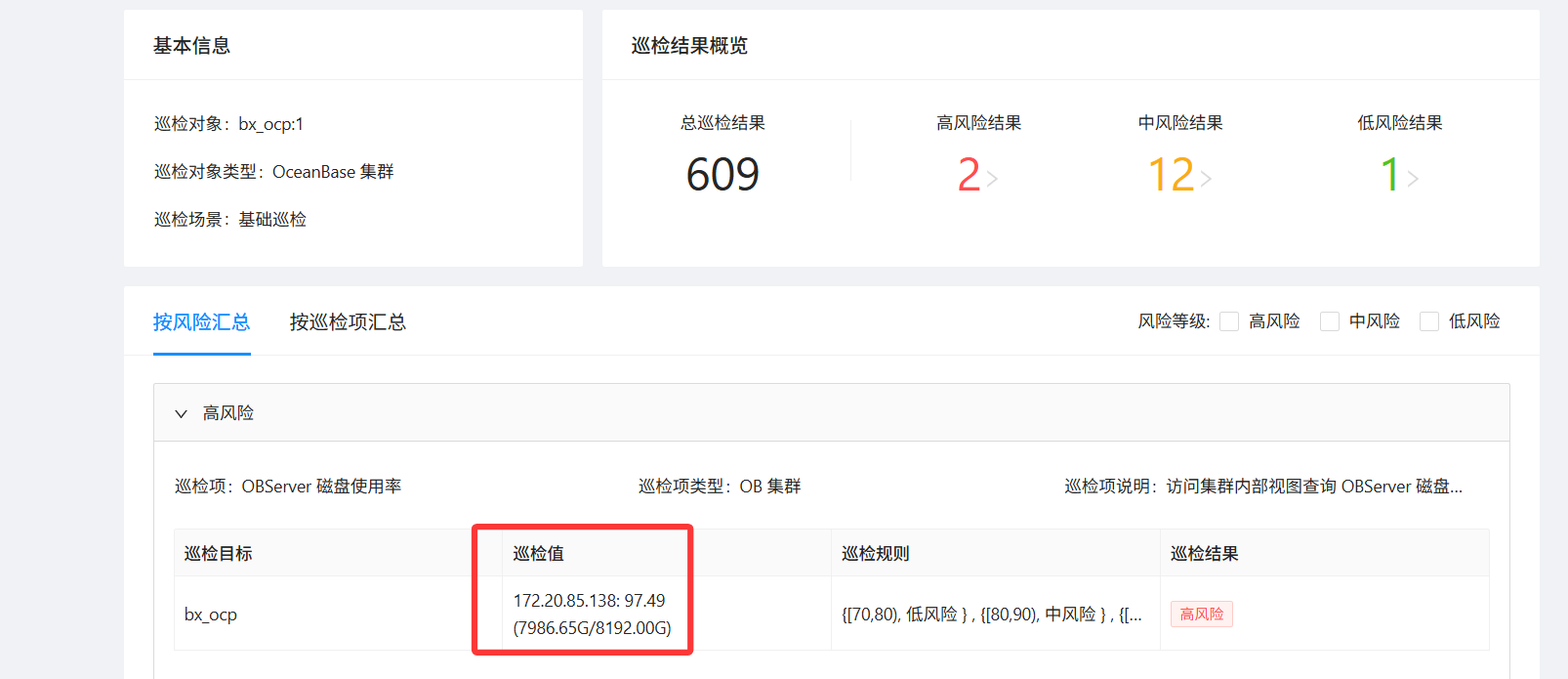
这巡检报告巡检出来说我机器磁盘用了97%,实际上明显不对,根目录8.8T也就用了10%,是BUG吗?
10 个赞
吉利蛋
2026 年5 月 26 日 16:28
#4
如果是预占,应该df -h能直接看到是90%的吧?
