

最近在往ob中批量写入数据,注意到一个情况是,每天的9点10分到9点20分这个时间段,insert执行时间会变慢,从ob_sql_audit中看,这个时间段insert的elapsed_time在5000以上,而其它正常时间段的elapsed_time在1000以下。经过排查,发现是9点10分到9点20分这个时间段的wait_time_micro增加导致,sql的event是sync rpc,并且这一时间段内的rpc_count值没有变化。通过ob_rpc_incoming查询pcode的值为ob_gais_next_auto_inc_request,并且表的auto_increment_mode是order。因此怀疑是这一时间段由于集中申请自增值时间过长导致的执行时间变慢。但是看了对应observer这一事件段的cpu,内存,iops和网络,没有发现异常波动。并且这一事件段集群内也没有自动执行定时任务,备份,归档,数据合并等操作。
7 个赞
是不是那段时间在合并数据,这是个常见问题吗
4 个赞
不是在那个时间段合并数据,查询了任务表,合并数据是在凌晨两点开始,凌晨三点结束的
4 个赞
你把ob_sql_audit的信息发一下 还有这个时间的ash报告 也发一下 ob的版本号也发一下
可以使用obdiag收集ash报告
https://www.oceanbase.com/docs/common-obdiag-cn-1000000005726952
4 个赞
ob版本是4.4.2.0
3 个赞
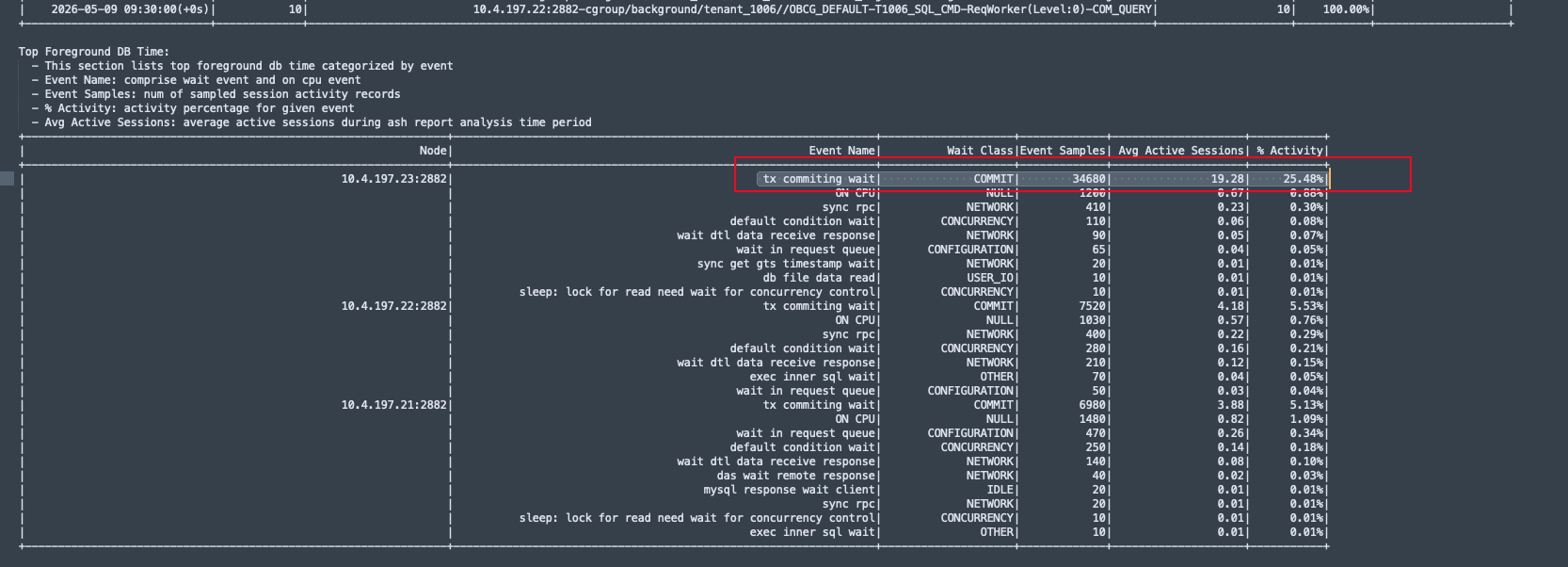
INSERT 慢,主要是提交阶段被日志持久化与复制链路拖住,怀疑是clog落盘慢或者是事务执行较长 没有提交或者是副本同步的延迟较大
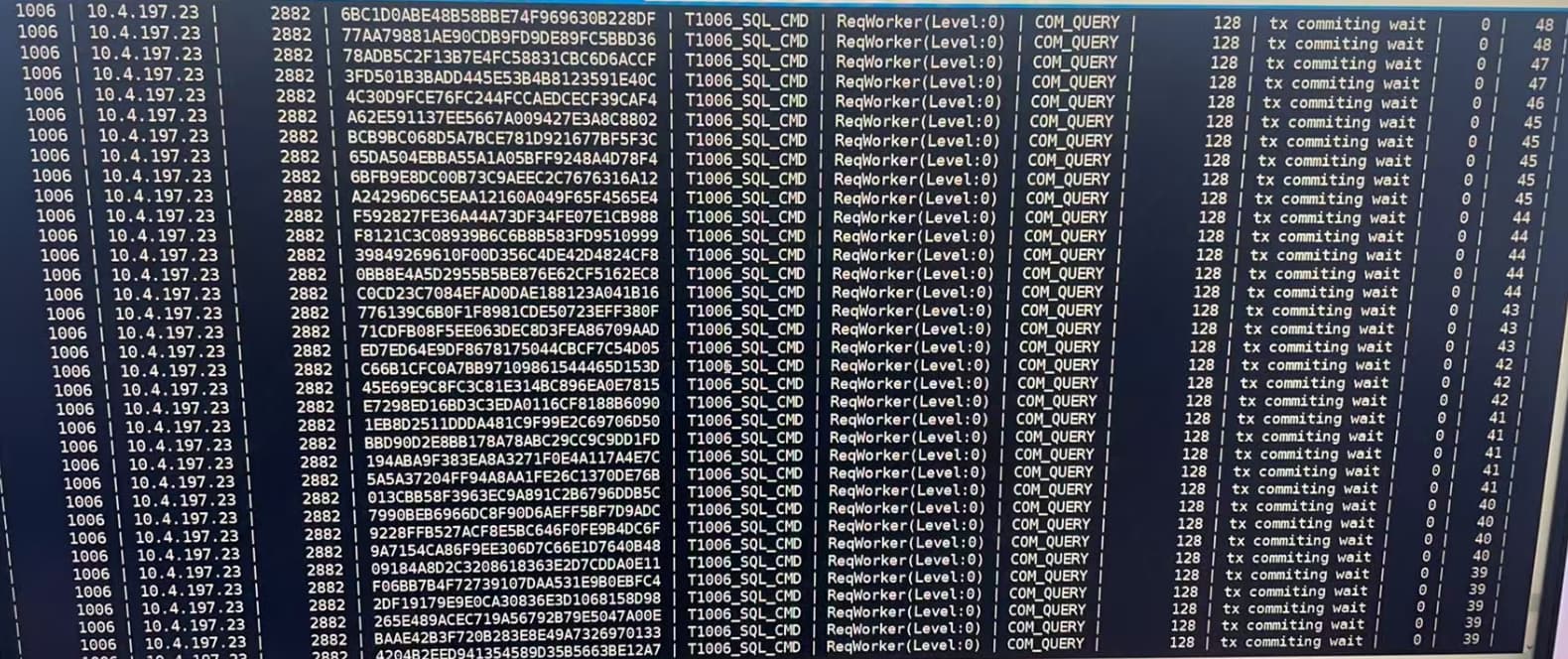
SQL Audit 里看到的是:
sync rpc + NETWORK + 长 WAITED KNOWN TIME,也符合提交/副本或相关同步 RPC 路径变慢的表现
