【 使用环境 】生产环境 or 测试环境
测试
【 OB or 其他组件 】
OB
【 使用版本 】
4.3.5.2
【问题描述】清晰明确描述问题
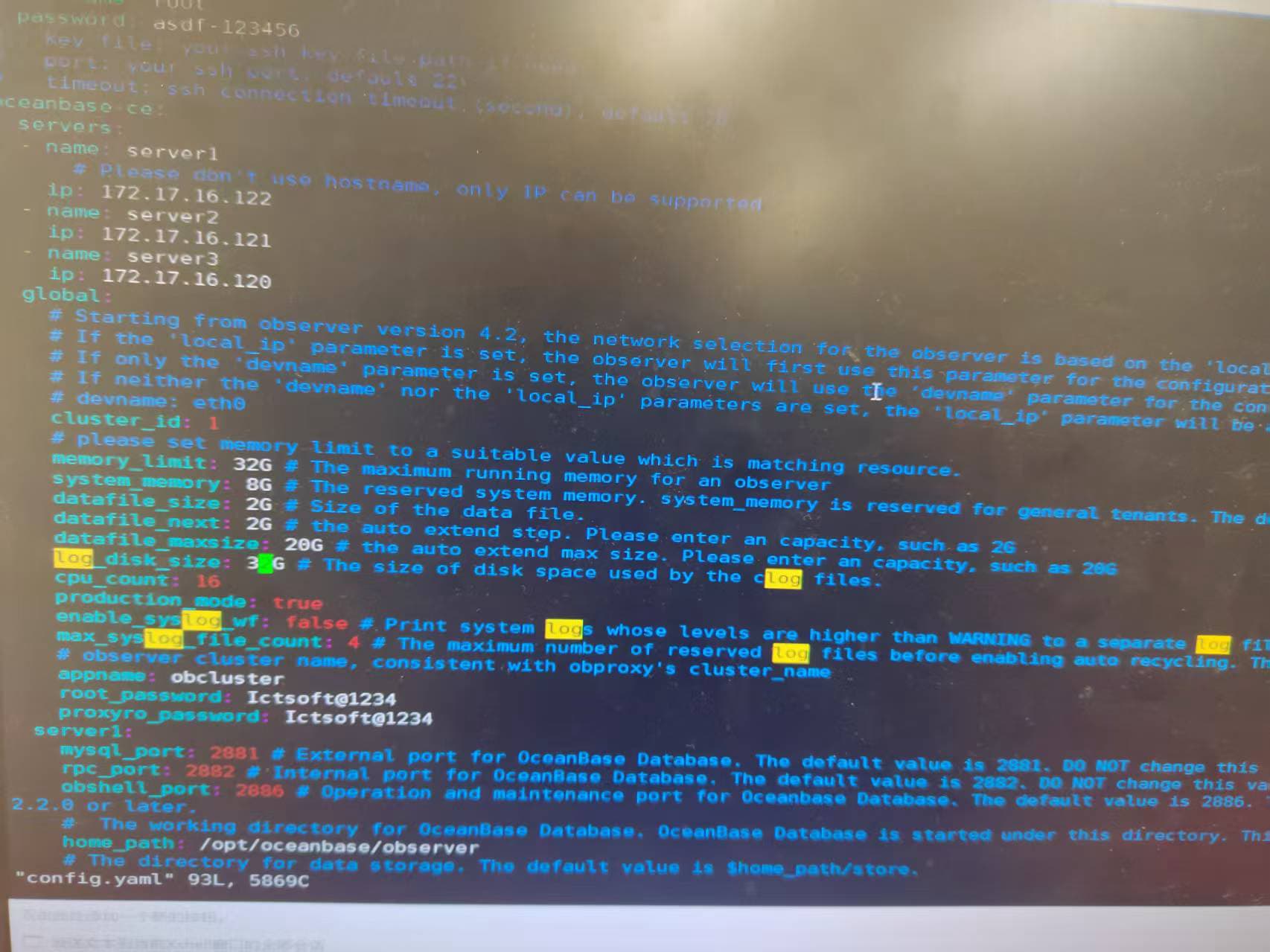
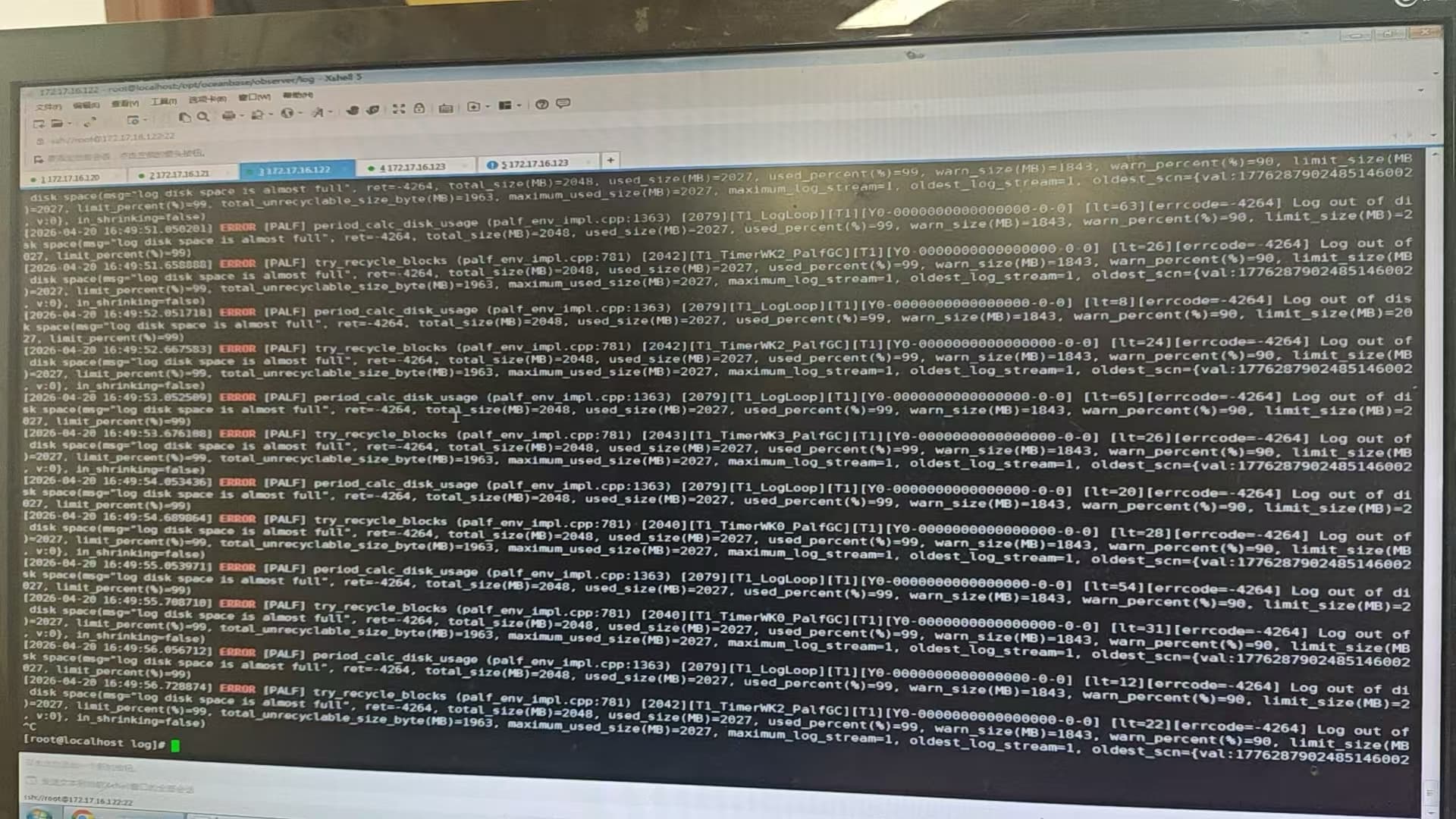
clog磁盘空间满了导致集群无法启动
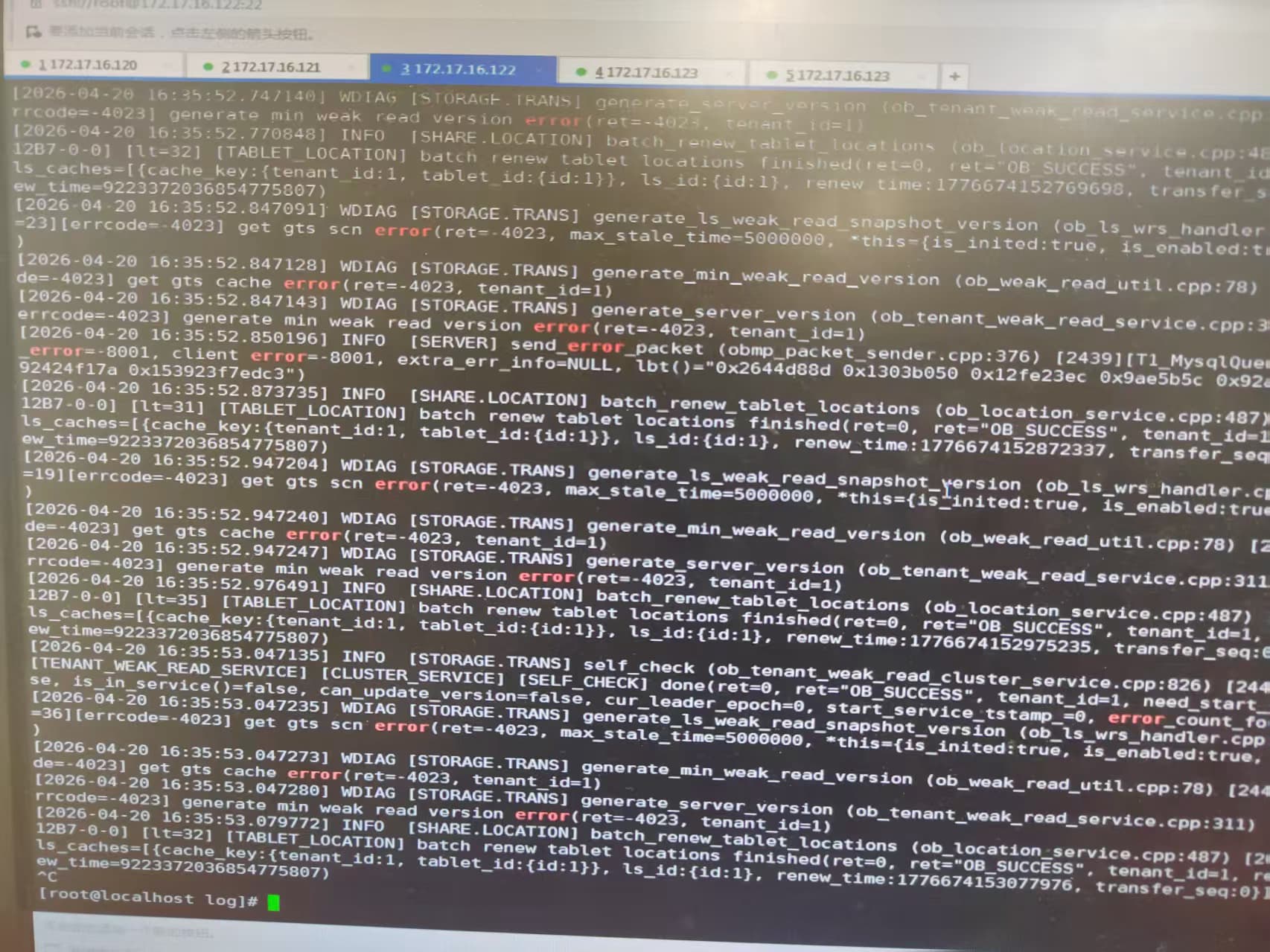
【复现路径】问题出现前后相关操作
【附件及日志】推荐使用OceanBase敏捷诊断工具obdiag收集诊断信息,详情参见链接(右键跳转查看):
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手] 即可召唤小助手,欢迎试用!
【 使用环境 】生产环境 or 测试环境
测试
【 OB or 其他组件 】
OB
【 使用版本 】
4.3.5.2
【问题描述】清晰明确描述问题
clog磁盘空间满了导致集群无法启动
【复现路径】问题出现前后相关操作
