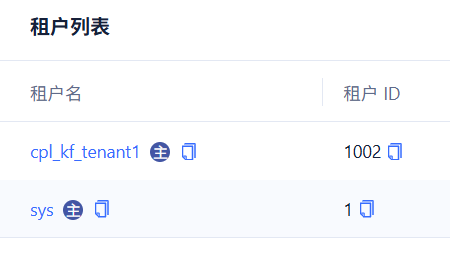
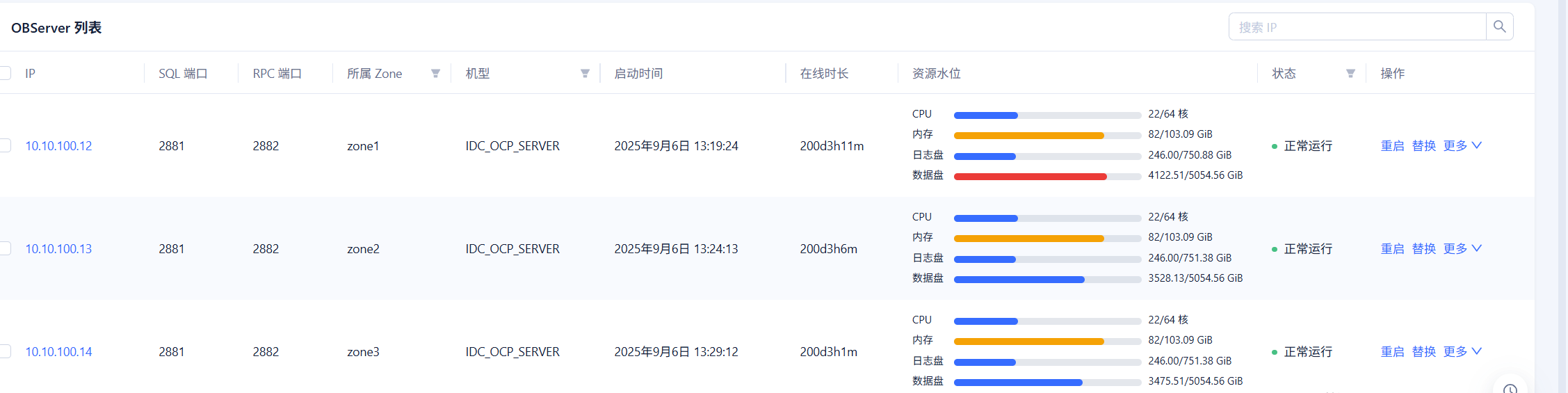
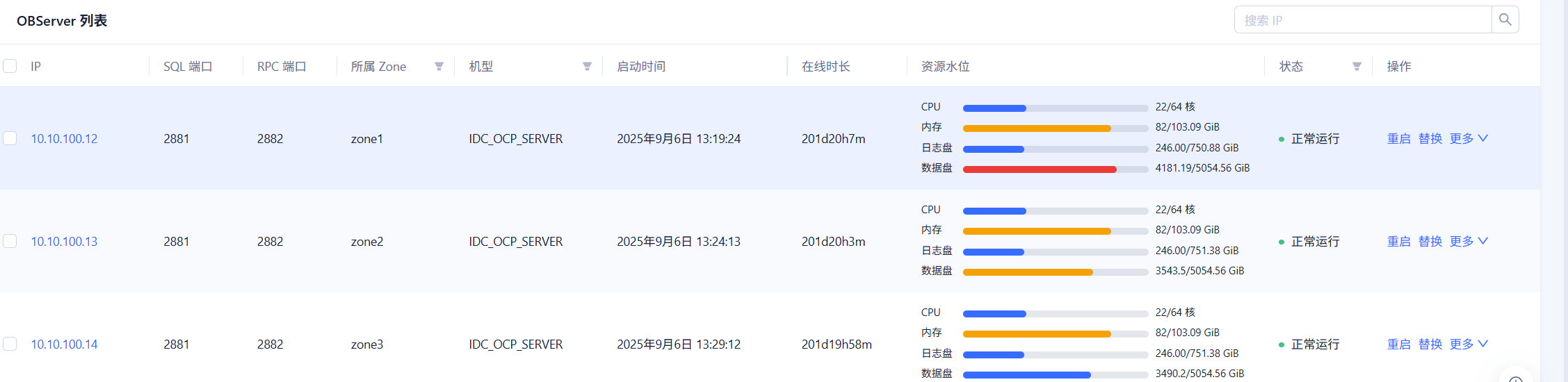
我的版本为OB4.3.5,架构为1-1-1,最近连续观察了一周,我们节点的数据量不均匀,其中10.10.100.12节点比梁歪两个节点数据一直多500多G
10 个赞
根据您的描述,节点10.10.100.12的数据量明显高于其他两个节点。