根据语句的trace_id (YB420A04C517-0006509CA42A9443-0-0
YB420A04C517-0006509CE2E88301-0-0
YB420A04C515-0006508CC1485C52-0-0
YB420A04C516-0006509165DE282F-0-0)捞一下observer.log rootservice.log日志信息 再看看
4 个赞
是不是磁盘速度慢呢,磁盘最好用SSD的吧
2 个赞
一个事务批量提交事务,检查下最近批量提交的数据量和原来差距有多少。数据量是不是有很大增长。
2 个赞
建议检查查询计划,查看执行缓慢的INSERT语句的查询计划。可以使用EXPLAIN或EXPLAIN ANALYZE来获取执行计划,这可以帮助你理解数据库是如何处理这个查询的。
1 个赞
学习到了
2 个赞
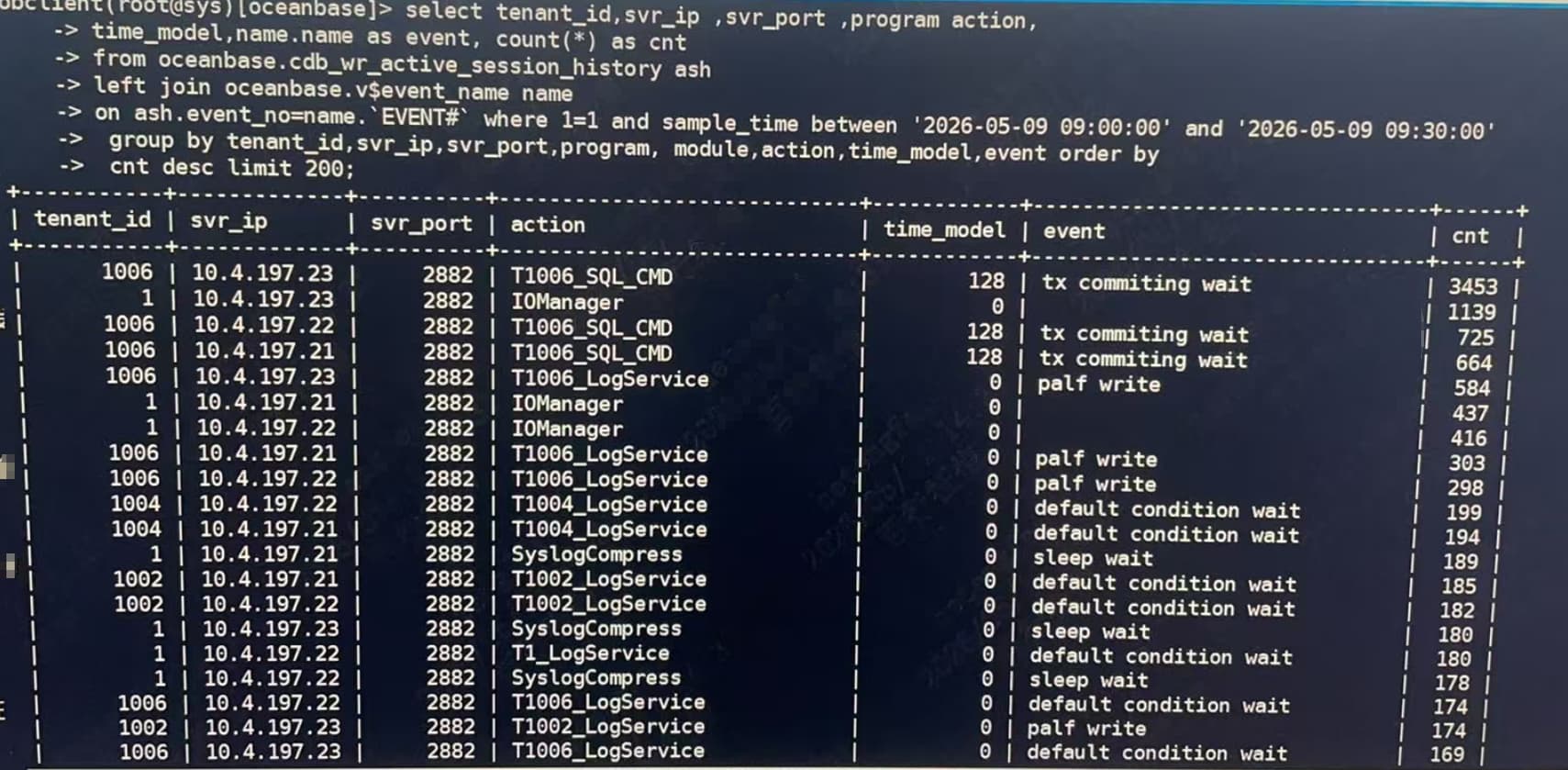
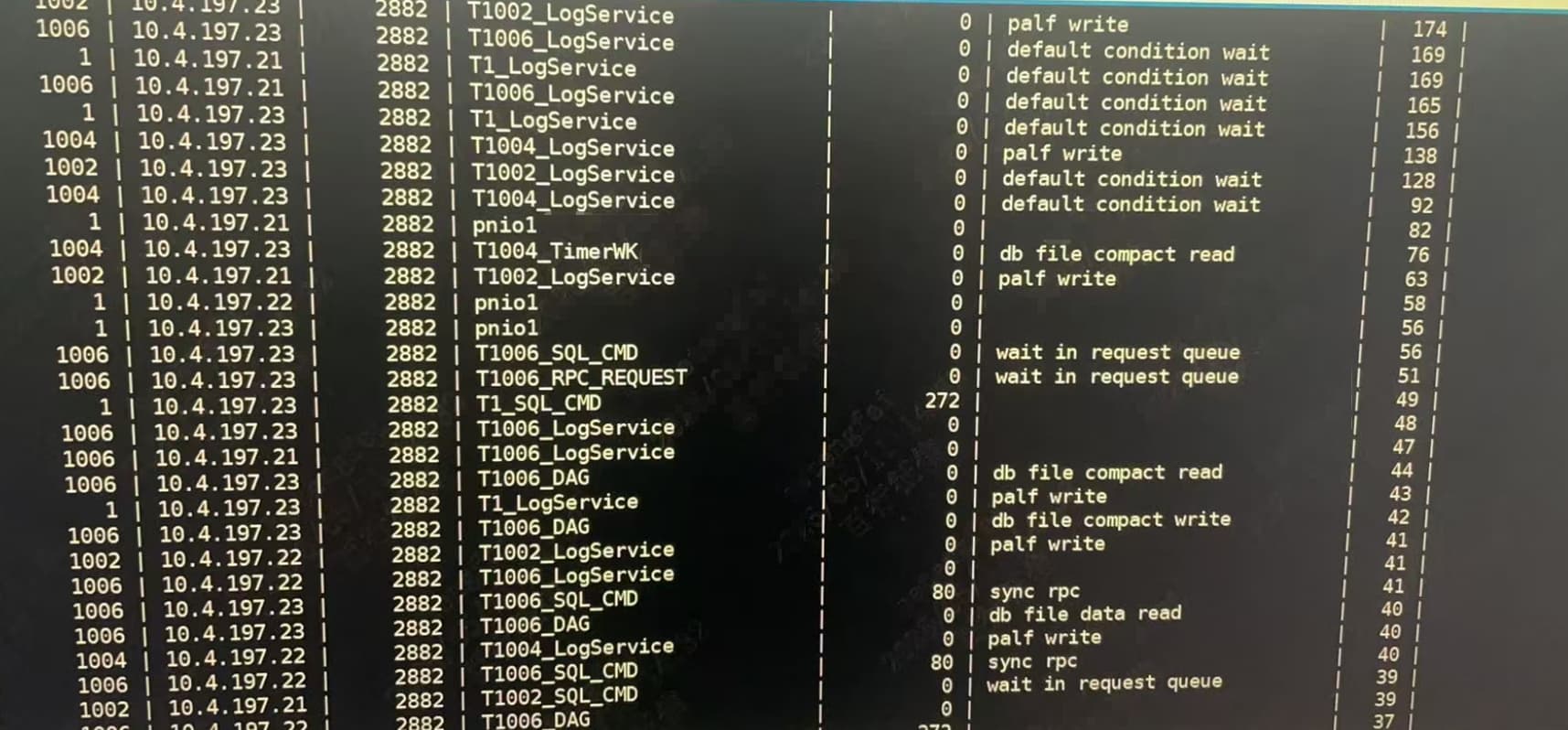
