

数据库管理-第416期 龙虾的记忆该怎么选?从人脑逻辑看AI Agent记忆体的进化方向(20260324)
作者:胖头鱼的鱼缸(尹海文)
Oracle ACE Pro: Database
PostgreSQL ACE
10年数据库行业经验
拥有OCM 11g/12c/19c、MySQL 8.0 OCP、Exadata、CDP等认证
墨天轮MVP,ITPUB认证专家
圈内拥有“总监”称号,非著名社恐(社交恐怖分子)
公众号:胖头鱼的鱼缸
CSDN:胖头鱼的鱼缸(尹海文)
墨天轮:胖头鱼的鱼缸
ITPUB:yhw1809
IFClub:胖头鱼的鱼缸
除授权转载并标明出处外,均为“非法”抄袭

先叠个甲:本文基于近期使用和研究OpenClaw的实操感触,结合与多位行业前辈的深度交流总结而成,均为个人观点。文章篇幅稍长,若对AI Agent记忆体建设感兴趣,不妨耐心看完,也欢迎三连转发。
开始之前,推荐先阅读此前关于 OpenClaw 的系列文章,能让你对本文内容有更透彻的理解:
数据库管理-第410期 全网疯传的OpenClaw,总监用本地大模型跑通了! (20260314)
数据库管理-第411期 OpenClaw进阶实战:升级+网关安全+飞书对接一次性搞定(20260315)
数据库管理-第412期 OpenClaw深度进化+QClaw实测!这只AI“小龙虾”到底怎么玩透?(20260317)
数据库管理-第413期 OpenClaw深度调 教:上下文管理+Clawhub提速+记忆体实战(20260319)
当下市面上不乏能快速部署、便捷对接IM、预制功能丰富的“类龙虾”AI平台,为何我仍愿意从头安装、一步步探索OpenClaw?核心原因很简单:即便我并非专业开发人员,也希望深度拆解OpenClaw的底层运行机制,尤其是记忆体的设计与实现逻辑。毕竟记忆是AI Agent的核心能力,就像人脑的记忆系统支撑着思考、决策与学习,AI Agent的记忆体直接决定了其智能表现的上限。
在之前的文章中我们提过,OpenClaw默认以md文件的形式记录记忆:
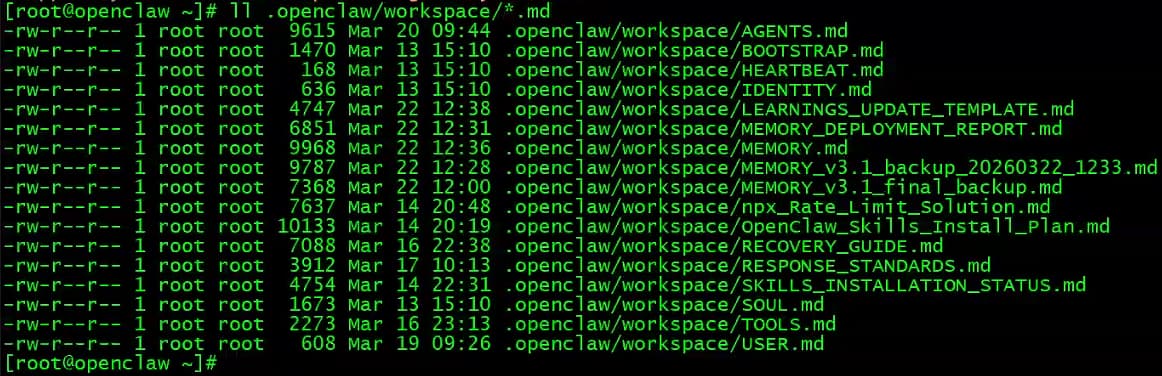
在OpenClaw的workspace中,核心记忆文件如下:
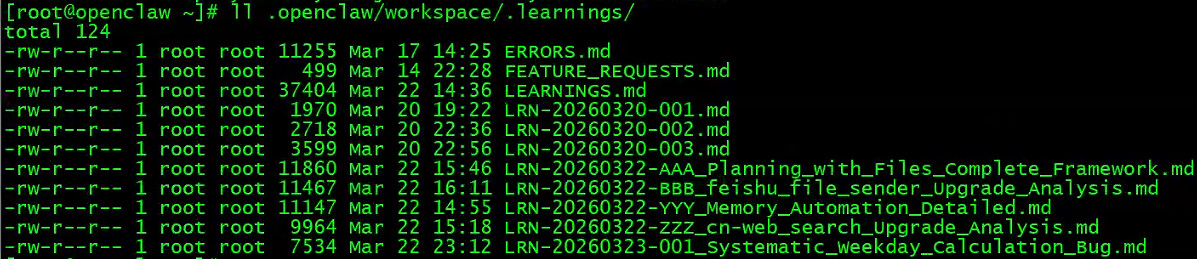
若安装了self-improving-agent技能,在workspace下的.learning文件夹中,还会生成其他md记忆文件:
用md文件记录记忆,优势在于OpenClaw能直接调用操作系统的各类命令对记忆进行操作,适配性强、上手简单。但这一方式的弊端也十分突出,且这些弊端与人脑的记忆运行逻辑形成了鲜明反差:人脑能自主对记忆进行分类、压缩、关联,在提取时能快速匹配语义与场景,而文件式记忆完全不具备这类自主优化能力,具体问题体现在三方面:
