

【 使用环境 】生产环境
【 OB or 其他组件 】OB
【 使用版本 】4.3.5
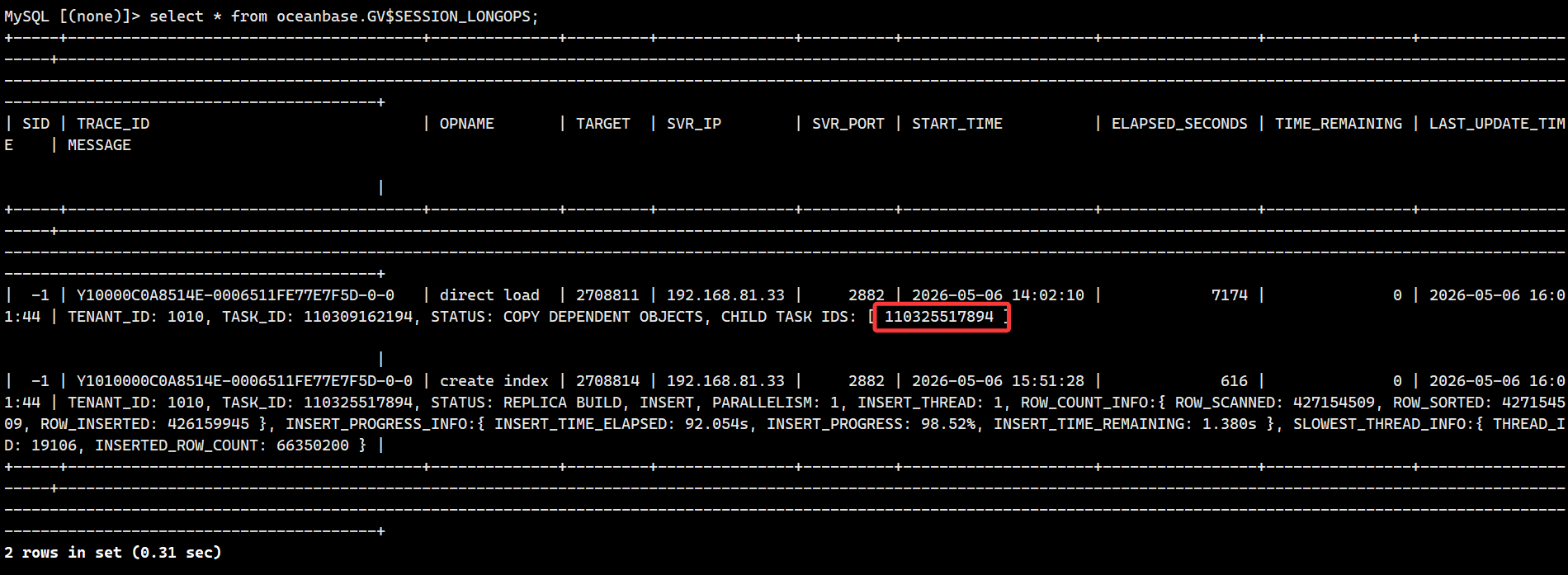
【问题描述】OB旁路导入,在数据写入以后的创建索引阶段,观察GV$SESSION_LONGOPS表发现索引是一个个串行创建的,这个在设计上有什么深意吗,为什么不能并行做节约点时间呢 ![]()
6 个赞
你使用ob的旁路导入的语句 是什么样的 能发一下么?
3 个赞
是用的OMS上面全量导入时候勾选的direct load
4 个赞
这是索引后置和旁路导入的方式没有关系 旁路导入只是写数据的一种方式 这个创建索引的并发 应该和参数有关系
struct.transfer.config 你可以看看这里面的配置参数 默认索引的并发是多少
3 个赞
select * from __all_ddl_operation where ddl_stmt_str like ‘%create index idx on t1%’; 可以根据这个表 查看一下 正在执行的索引 是否加了并发
4 个赞


你使用的oms是哪个版本
2 个赞
4.2.9_CE
2 个赞
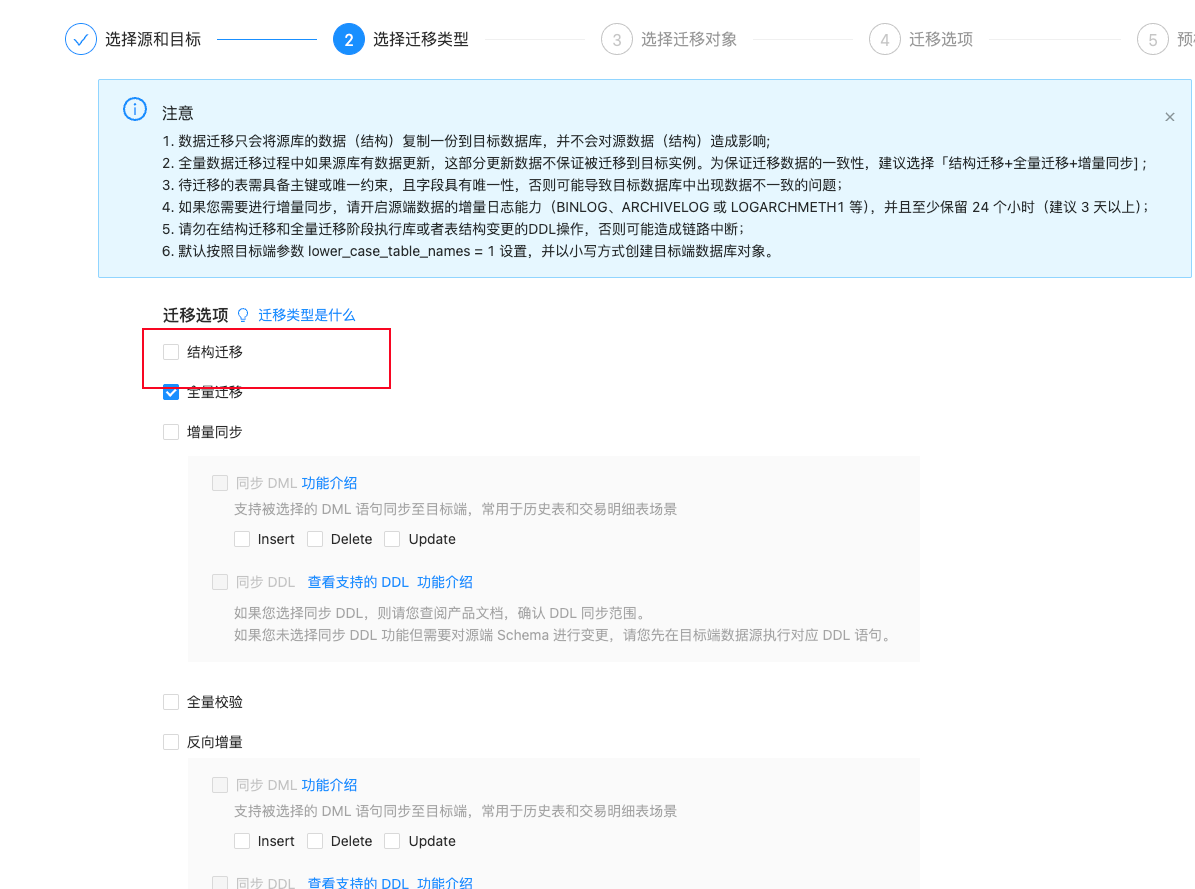