select ash.tenant_id as tenant_id, svr_ip, svr_port, program, module, action, time_model, name.name as event, count(*) as cnt from __all_virtual_wr_active_session_history ash left join v$event_name name on ash.event_no=name.event# where 1=1 and sample_time between ‘2026-05-09 09:00:00’ and ‘2026-05-09 09:30:00’ group by tenant_id, svr_ip, svr_port, program, module, action, time_model, event order by cnt desc limit 200; 查一下 这个信息 看看历史的信息 看看工作的线程状态
__all_virtual_wr_active_session_history 这个表里面是空的
__all_virtual_wr_active_session_history把这个表换成这个视图gv$ob_active_session_history 查一下看看有没有 如果没有数据应该清空了 从这个视图在查看一下CDB_WR_ACTIVE_SESSION_HISTORY
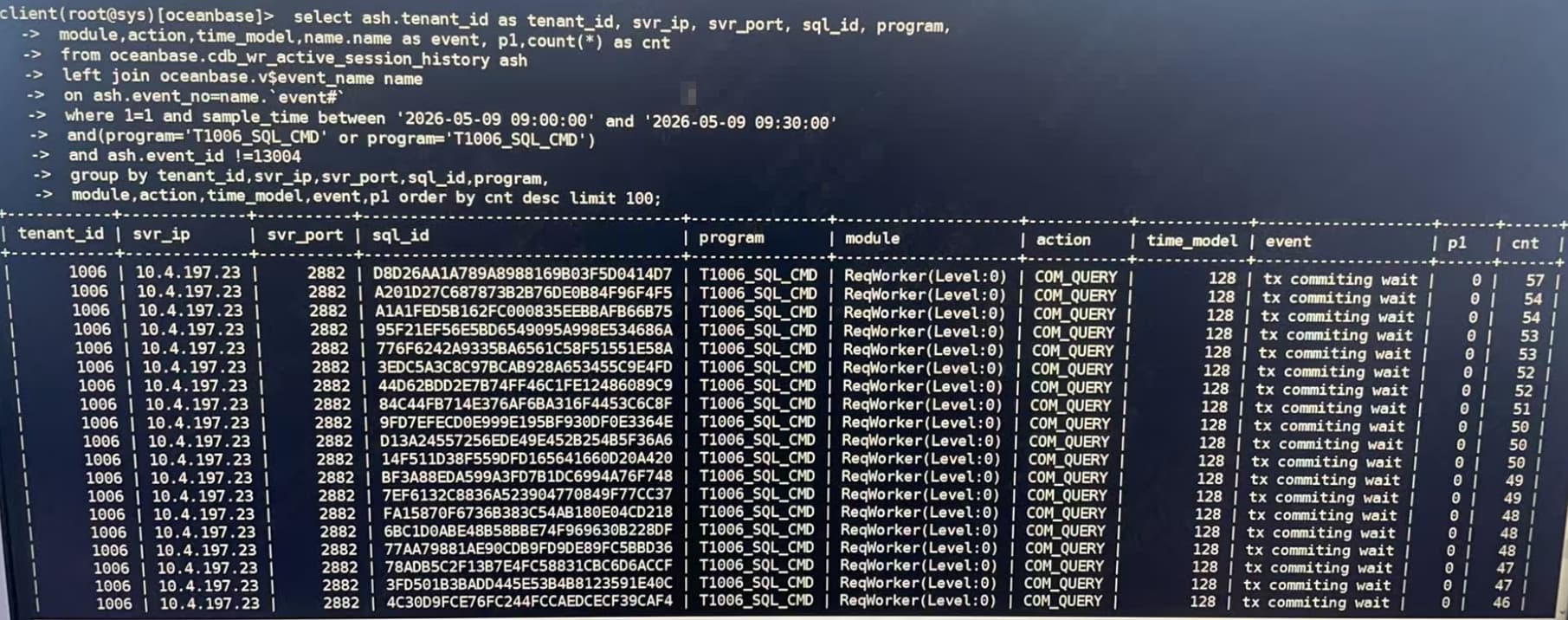
select ash.tenant_id as tenant_id, svr_ip, svr_port, sql_id, program, module, action, time_model, name.name as event, p1, count(*) as cnt from oceanbase.CDB_WR_ACTIVE_SESSION_HISTORY ash left join oceanbase.v$event_name name on