

【 使用环境 】生产环境
【 OB or 其他组件 】OB
【 使用版本 】4.3.5
【问题描述】
SELECT COUNT(*) AS par_cnt FROM information_schema.partitions
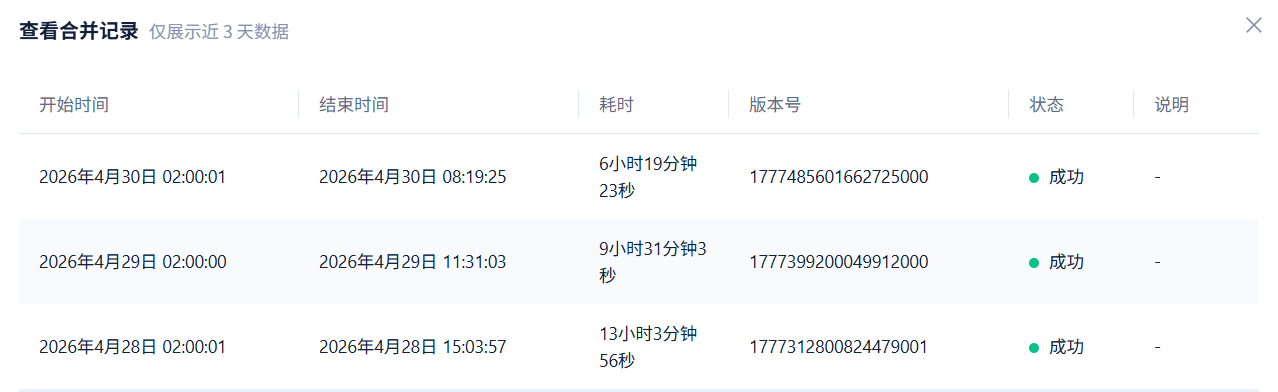
3zone共18台机器(6-6-6)架构的租户里有26w个分区,清理到20w分区以后合并时间从≥10小时缩短到6~8小时,请问后续版本有可能对分区数太多造成的包括合并速度在内的可能的异常情况做优化么
15 个赞
关于OB的讨论很有价值,特别是在分区数显著影响合并速度场景下,合理使用社区问答是关键。
7 个赞
这么多的分区没有碰到过
4 个赞
数据量有多大呢
3 个赞
看一下合并期间这些信息 在ocp 租户–> 性能监控–>存储与缓存 物理 IO 次数,物理IO吞吐量,物理IO耗时
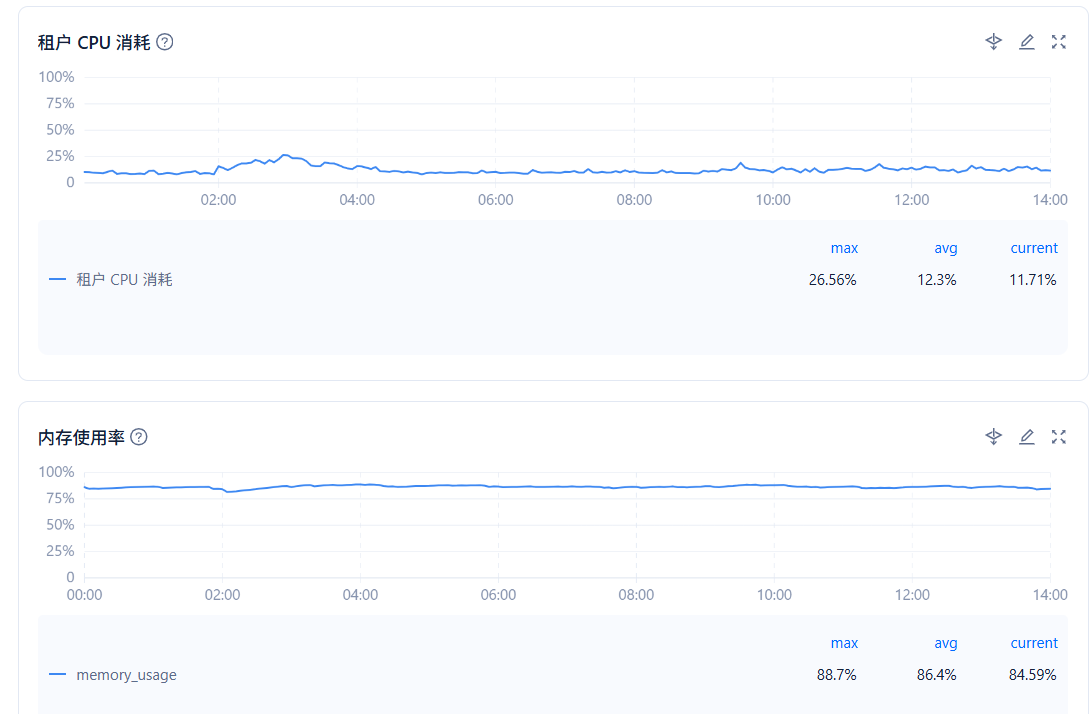
在ocp 租户–> 性能监控–>性能与SQL 看下 租户 CPU 消耗,内存使用率
你们的磁盘是机械盘还是SSD盘
4 个赞
![]()
![]()
![]()
4 个赞
围观
4 个赞
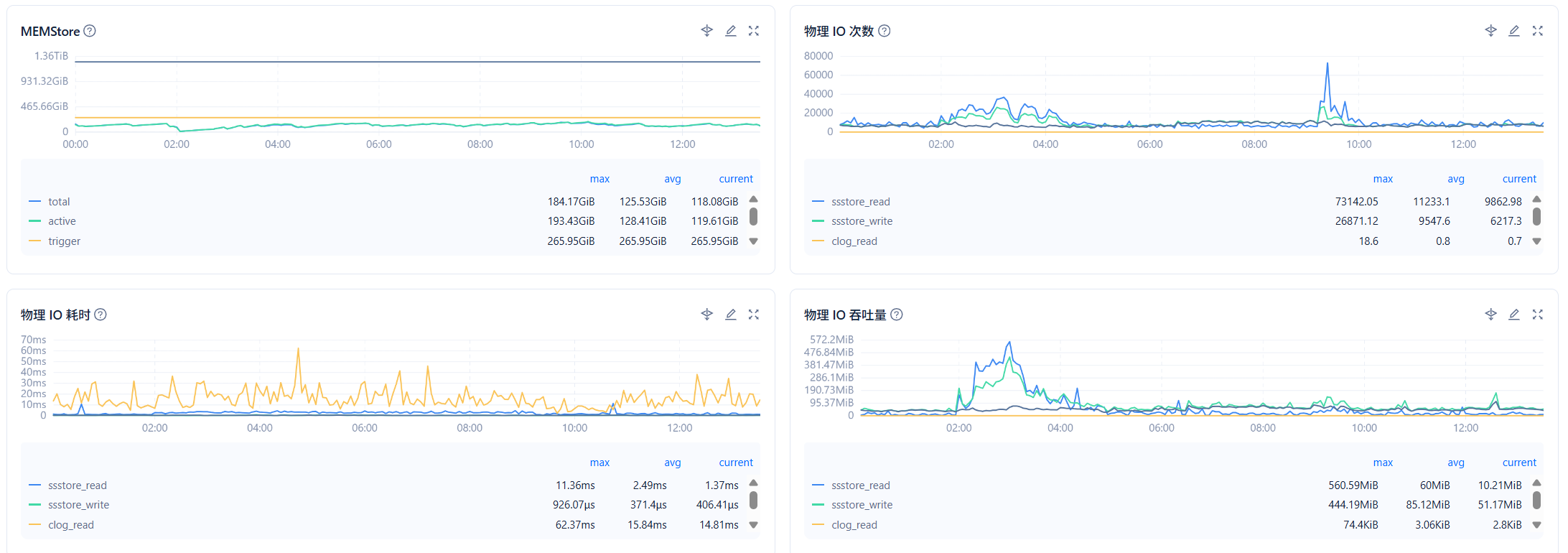
应该是机械盘,如果是ssd的话应该也就是会相对快吧,比如ssd的26w分区要2小时,20w分区要1.5小时之类的,想关注的是随着分区数上升合并速度会迅速变慢这个问题。
分区还在持续清理中,等再转一点成普通表看看合并速度能不能更快
4 个赞