对于1-1-1架构,由于集群规模较小,负载均衡机制可能无法完全消除节点间的数据量不均问题。您可以考虑以下几个解决方案:
- 手动调整Unit分配:检查各节点上的Unit分配情况,如果发现某个节点的Unit过多,可以手动将部分Unit迁移到其他节点。
-
调整负载均衡策略:可以尝试调整负载均衡策略,比如设置
proxy_route_policy为FOLLOWER_FIRST,优先读从节点,减少主节点的压力。 - 定期检查和优化:定期检查集群状态和数据分布情况,及时进行优化和调整。
- 升级集群规模:如果条件允许,可以考虑增加节点,提高集群的负载均衡能力。
更多信息请查看:
- 如何路由到只读型副本查询数据
- 负载均衡
5 个赞
学习打卡
2 个赞
很好的OBServer节点的数据量不均匀分享!在实际项目中,我发现社区问答配合OceanBase社区使用效果更好。
2 个赞
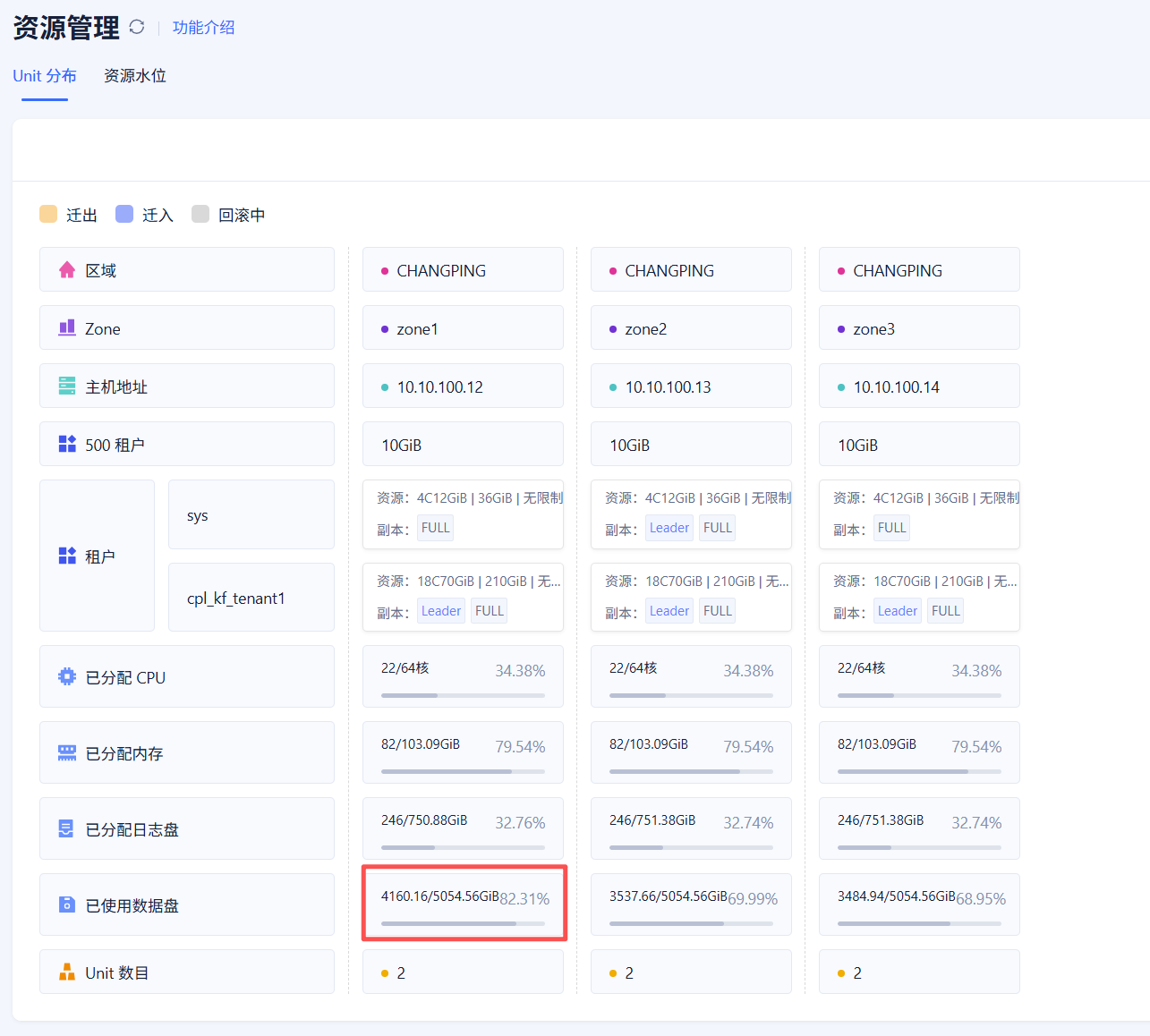
集群–资源管理,具体看下副本分布
2 个赞
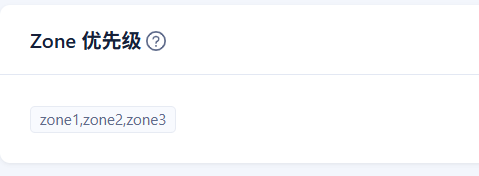
primary zone是3个平均分布吗