ash.event_no=name.event# where 1=1 and sample_time between ‘2026-05-09 09:00:00’ and ‘2026-05-09 09:30:00’ and (program =‘T1006_SQL_CMD’ or program=‘T1006_SQL_CMD’) and ash.event_id!=13004 group by tenant_id, svr_ip, svr_port, sql_id, program, module, action, time_model, event, p1 order by cnt desc limit 100;
这个信息 在查一下
2026-05-09 09:00:00 - 2026-05-09 09:30:00这个时间的监控也看一下
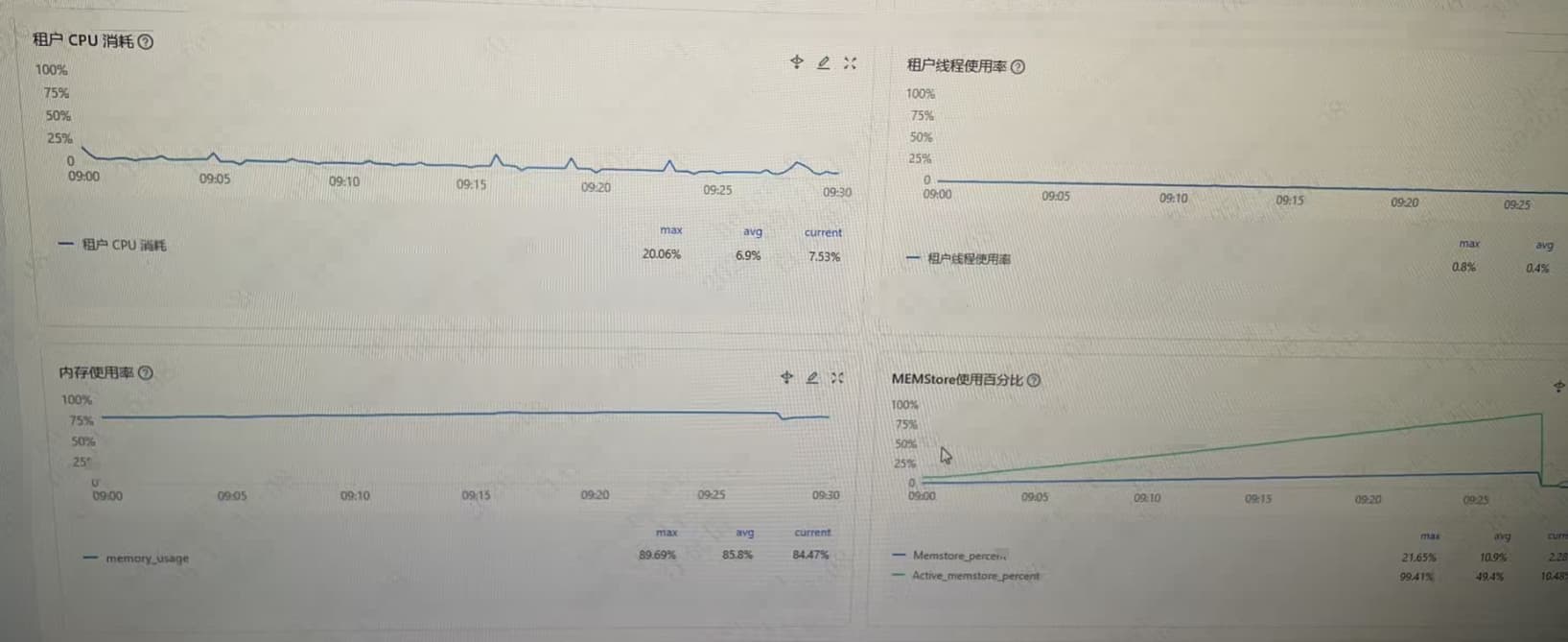
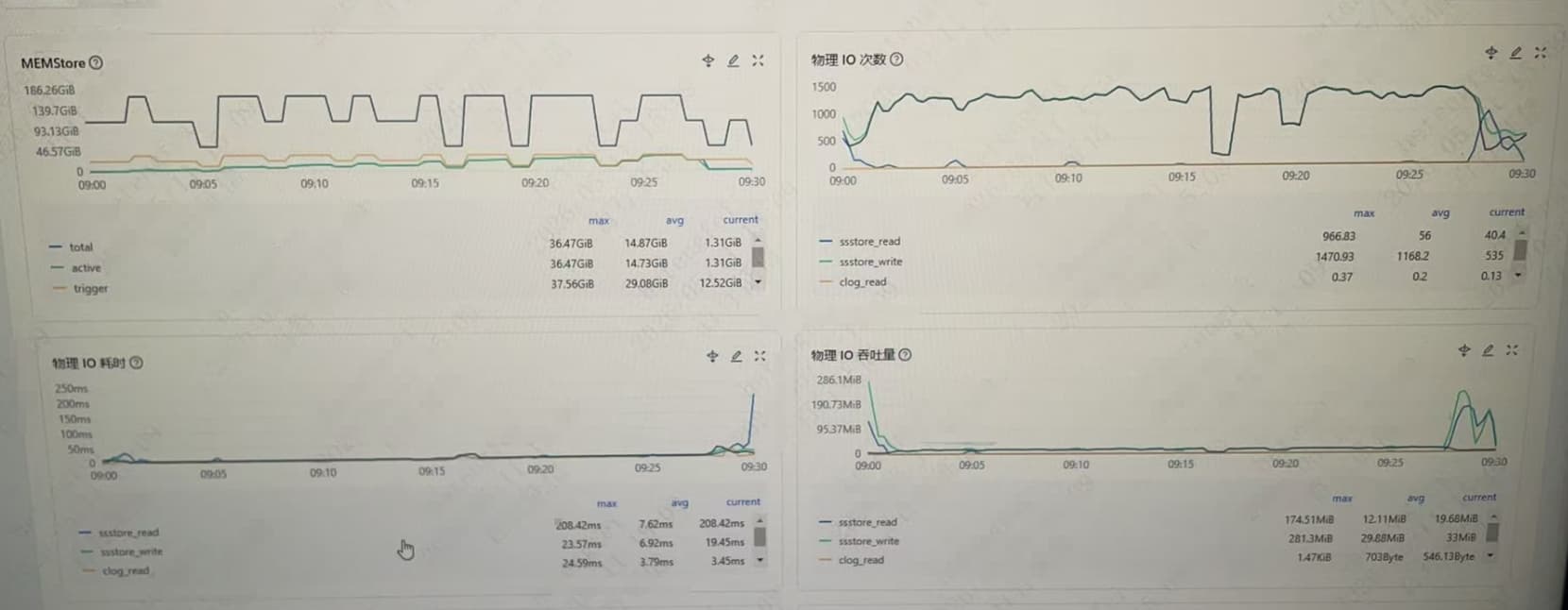
1、在ocp 租户–> 性能监控–>存储与缓存 物理 IO 次数,物理IO吞吐量,物理IO耗时
2、在ocp 租户–> 性能监控–>性能与SQL 看下 租户 CPU 消耗,内存使用率
如果还有日志的话 了可以提供一下 那个时间段的lobserver.log rootservice.log
日志已经没有了
看了信息 从线程的状态信息来看 应该不是获取自增列是瓶颈 应该是和转储有关系 提交等待是拉长 MemStore 触顶与转储节奏应该跟不上INSERT 速率
从图中看着是:若写入速率 ≥ 转储能跟上的速度,就会出现 反复逼近 Active 上限 → 写停顿 → commit 变慢的循环
默认是compaction_high_thread_score=0 应该是6个 因为没有日志信息了 没有办法进一步确定是否是转储慢的问题 你们使用的是机械盘吧
建议compaction_high_thread_score 从 0 调到 8-10,freeze_trigger_percentage 从 30 调回 20,先看看效果。