按照这个维度 在截个图看看
在ocp 性能监控–>租户->性能与SQL 看下 租户 CPU 消耗,内存使用率
ocp 性能监控–>集群->主机性能->主机维度 cpu 内存 io等情况
2 个赞
6-6-6的集群架构,26W个分区,这么大,真是少见
3 个赞
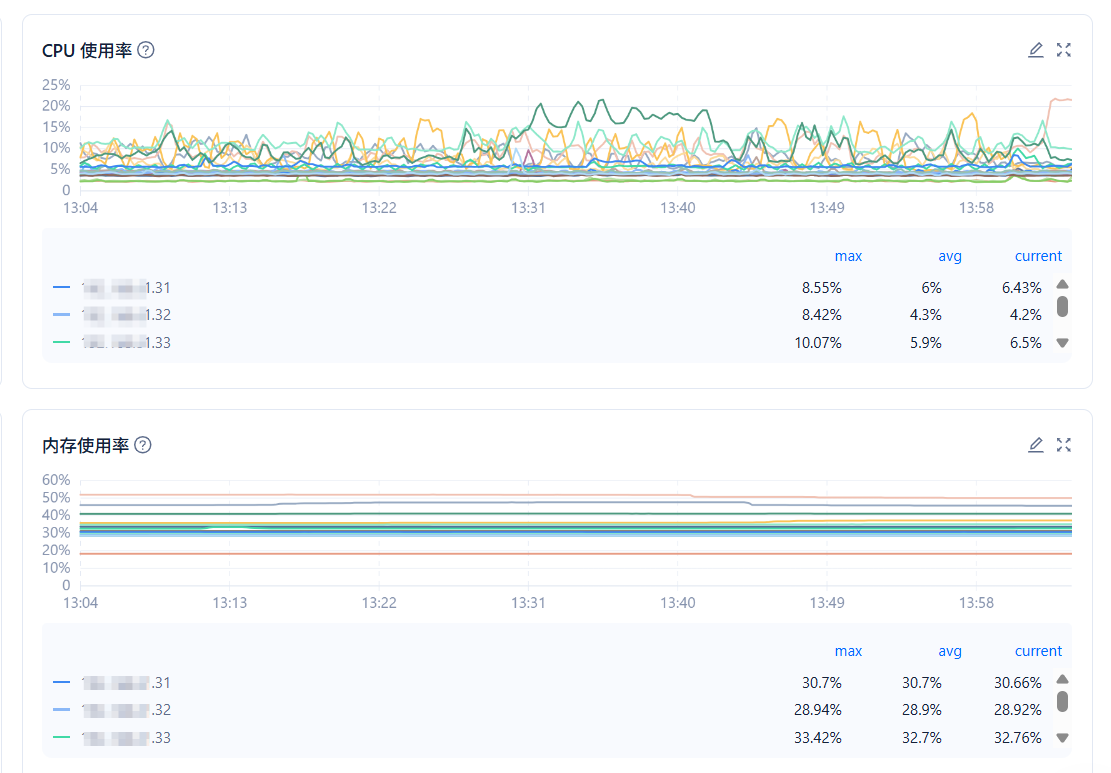
你们clog盘和data盘 是同盘的么?不过看 ssstore 的 读写延迟整体是偏低的,看着clog_read次数很少,但是延迟的波动确实很大。不确定是否有争用,clog读延迟看着有点不合理。
1 个赞
[root@cdh33 data]# df -h | grep data
/dev/sdb 5.5T 5.1T 465G 92% /data/1
/dev/sdc 1.1T 1.1T 93G 92% /data/log1
[root@cdh33 data]# lsblk | grep data
sdb 8:16 0 5.5T 0 disk /data/1
sdc 8:32 0 1.1T 0 disk /data/log1
不是同盘的, 延迟可能是因为这集群下面机器太多了?8-8-8的架构,这个租户用了6-6-6,然后是归档用途的,写的也很猛,再加上不是ssd盘
1 个赞
1、等合并慢的时候 可以查看一下信息 看看那些tablet合并慢
- 找到未合并完成的租户id
select * from CDB_OB_MAJOR_COMPACTION where STATUS != ‘IDLE’; - 查询server级别进度表,看有多少分区没有合并完成