【附件及日志】推荐使用OceanBase敏捷诊断工具obdiag收集诊断信息,详情参见链接(右键跳转查看):
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手] 即可召唤小助手,欢迎试用!
针对您描述的情况,看起来是由于 clog 磁盘空间满了导致的集群启动问题。为了更好地诊断和解决问题,建议您使用 obdiag 工具来收集相关日志信息,这将有助于我们分析并找到解决方案。
日志采集场景: clog盘满
日志采集命令: obdiag gather scene run --scene=observer.clog_disk_full
请您按照上述命令执行日志采集,并将采集到的日志压缩包提供给我们。同时,为了进一步了解情况,请回答以下问题:
附上敏捷诊断工具 obdiag 使用帮助链接
95%就会停止写入,你是不是改过log的最大限制参数了。再改为100%有很大风险了
yaml文件中log盘设置大小为多少
看一下是否有除了log文件外的其它文件
obd版本提供一下
OB-4.3.5.2版本。解压oceanbase-ce-utils-4.3.5.2-102010012025052715.el7.x86_64.rpm后,使用ob_admin修改clog磁盘空间大小后恢复。
操作步骤:
1、手动拉起OB集群
2、ob_admin修改sys租户的clog空间
查看sys租户的clog盘大小
./ob_admin -S …/run/rpc.sock dump_server_usage
修改sys租户的clog盘大小
./ob_admin -S …/run/rpc.sock force_set_sys_tenant_log_disk log_disk_size=4294967296
3、修改后等几分钟,集群恢复正常。
4、修改sys租户clog配置,因为上面的配置修改是临时的
select * from oceanbase.DBA_OB_UNIT_CONFIGS\G
alter resource unit log_disk_size=‘24G’;
学习