- 以文件形式操作记忆,会产生大量的Token消耗,如同人脑若对每一段记忆都逐字提取、处理,会极大消耗认知资源;
- 随着使用时间增加,记忆文件的容量会持续膨胀,加载与修改的效率会越来越低,成为性能瓶颈。即便定期对文件进行整合优化,又会不可避免地丢失记忆细节,这与人脑能保留关键记忆、弱化无效信息的高效记忆管理形成鲜明对比;
- 纯文本的信息载体,无法支撑图像、音频、视频等更高级的多模态记忆内容,而人脑的记忆本就是多模态融合的结果,视觉、听觉、触觉等信息会交织形成完整的记忆链。
正因为文件式记忆的诸多痛点,我认为通过数据库重构AI Agent的记忆系统,是解决记忆问题的最优解之一。此前我曾尝试用向量数据库LanceDB改造OpenClaw的记忆模块,但实际效果并不理想,核心问题集中在三点:
- 文本经向量嵌入存储后,自检的结果匹配度≤70%,部分甚至低于40%,语义匹配的精度大打折扣,远不如人脑对相似记忆的精准联想;
- 静态记忆做向量化存储,动态记忆仍采用文本存储,形成两套相互独立的记忆系统,联动性极差,就像人脑的短期记忆与长期记忆无法互通,会导致认知断层;
- OpenClaw本身的启动加载逻辑并未适配向量数据库,需要对其进行深度调 教,甚至手动修改md文件的底层配置,改造成本高。
其中第三个问题,可等待OpenClaw的后续版本升级或自行二次开发解决,而前两个问题,则指向了AI Agent记忆存储的核心本质:记忆从来不是单纯的结果记录,而是包含原文、语义、场景、关联信息的叠加式溯源链,这与人脑的记忆逻辑高度一致——人脑的每一段记忆,都附着着时间、场景、相关人物与事件的关联线索。因此,纯粹依靠向量来存储记忆本身,从底层逻辑上就存在缺陷。当然,在记忆数据规模尚未达到量级时,采用文本+向量数据库的混合存储方式,仍能在一定程度上解决OpenClaw的记忆问题。
上周末在成都的线下龙虾技术交流活动中,我与王璞老师就AI时代的技术生态展开了深度探讨,其中一个观点让我深有感触:传统的IT系统和产品,处理的目标都是精确的结果,输入与输出存在明确的对应关系;但在AI时代,AI本身存在天然的容错性,甚至可能产生错误的结果,这一特性直接导致整个AI产品生态的底层逻辑发生了根本性变化。
这一观点映射到数据库领域,同样适用。若我们将数据库作为AI Agent记忆体的核心载体,必然希望在任何记忆操作中,都能获取尽可能精确的记忆结果。但不可否认的是,向量存储与检索本身就是非精确性的,这是AI时代数据库需要攻克的核心矛盾。而数据库作为标准化的软件产品,其进化方向也必须围绕AI Agent的记忆需求展开。
在AI场景下,向量数据的来源极为丰富,可来自文本、图像、视频、音频等多模态内容,也可来自结构化/半结构化数据、直接的特征提取,或是各类数据整合后的结果。而数据库中的标量数据,具备精确性的核心优势。在诸多实际应用场景中,向量数据与标量数据并非孤立存在:当数据库支持标量数据与向量数据(及其他类型数据)的联合存储时,标量数据不仅能作为向量检索的补充,提升检索精度,还能成为向量的额外标记,为语义匹配提供更具体的线索,让AI Agent的记忆提取更贴近人脑的联想逻辑。
