

部署集群与单个数据有区别嘛。
三副本每一个节点有什么作用呀?
三副本写入读取的原理,如何降低性能的压力,能不能降低IO 压力
26 个赞
集群相比于单个数据库,在资源占用和部署上有明显差异。集群通过多个节点共同工作,实现了负载均衡、高可用性和可伸缩性。在资源占用方面,集群能够更有效地利用CPU、内存和网络带宽等资源,减少单点瓶颈。部署集群相较于单个数据库而言,需要更多的硬件资源,但同时也提供了更高的容错能力和数据可靠性。
对于三副本的每个节点,其主要作用如下:
- 提高可用性:通过在不同的节点上存储相同的数据副本,即使某个节点发生故障,其他节点仍然可以继续提供服务,确保系统的高可用性。
- 增强容错性:当一个节点发生故障时,其他节点可以接替其工作,保证数据的完整性和一致性。
- 提升性能:读操作可以在多个副本之间分摊,从而提高系统的读取性能。
关于三副本的写入和读取原理:
- 写入:客户端向Leader副本发送写请求,Leader副本将写请求同步到其他Follower副本,当大多数副本(至少两个)确认收到写请求后,Leader副本才会返回写成功。
- 读取:默认情况下,读请求会路由到Leader副本,但如果配置了弱一致性读,读请求也可以路由到Follower副本,从而分散读取压力。
为了降低性能压力和IO压力,可以采取以下措施:
- 优化SQL查询:通过优化SQL查询,减少不必要的数据扫描和计算,提高查询效率。
- 使用只读副本:通过配置弱一致性读,将读请求路由到Follower副本,减少Leader副本的IO压力。
- 分区表:合理设计分区表,将数据分布在不同的节点上,减少单个节点的负担。
- 负载均衡:通过负载均衡技术,将请求均匀地分配到不同的节点上,避免某些节点过载。
更多信息请查看:
7 个赞
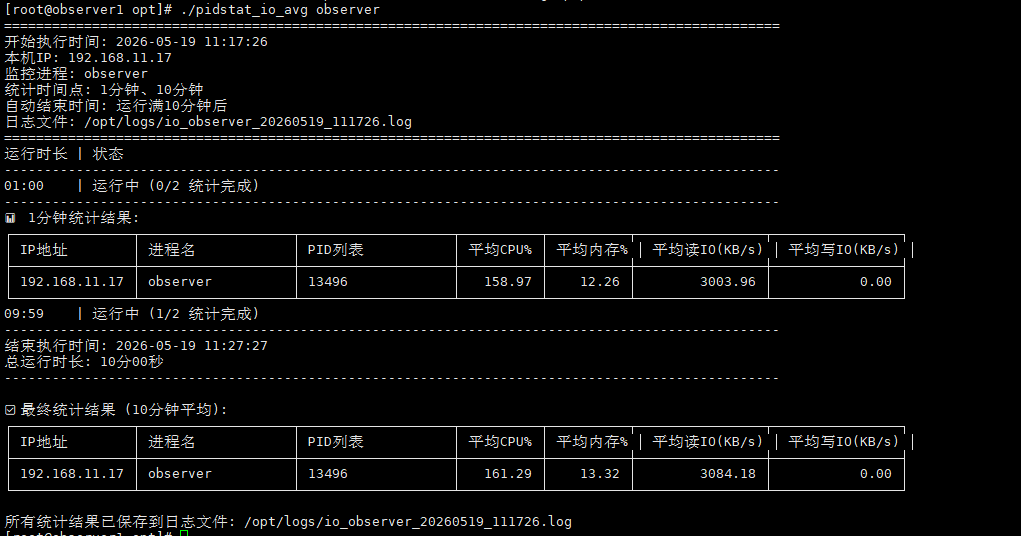
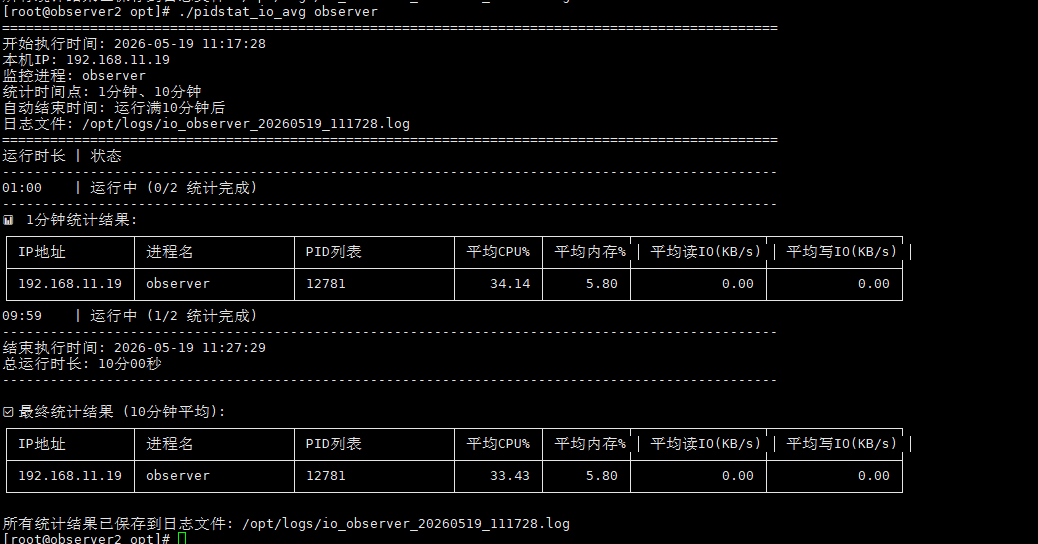
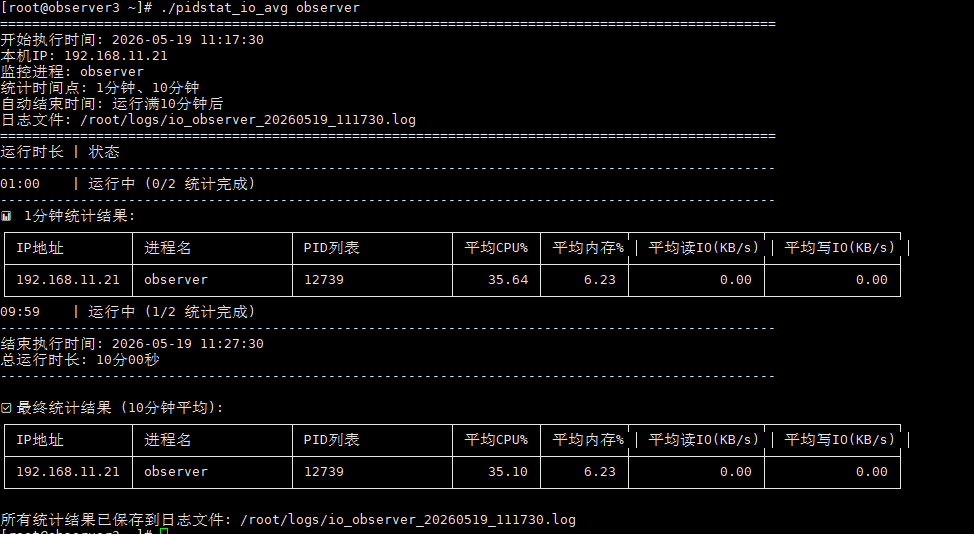
