【 使用环境 】生产环境
【 OB or 其他组件 】
【 使用版本 】4.2.1.10
【问题描述】
租户并没有增量的写入,但是合并很慢,40万分区耗时7小时
【复现路径】问题出现前后相关操作
1.该租户有40万分区

2.查询到分区的合并历史,4点后分区没有进行操作了,直到8点才进行major merge。

如何排查4点-8点集群在做什么操作,哪里影响了合并的进度
【 使用环境 】生产环境
【 OB or 其他组件 】
【 使用版本 】4.2.1.10
【问题描述】
租户并没有增量的写入,但是合并很慢,40万分区耗时7小时
【复现路径】问题出现前后相关操作
1.该租户有40万分区
如何排查4点-8点集群在做什么操作,哪里影响了合并的进度
SHOW VARIABLES like ‘version_comment’; --具体的版本信息 查一下
以下的信息 查一下
select* from CDB_OB_MAJOR_COMPACTION
select * from __all_virtual_server_compaction_progress where tenant_id = xxx;
select * from __all_virtual_tablet_compaction_progress where tenant_id = xxx;
select * from GV$OB_SSTABLES where tenant_id = xxx and tablet_id = xxx and svr_ip = “xxx”;
学习一下
SELECT * FROM __all_virtual_compaction_diagnose_info
WHERE tenant_id = <tenant_id>; 这个信息 也麻烦查一下
MySQL [oceanbase]> SELECT * FROM __all_virtual_compaction_diagnose_info where tenant_id=1002 limit 1;
Empty set (14.636 sec)
从查看的信息来看 你们的数据量确实挺大的 合并的执行时间确实很长 等待合并调度的时间并不长
