

【 使用环境 】生产环境
【 OB or 其他组件 】OCP AGENT
【 使用版本 】4.4.0-20251114143405
【问题描述】集群是个很大的集群, 采集到的监控数据可能比较多, 先是报错max_allowed_packet太小,从16MB调整到64MB以后报第二个错
报错1: ERROR [49270,] caller=resource/resource_trends.go:151:WriteToDb: write resourceTrends data into db failed, err: Error 1153 (08S01): Got a packet bigger than ‘max_allowed_packet’ bytes
报错2: ERROR [49270,] caller=resource/resource_trends.go:151:WriteToDb: write resourceTrends data into db failed, err: Error 1406 (22001): Data too long for column ‘value_compressed_binary’ at row 1
对应表结构
*************************** 1. row ***************************
Table: ob_hist_partition_stats_compressed
Create Table: CREATE TABLE ob_hist_partition_stats_compressed (
cluster_id bigint(20) NOT NULL COMMENT ‘OCP维护的集群ID, FK to ob_cluster.id’,
tenant_name varchar(128) NOT NULL COMMENT ‘租户名称’,
ob_tenant_id bigint(20) NOT NULL COMMENT ‘ob侧租户id’,
timestamp bigint(20) NOT NULL COMMENT ‘指标时间戳,单位(秒)’,
value_compressed_binary mediumblob NOT NULL COMMENT ‘值压缩后的数据(二进制)’,
PRIMARY KEY (cluster_id, tenant_name, ob_tenant_id, timestamp)
) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = ‘zstd_1.3.8’ REPLICA_NUM = 1 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0 COMMENT = ‘OB分区副本历史记录(压缩存储)’
partition by range columns(timestamp)
(partition DUMMY values less than (0),
partition p2023 values less than (1704067200),
partition p2024 values less than (1735689600),
partition p2025 values less than (1767225600),
partition p2026 values less than (1798761600),
partition p2027 values less than (1830297600))
想请问下有人改过这个表到longblob吗,会有什么坑吗,还是直接改就行
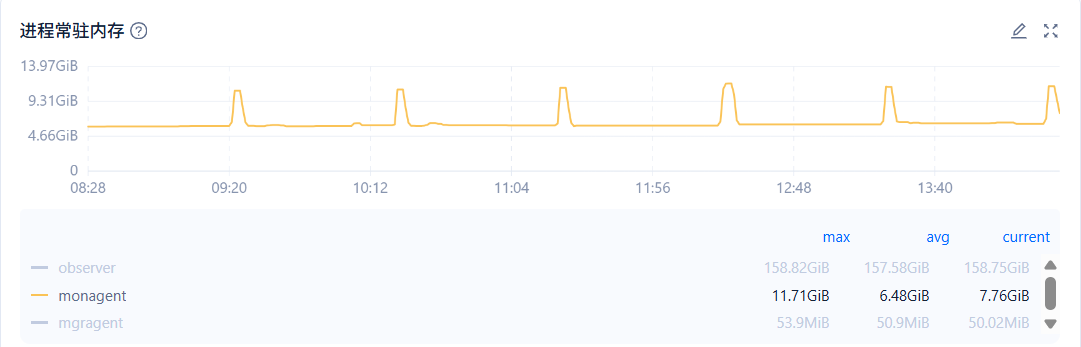
改到longblob之后写入是成功了,但是ocp_monagent进程OOM的情况还是没有缓解,配置的是1C12G差不多每天都要OOM 1~2次,每个小时一次的这个writeToDb会导致内存上升,有什么好办法吗
可以
1.ALTER TABLE your_table_name MODIFY value_compressed_binary LONGBLOB;
2.OOM扩容agent的内存
OOM看下 ocp_monagent.error.log
集群规模多大?sys租户查询下
SELECT count(*),zone FROM oceanbase.CDB_OB_TABLE_LOCATIONS group by zone;
ocp_monagent.error.log里的信息感觉没啥意义,只有这2种日志记录
packets.go:149 write tcp xx.xx.xx.33(OOM的机器ip):25592->xx.xx.xx.138(OCP机器ip):2883: write: broken pipe
connection.go:706 closing bad idle connection: EOF
我OOM是在dmesg -T里看到的
dmesg -T | grep -i ‘kill’
[Thu Mar 26 14:12:34 2026] ocp_monagent invoked oom-killer: gfp_mask=0x14000c0(GFP_KERNEL), nodemask=(null), order=0, oom_score_adj=0
集群规模:
MySQL [(none)]> SELECT count(),zone FROM oceanbase.CDB_OB_TABLE_LOCATIONS group by zone;
±---------±------+
| count() | zone |
±---------±------+
| 1344142 | zone1 |
| 1344142 | zone2 |
| 1344142 | zone3 |
±---------±------+
3 rows in set (17.59 sec)
ocp_monagent.error.log有 panic相关的信息吗?