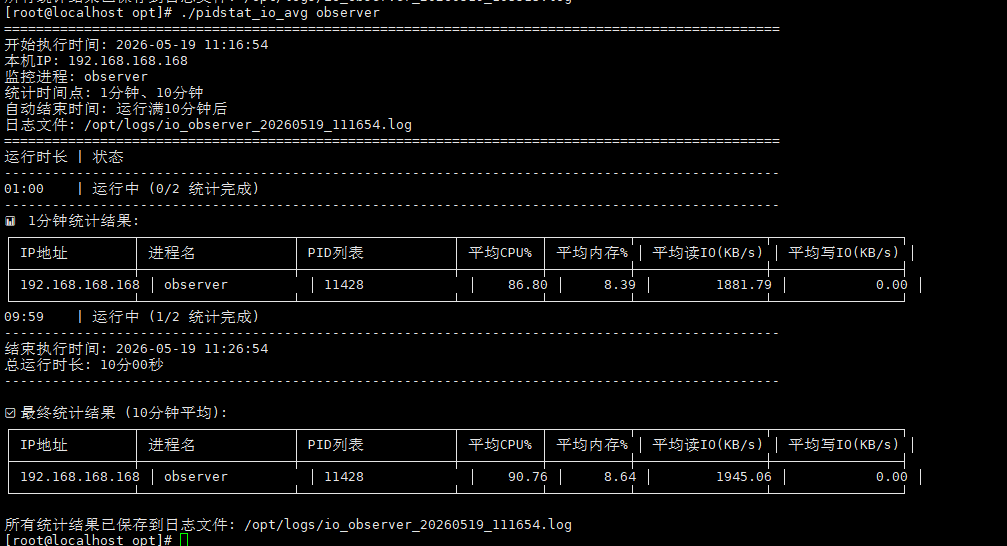
三副本集群在做插数据的测试时候时,发现只有主节点有io波动,其他的两个节点都没有io波动
这是为什么。
我想知道其他节点是怎么同步数据的,为什么检测进程observer其他的节点没有io波动
要的cpu,内存也比单数据库部署时候需要的更多
我不太了解,检测进程发现其他两个节点io一点变化也没有
弱一致性读是对一个节点租户的配置嘛
三副本集群
单数据库
@论坛小助手
3 个赞
在 OceanBase 的三副本集群中,主节点负责处理所有的写入请求,而其他节点(副本节点)则是通过主节点同步数据。这是因为 OceanBase 采用的是强一致性的复制模型,即主节点会将事务的 Redo 日志同步给副本节点,副本节点接收到日志后进行重放,从而保证数据的一致性。
在插数据测试中,主节点会产生大量的 IO 波动,因为它需要处理写入请求并将日志同步给副本节点。而副本节点虽然也会接收到日志并进行重放,但由于重放过程相对较为平滑,且不需要处理实际的写入请求,因此 IO 波动较小,甚至可能检测不到明显的 IO 波动。
关于弱一致性读,它是一种针对读操作的优化机制,允许读取到最近已提交的数据,而不是最新未提交的数据。弱一致性读通常是对一个节点租户的配置,但这并不意味着其他节点不会参与读操作。在某些情况下,读请求可能会路由到其他节点,以减轻主节点的负载。
至于为什么在三副本集群中,其他节点的 CPU 和内存使用率较高,这可能是因为副本节点在进行日志的接收和重放过程中,需要消耗一定的计算资源。此外,副本节点还需要维护数据的一致性和可用性,这也可能导致资源使用率较高。
更多信息请查看:
- 影响 OceanBase 数据库连接超时的相关配置一般有哪些
- 弱一致性读
4 个赞
同步数据的过程主要是通过对日志(例如:事务日志 clog)的同步来进行的。这可以从文档中得知,OceanBase 数据库利用日志服务(如 clog)确保事务的原子性、持久性、隔离性和数据库高可用等功能。日志同步是OceanBase数据库实现数据一致性与高可用的关键技术之一。因此,在同步数据时,不会直接通过数据库本身去同步,而是通过同步日志的方式来保证数据的一致性和可靠性。
