问题描述
有数十个mysql分片表,数据行数几乎都是5亿到8亿不等,有2个表有10几亿行,使用oms迁移到ob一个表中,小于10亿的表都在几个小时内迁移完成,剩余2张10几亿的表迁移了2天,才完成1/50,RPS就100到1000之间波动,平均就400多,速度很慢,估计得2个多月吧。
基础信息
1、源端是mysql5.7,目标端是oceanbase4.3.5,迁移工具是oms4.2.10,都是社区版
2、源表是分库分表的数十个表,每个表结构都一样,有2个索引一个是主键id索引,另外一个是外键索引,主键和外键行数比例大概1:2,10几个字段,没有大字段,目标表是1个分区表
3、主键id和外键结构一样,像这样157586288211000042(时间戳 + 2位集群id + 6位随机数字)
4、使用oms进行全量+增量迁移,上述问题是发生在全量迁移阶段的
分析处理
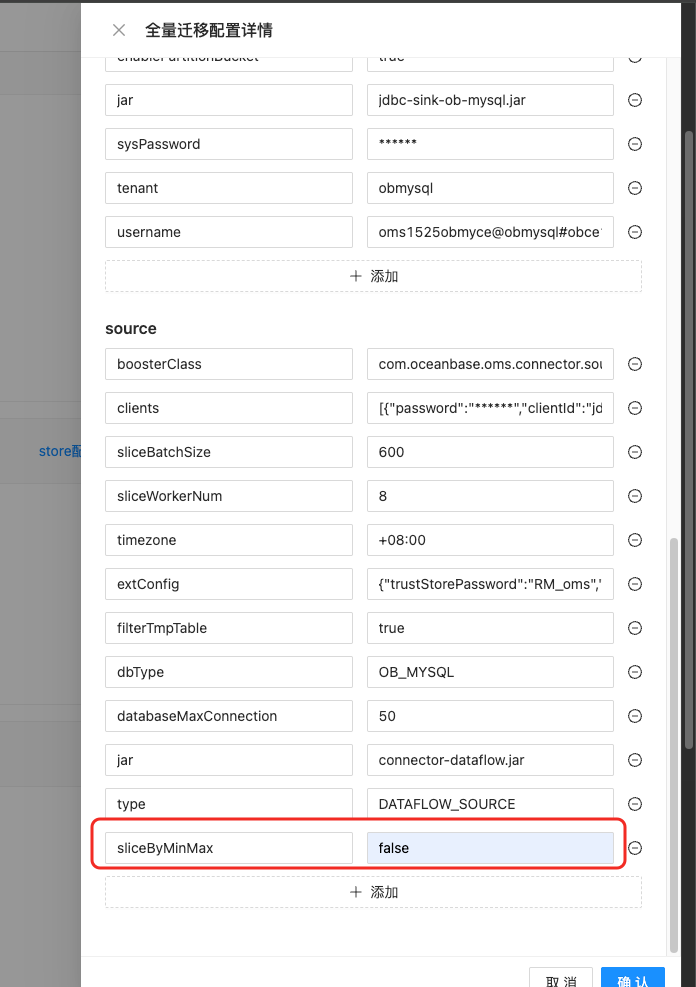
1、查看日志 metrics.log, slice_queue值是100多不到200;使用 ./connector_utils.sh metrics命令分析,没发现gc和其他问题;查看日志connector.log发现源端sql查询范围类似 [id:157586288211000042] - [id:157586288213000042]}],这个top和bottom差值是2000000。参考官方ai工具的建议对全量迁移组件Full-Import,将参数workerNum和sliceWorkerNum调大,将sliceBatchSize从600调100000、10000000,全量迁移速度没有明显变化
2、参考文章《如何加快OMS大表迁移》(https://open.oceanbase.com/blog/10780163664),配置参数sliceIndex为外键索引,依然没啥效果,迁移速度还是很慢,这个是因为主键和外键结构一样,主键和行数比例大概1:2的原因吧。还有源表虽然有类似created字段但没有建索引,也没法参考文中其他建议。
3、花了半天多也没找到解决办法,最后将oms迁移任务中那2个表删除,使用任务进入到增量阶段继续运行,然后使用mysqldump将那2个表导出为replace语句,执行导入到ob中,最后新建了个增量任务单独同步这2个表数据
疑问建议
oms源端拆分读取数据应该是假定主键或者其他索引字段是自增的,这对于那些类似雪花算法生成分布式主键不友好,还有源端读取的主键top和bottom差值是2000000,怎么调整参数也不能增大,应该是固定死了,如果能增加个配置参数那就比较好了
另外,对这里的问题,大家还有其他好的处理方法,麻烦给点建议,![]()
![]()
![]()