select * from __all_virtual_server_compaction_progress where tenant_id = xxx; - 看分区级别进度表,可以找到没有合并完成的分区及TRACE_ID
select * from __all_virtual_tablet_compaction_progress where tenant_id = xxx; - 通过sstable信息表可以看到SSTable的数据量和数据分布
select * from GV$OB_SSTABLES where tenant_id = xxx and tablet_id = xxx and svr_ip = ‘xxx’;
2、不过从合并期间的cpu使用率来看 可以适当增加Major 相关并发 可以调整到8-10
compaction_low_thread_score
2 个赞
我是正在做把分区表改造成单表这件事,包括rs节点的ocp_agent因为分区太多时不时的会oom的问题也要解决,然后解决过程中发现合并速度显著提升。
目前倒是也不太关注合并到底用了多久,只是从这个现象提出一个疑问,现在看下来明显分区数多的话就会出现合并速度慢的问题,这个问题在设计上能否有优化空间,之后的版本有无可能优化
26 万分区意味着巨量 Tablet,Major Compaction 要覆盖的调度单元非常多,元数据、队列和 IO 都会被放大,又加上你使用的机械盘,如果是ssd盘会更好些, 不过合并小表 / 降低分区粒度确实可以减少合并的时间。
学一下
学到了。
学习~~~
1 个赞
学习~~~