具体信息可参考以下文档:
3 个赞
集群插入速度更快主要得益于以下几点优化:
- 资源的集中管理和弹性伸缩能力:OceanBase 数据库能够把数据打散到不同机器,从而解决可扩展性问题,真正体现出分布式架构的优势。当集群或者租户的容量不足时,只需要增加更多的节点,集群就能够容纳更多的租户,租户也能够容纳更多的数据和业务流量。多副本部署能力使得 OceanBase 具有多级无损容灾能力。
- LSM-Tree 存储引擎:OceanBase 数据库基于 LSM-Tree 的存储引擎,将数据分为内存中的 MemTable 和磁盘中的 SSTable。所有的数据更新写入操作都在内存的 MemTable 中完成,并且在内存使用量达到一定阈值后触发 Compaction,转储至 SSTable,并释放活跃的内存。这种架构的优势是可以将随机 I/O 转化为顺序 I/O,提供更大的写入吞吐能力。
- 合并操作和压缩:合并操作是将动静态数据做归并,把当前大版本的 SSTable 和 MemTable 与前一个大版本的全量静态数据进行合并,产生新的全量数据。合并期间 OceanBase 数据库会对数据进行两层压缩,第一层是数据库内部基于语义的编码压缩,第二层是基于用户指定压缩算法的通用压缩,使用 lz4 等压缩算法对编码后的数据再做一次“瘦身”。压缩不仅节省了存储空间,同时也极大地提升了查询性能,而且对数据写入性能几乎无影响。
更多信息请查看:
2 个赞
是ob数据库集群和单一个ob数据库相比插入数据这方面有什么区别,集群是更快的
1 个赞
在OceanBase数据库集群中,插入数据的速度并不一定会比单一数据库更快。OceanBase数据库采用读写分离的架构,将数据分为基线数据和增量数据。增量数据首先会被写入内存中的MemTable,而基线数据则存储在SSD盘上的SSTable中。对数据的修改操作(如插入)都是针对内存中的增量数据进行,这意味着DML操作性能很高,因为它们完全是内存操作。然而,读操作需要合并内存中的增量数据和磁盘上的基线数据,这可能会增加一定的延迟。此外,OceanBase数据库还实现了Block Cache和Row Cache来避免对基线数据的随机读,这有助于提升读性能。