cat ${ocp.agent.home.path}/log/ocp_monagent.error.log | grep -80 panic || true
另外看下OOM时monagent.log的信息
怀疑是集群分区数过多导致agent频繁OOM,可以参考这个验证下,需要采集agent内存占用高时的 agent goroutine信息,分析哪个模块占用的内存高
MON_PID=$(cat /home/admin/ocp_agent/run/ocp_monagent.pid)
curl --unix-socket /home/admin/ocp_agent/run/ocp_monagent.$MON_PID.sock http://unix-socket-server/debug/pprof/heap --output /tmp/heap.pb.gz
go tool pprof -http=127.0.0.1:8081 heap.pb.gz
https://www.oceanbase.com/knowledge-base/ocp-ee-1000000003250251?back=kb
OCP V4.4.0 BP3
- 新增物化视图分析能力。针对定期刷新的物化视图,新增白屏页面展示此类物化视图的刷新状态分析,包含刷新耗时、延迟等内容。
- 优化 Cgroup 配置逻辑,确保 Cgroup 的稳定运行,并在异常情况下增强告警提示能力。
- 支持集群升级过程中的自适应合并状态控制(
_enable_adaptive_compaction),在升级时自动关闭,升级完成后自动恢复
升级能不能解决这个OOM的问题?还是只是说能打印出更详细的告警信息,现在是4.4.0 BP1版本
errorlog里没有panic信息
我也怀疑是分区数过多导致的,一开始以为是写入问题,因为看到有写入报错了,但解决了写入问题还是内存有尖峰,我用这个heap抓一下试试
File: ocp_monagent
Build ID: 07e29dd12a71a0c139ea117bb7efd4227594c985
Type: inuse_space
Time: 2026-03-27 08:23:32 UTC
Showing nodes accounting for 5.66GB, 96.28% of 5.88GB total
Dropped 401 nodes (cum <= 0.03GB)
flat flat% sum% cum cum%
3.08GB 52.35% 52.35% 5.35GB 91.06% github.com/oceanbase/obagent/monitor/plugins/inputs/mysql.(*TableInput).collectData
1.39GB 23.61% 75.96% 1.39GB 23.61% github.com/oceanbase/obagent/monitor/message.NewMessageWithTagsFields (inline)
0.36GB 6.05% 82.01% 0.36GB 6.05% fmt.Sprint
0.25GB 4.26% 86.27% 0.25GB 4.26% bytes.growSlice
0.21GB 3.53% 89.80% 0.56GB 9.58% github.com/oceanbase/obagent/lib/converter.ConvertToString
0.13GB 2.28% 92.09% 0.18GB 3.01% github.com/go-sql-driver/mysql.(*textRows).readRow
0.09GB 1.56% 93.65% 0.15GB 2.56% database/sql.convertAssignRows
0.05GB 0.91% 94.55% 0.05GB 0.91% bytes.Clone (inline)
0.04GB 0.73% 95.28% 0.29GB 4.99% github.com/oceanbase/obagent/monitor/plugins/outputs/resource.(*ResourceTrendsOutput).Start
0.04GB 0.72% 96.01% 0.04GB 0.72% github.com/go-sql-driver/mysql.(*mysqlConn).readPacket
0.02GB 0.28% 96.28% 0.05GB 0.83% github.com/oceanbase/obagent/monitor/plugins/inputs/oceanbase.(*ObSqlAudit).parseRawSqlResults
主要消耗确实还是collectData,所以就是分区太多了咯,只能关掉一些采集信息或者调大cgroup的配置?上面看到的升级到4.4.0BP3有用吗?《优化 Cgroup 配置逻辑,确保 Cgroup 的稳定运行,并在异常情况下增强告警提示能力。》
这种情况 关闭分区的磁盘数据采集可解决 或则 减少集群分区数,对于百万级分区磁盘数据采集 目前受限于OCP产品能力 暂时没有更好的解决方案。
好吧,多谢解答了!