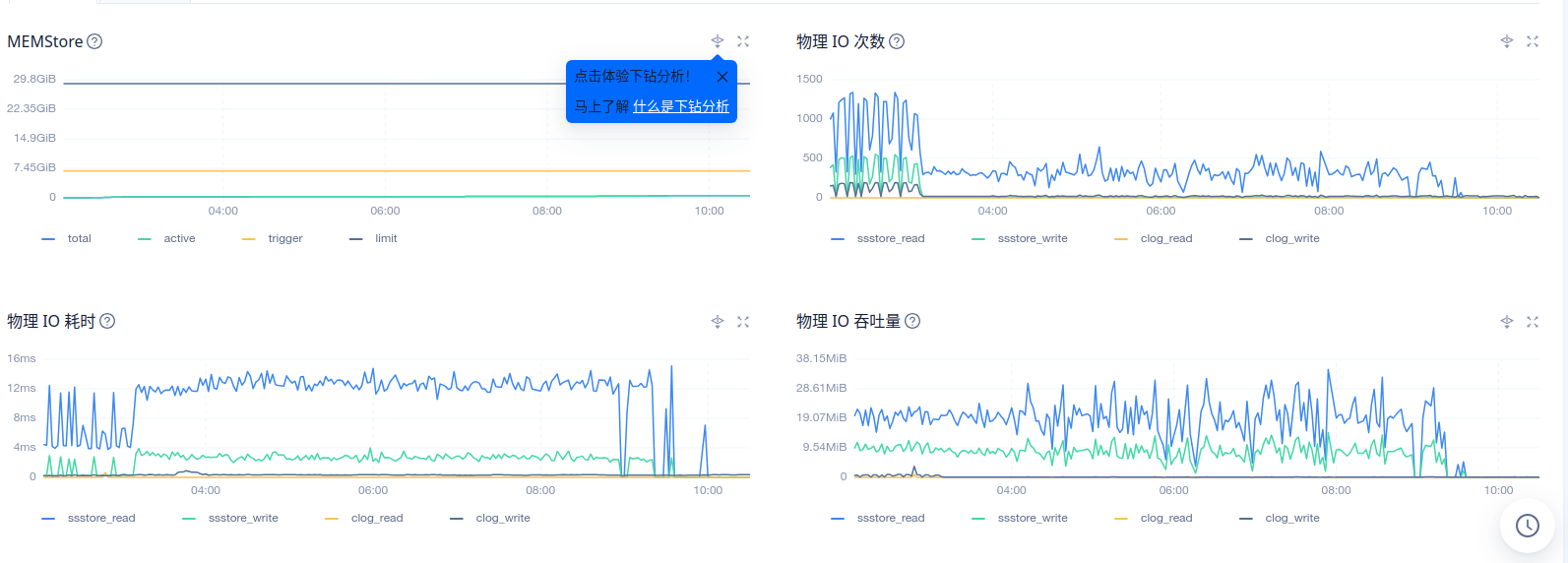
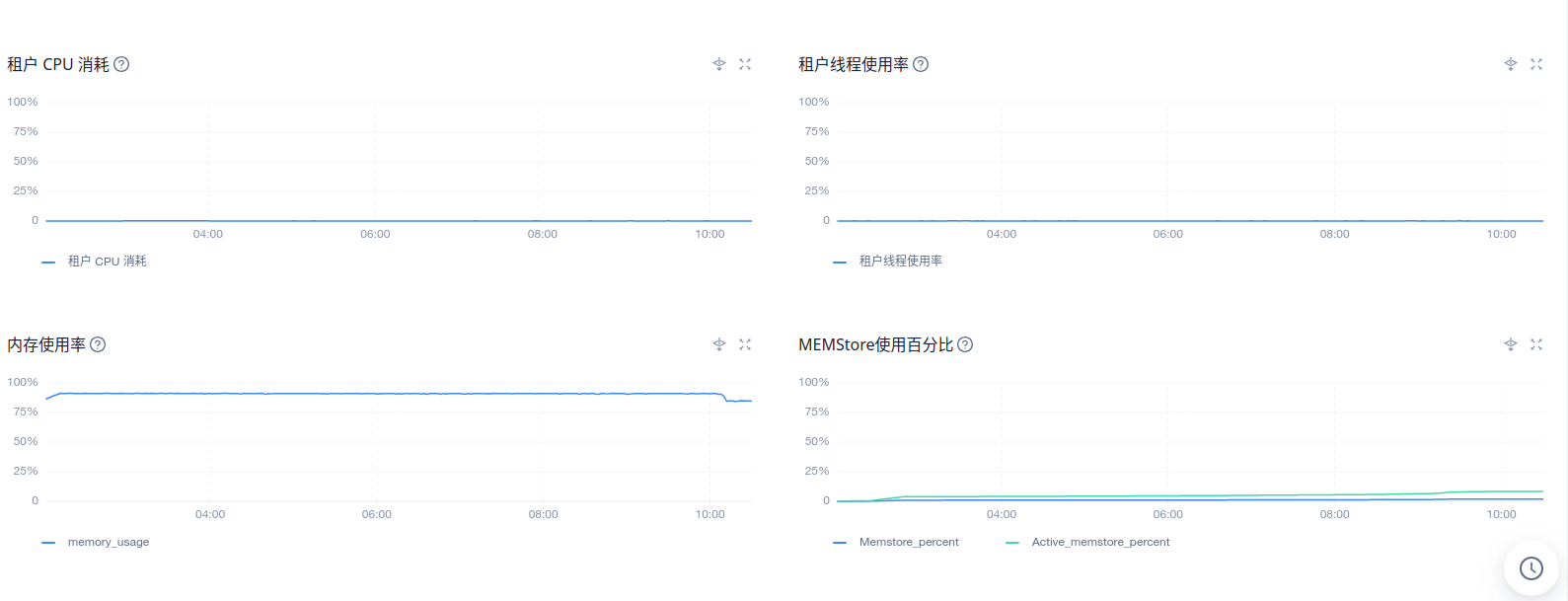
这两个截图看看
1、在ocp 租户–> 性能监控–>存储与缓存 物理 IO 次数,物理IO吞吐量,物理IO耗时
2、在ocp 租户–> 性能监控–>性能与SQL 看下 租户 CPU 消耗,内存使用率
但如果增量数据很少,大部分的宏块都是可以复用的吧,按理说不该那么久。
是的 看着你们的磁盘的物理io耗时挺高的 你们的磁盘是机械盘还是SSD盘呀 你们同盘部署的么?
看着UPDATE_TABLET ~50min 耗时就50min分钟了 可能是 tablet 数多或者是你的磁盘性能差 看着你们的tablet确实不少 还有就是磁盘性能确实不是很好
如果tablet数量过多是在合并的哪个步骤有影响呢,不是直接复用宏块嘛
那应该是磁盘性能问题 你们的磁盘是机械盘还是SSD盘呀 你们同盘部署的么?
数据是单独一块盘,我不太理解,这种情况下是哪个步骤用到了磁盘io啊。如果是重写宏块的话,磁盘io用的挺多吧,我们这基本是静态数据。
你们还有其他的监控么?可以看到服务器磁盘的监控信息 clog盘和data盘 在一起么?
clog和data盘不在一起。 这块磁盘io是什么时候用的可以给讲解下嘛
UPDATE_TABLET 也不小),这些仍是写。宏块复用主要省的是「新宏块写入」;增量合并仍会带来明显的读盘和部分写盘,所以磁盘(尤其是读 IO 和混合负载下)仍可能有压力,只是通常比不做复用、全量重写要轻。
https://www.oceanbase.com/knowledge-base/oceanbase-database-1000000003633625?back=kb
这个是4.x版本 合并慢的一些优化办法 另外就是 建议升级到更高的版本例如LTS425版本
意思是中间几个小时都是在做分片信息的读取,这个工作耗时比较久?
所以说即使没有增量数据产生,还是会从sstable中读信息。应该是以分片为单位进行读取吧,导致读的压力比较大。