1 个赞
是的,3个Zone的优先级是一样的
1 个赞
查询下sys的一号日志流是不是在zone1?
1 个赞
辞霜老师好,这个应该怎么查询呢,给一下示例呢
select * from CDB_OB_LS_LOCATIONS where tenant_id=xxx;
老师您好,目前还是节点数据分布不均,以下为执行结果
select * from oceanbase.CDB_OB_LS_LOCATIONS where tenant_id=‘1002’;
CDB_OB_LS_LOCATIONS.rar (3.1 KB)
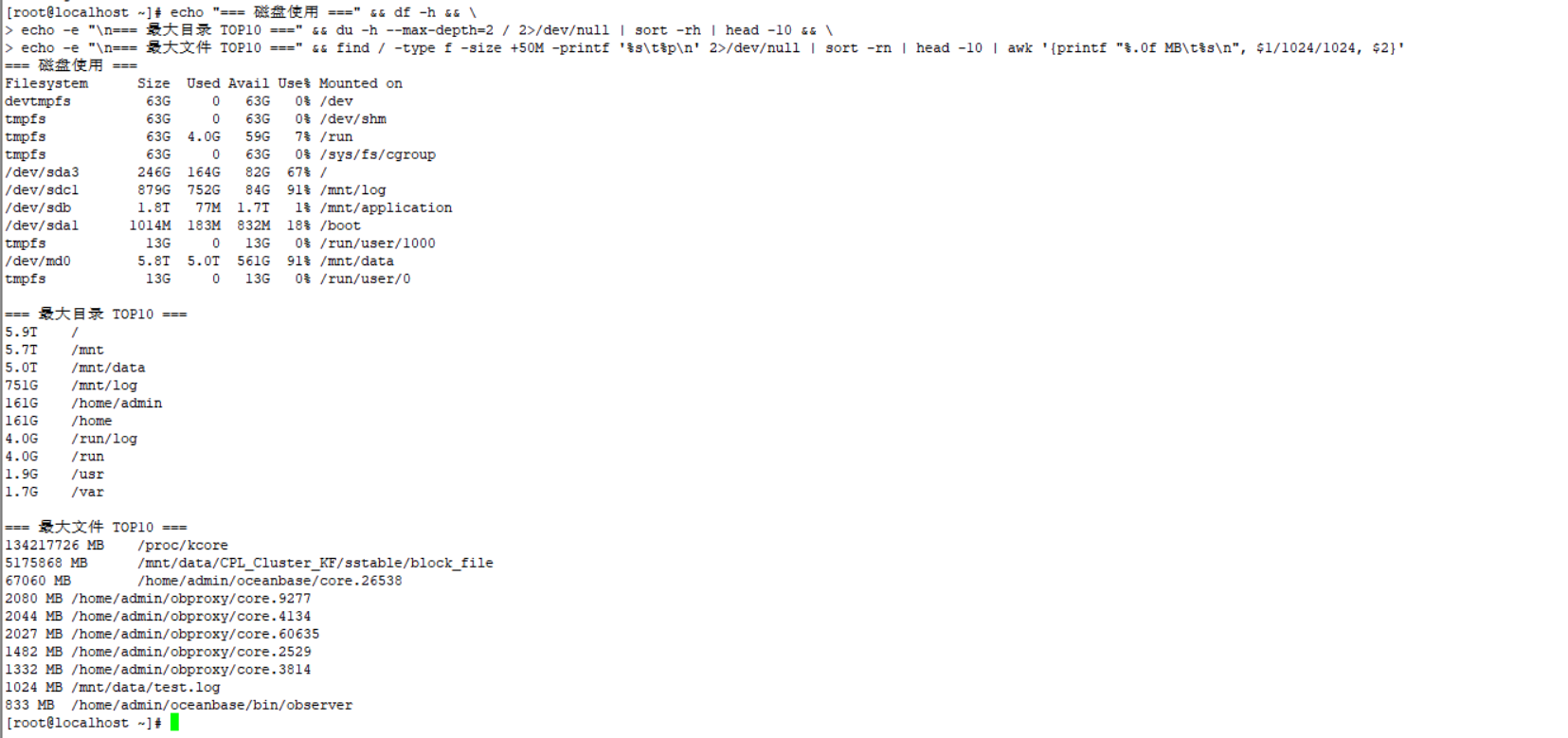
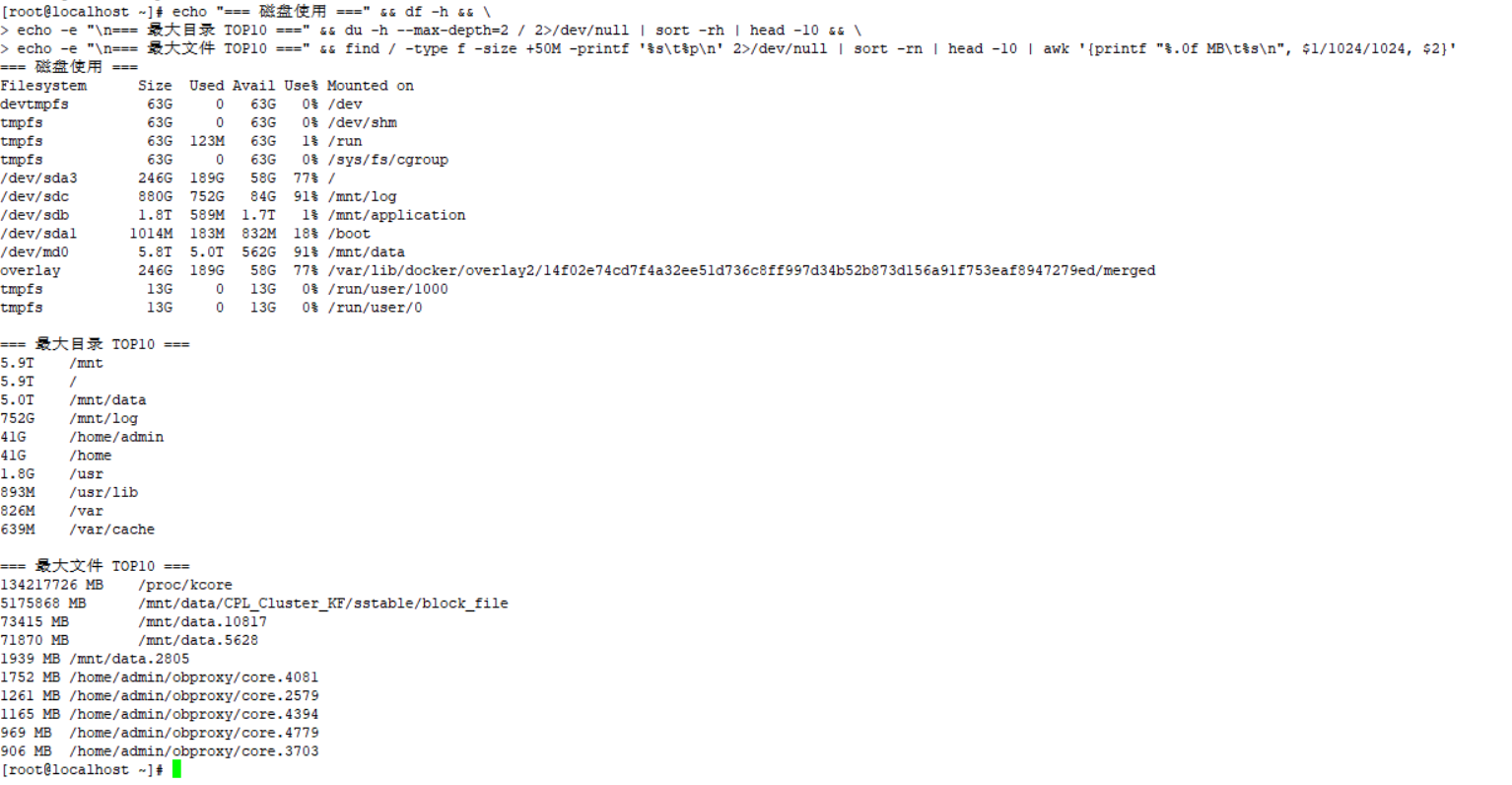
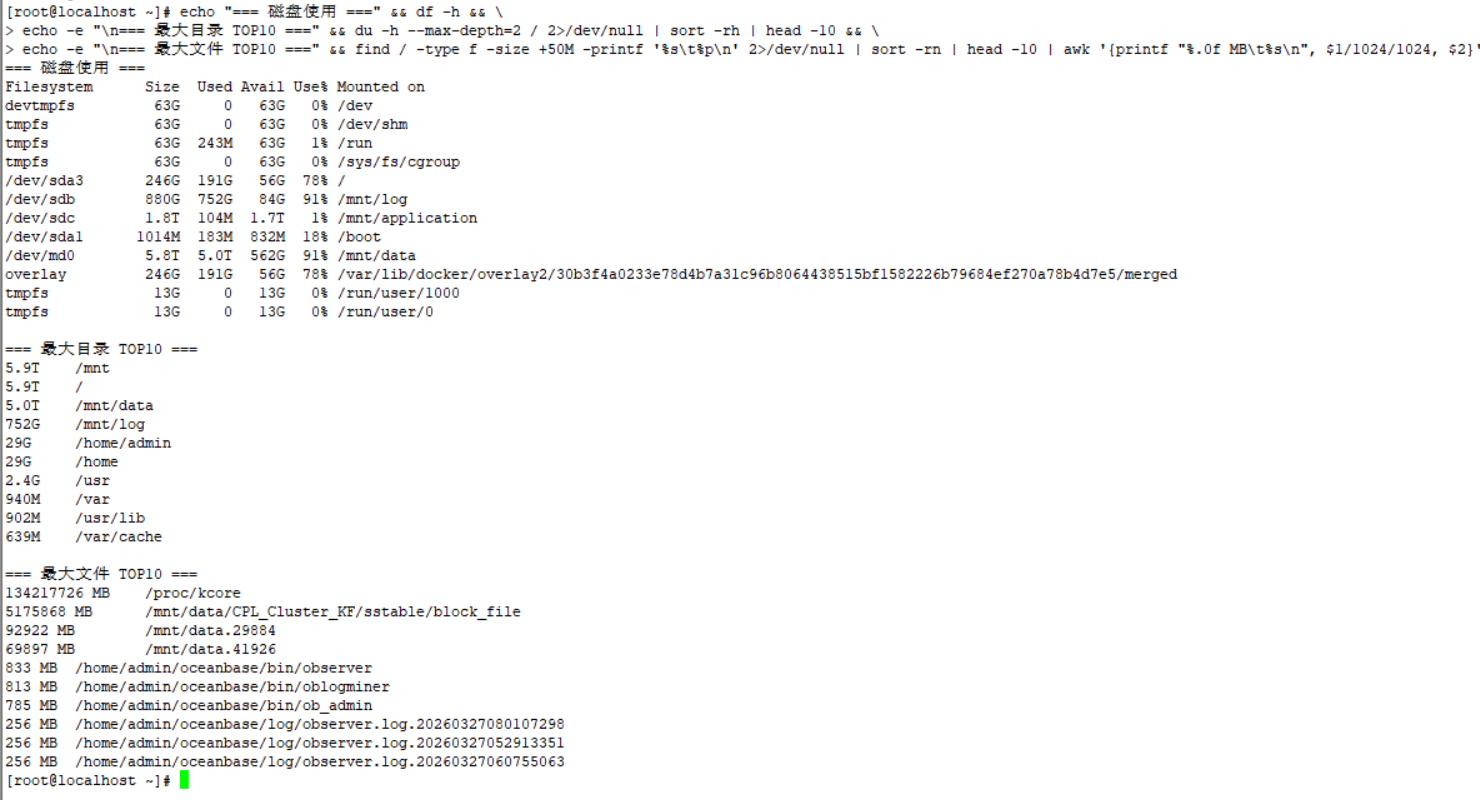
你去操作系统上 df -h 对比下 三个 机器 哪些文件大? 截图发出来
了解下
select * from gv$ob_servers;
select svr_ip,tenant_id,count(TABLET_ID) from CDB_OB_TABLET_REPLICAS group by svr_ip,tenant_id;
select svr_ip,sum(data_size)/1024/1024/1024 from CDB_OB_TABLET_REPLICAS group by svr_ip;
这样查询看下每个节点的分区是否一样大
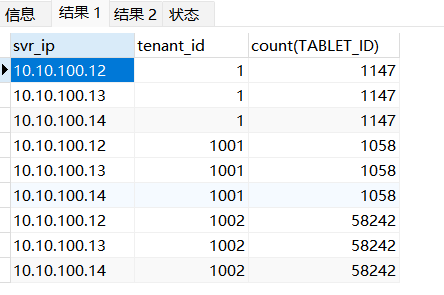
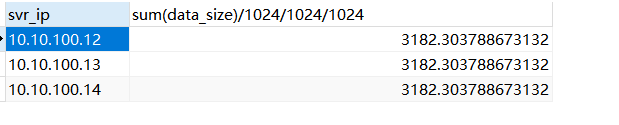
我的业务租户id是1002