集群环境下,OceanBase提供了数据的分布式存储和多副本机制,可以实现数据的横向扩展。这意味着在插入大量数据时,可以通过分布在不同节点上的多个租户并行处理,从而提升数据插入的整体性能。但是,具体的插入速度还受到网络延迟、数据同步机制等因素的影响。总的来说,集群环境下的OceanBase数据库在数据插入方面具有更高的可扩展性和灵活性,但在某些情况下,单一数据库的插入性能可能不会逊色于集群。
具体信息可参考以下文档:
在 OceanBase 数据库中,Leader(主副本)承担了强一致性场景下事务中的读写请求,因此每个分区 Leader 的分布决定了流量在每个节点上的分布。这意味着读操作的压力主要由 Leader 所在的节点承担。然而,为了平衡负载,可以通过设置 Primary Zone 为 RANDOM 将不同分区的 Leader 分散在不同 Zone 的节点上,使得整个集群机器利用率达到最大化。此外,对于只读查询,可以通过设置弱一致性读(如使用 OBProxy 或者 SQL 提示),将读请求路由到只读副本,进一步分散读压力。
检索到的文档如下:
- OceanBase 数据库性能的影响因素
- 如何路由到只读型副本查询数据
- 分布式执行和并行查询
1 个赞
在 OceanBase 的三副本集群中,主节点负责处理所有的写入请求,而其他节点(副本节点)则是通过主节点同步数据。
1 个赞
主节点leader节点写入数据,其他节点同步数据。
2 个赞
设置了primary节点之后,所有的写会在primary节点,所以看到primary节点的负载相对高一些。也可以把做分布式,把数据打散到3个节点。
2 个赞
解释的精辟,学习了,OB的分布式特性,可操作性还是比较多的
1 个赞
写得非常详细,学习了。
1 个赞
宝贵的经验分享,谢谢!