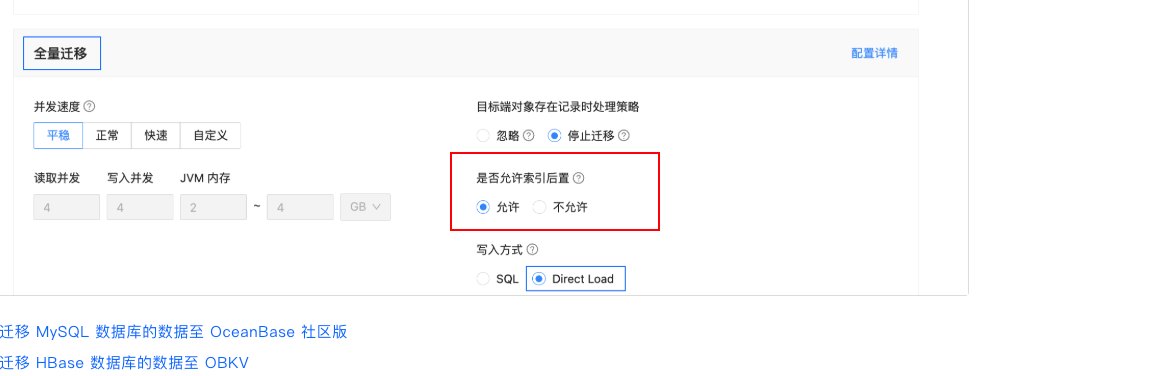
没有,我是提前建好空表然后只选了全量迁移导入的。而且我在空表里有索引的情况下,看这个SESSION_LONGOPS表还是在建索引,所以我猜测旁路导入的原理是交换表名的方式
1 个赞
正常情况下 没有表结构迁移的话 应该不会创建索引的 按照上面发的 截图看看
然而我选的旁路导入确实在SESSION_LONGOPS里看到了建索引的进度,你说的截图是指截什么的图?
1 个赞
我们在看看 可能和旁路导入的处理方式有关系
确实是和旁路导入流程有关系 因为旁路导入也是一种ddl处理。流程大概是会先创建hidden table,用于导入,把原表的数据和新导入的数据合并后写入hidden table中,在hidden table中重建原表的索引和外键,交换原表和hidden table的table_id。之前你的猜测也是有道理的,有点类似在线修改表名一样
好的,那回到一开始的问题,旁路导入在数据导入完,对隐藏表建索引的时候,现在的设计是串行一个个加,这部分在后续版本能不能优化呢?我搞的都几十亿的大表,索引一个个加,每次都全表扫,感觉有很长时间的无意义等待,如果能并行就好了
1 个赞