1 个赞
吉利蛋
2026 年5 月 26 日 16:29
#6
那我现在df -h看到的是正常的10%,说明不是预占问题
2 个赞
吉利蛋
2026 年5 月 26 日 16:32
#7
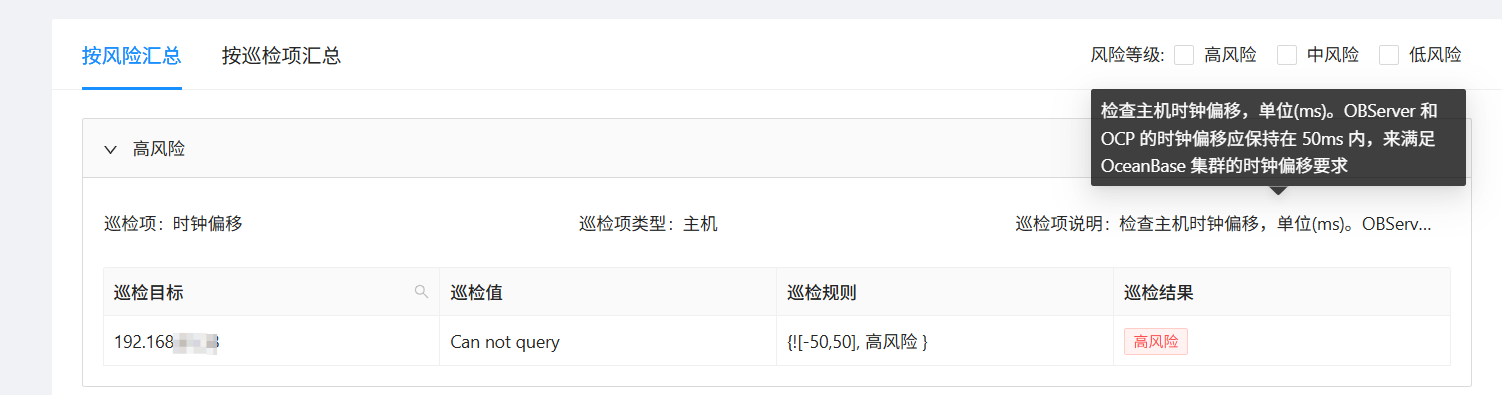
还有这个时钟偏移,说巡检值是can not query,是跑的啥命令没跑成呢?我看sudo systemctl status chronyd服务是正常的
1 个赞
辞霜
2026 年5 月 26 日 16:40
#8
执行下这个看下
2 个赞
辞霜
2026 年5 月 26 日 16:43
#9
使用的是clockdiff命令 缺少clockdiff
2 个赞
吉利蛋
2026 年5 月 26 日 17:13
#13
obclient [(none)]> use oceanbase;select svr_ip, round(allocated_size/1024/1024/1024, 2) as total, round((allocated_size-free_size)/1024/1024/1024, 2) as used, round((allocated_size-free_size)/allocated_size*100, 2) as percent from __all_virtual_disk_stat;
这个算出来确实是97了,这要紧吗
吉利蛋
2026 年5 月 26 日 17:37
#14
吉利蛋:
巡检值是can not query
root@cdh81-38 chansey]# clockdiff -o xx.xx.85.138
吉利蛋
2026 年5 月 26 日 17:43
#15
看花眼了,这96.84是GB,不是百分比。。那和报告也对不上啊 @辞霜
辞霜
2026 年5 月 26 日 18:02
#16
是ocp的ip对着巡检集群执行clockdiff
吉利蛋
2026 年5 月 26 日 18:18
#17
[root@cdh85-138 chansey]# clockdiff -o 192.168.81.38
ocp往报错机器试clockdiff也是有结果的
吉利蛋
2026 年5 月 26 日 18:19
#18
还有就是ocp集群本身的巡检报告里也有这个clockdiff的can not query报错,明明clockdiff自己也是ok的
吉利蛋
2026 年5 月 26 日 19:15
#20
是的 obd机器的root用户跑的部署,然后ocp机器上我ps -ef|grep server看也是运行在root下面的
1 个赞