要实现这一目标,数据库必须具备多模态支持能力。在未来的企业级应用场景中,越来越多的AI Agent会投入使用,带来的直接结果是记忆来源更广泛、数据量更庞大、调用频次更高,这就对数据库提出了两大核心要求:一是海量数据的高效入库与存储能力(这一点也与我此前撰写的《数据库管理-第406期 别急着喷!AI时代,为什么TP才是数据库的核心?(20260203)》一文的观点相呼应);二是混合检索的高性能表现。同时,为了简化AI对记忆数据的操作流程、进一步提升数据库性能,数据库必须采用统一的引擎和统一的操作方式,对多模态数据进行一体化管理,就像人脑用同一个记忆中枢,整合并处理所有感官带来的记忆信息。
但解决了标量与向量数据的联合存储、多模态管理问题,是否就意味着AI Agent的记忆问题被彻底解决了?答案是否定的。回到我们此前提出的核心观点:记忆是溯源链,同时记忆与记忆之间存在复杂的关联关系。如何让AI Agent像人脑一样,方便、快速地检索这些“链条化”和“网状化”的记忆数据,挖掘数据背后的关联逻辑,这一问题的重要性,甚至超过了向量数据存储本身。
有人会问,能否用图数据库解决这一问题?毕竟图数据库的核心优势就是处理关联数据,还能支撑知识图谱的构建。但实际应用中,图数据库存在明显的短板:在高频的记忆数据变更场景下,其性能会大幅下降;更重要的是,我更希望图数据能成为数据库多模融合的有机一环,而非独立的存储模块,否则会增加数据存储与操作的步骤链条,降低AI Agent的记忆处理效率,这与人脑将所有关联记忆整合在同一记忆系统中,而非分散存储的逻辑相悖。
这时候,我想到了此前撰写的两篇关于属性图的文章:《数据库管理-第186期 23ai:啥?我还能干掉Neo4j?(20240509)》,《数据库管理-第188期 23ai:怎么用PGQL创建图(20240511)》,Property Graph(属性图)或许就是解决这一问题的关键。
当然,属性图并非Oracle最新版本数据库的独有功能,目前已有不少数据库开始跟进这一技术。我认为,属性图的核心价值在于,它能通过统一的存储架构、统一的数据库引擎以及统一的数据操作方式,将记忆中的溯源链条和关联关系,与前文提到的标量+向量数据进行深度融合。这种融合并非简单的拼接,而是将精确的标量匹配、模糊的向量语义检索,以及复杂的图关系获取有机结合,为AI Agent输出更精确、更贴合实际需求的混合检索结果。更重要的是,这种检索方式能直接为AI Agent提供完整的记忆关联链,无需AI再进行额外的思考与拼接,大幅降低了其思考步骤与难度,让AI Agent的记忆提取更接近人脑的自然联想过程。
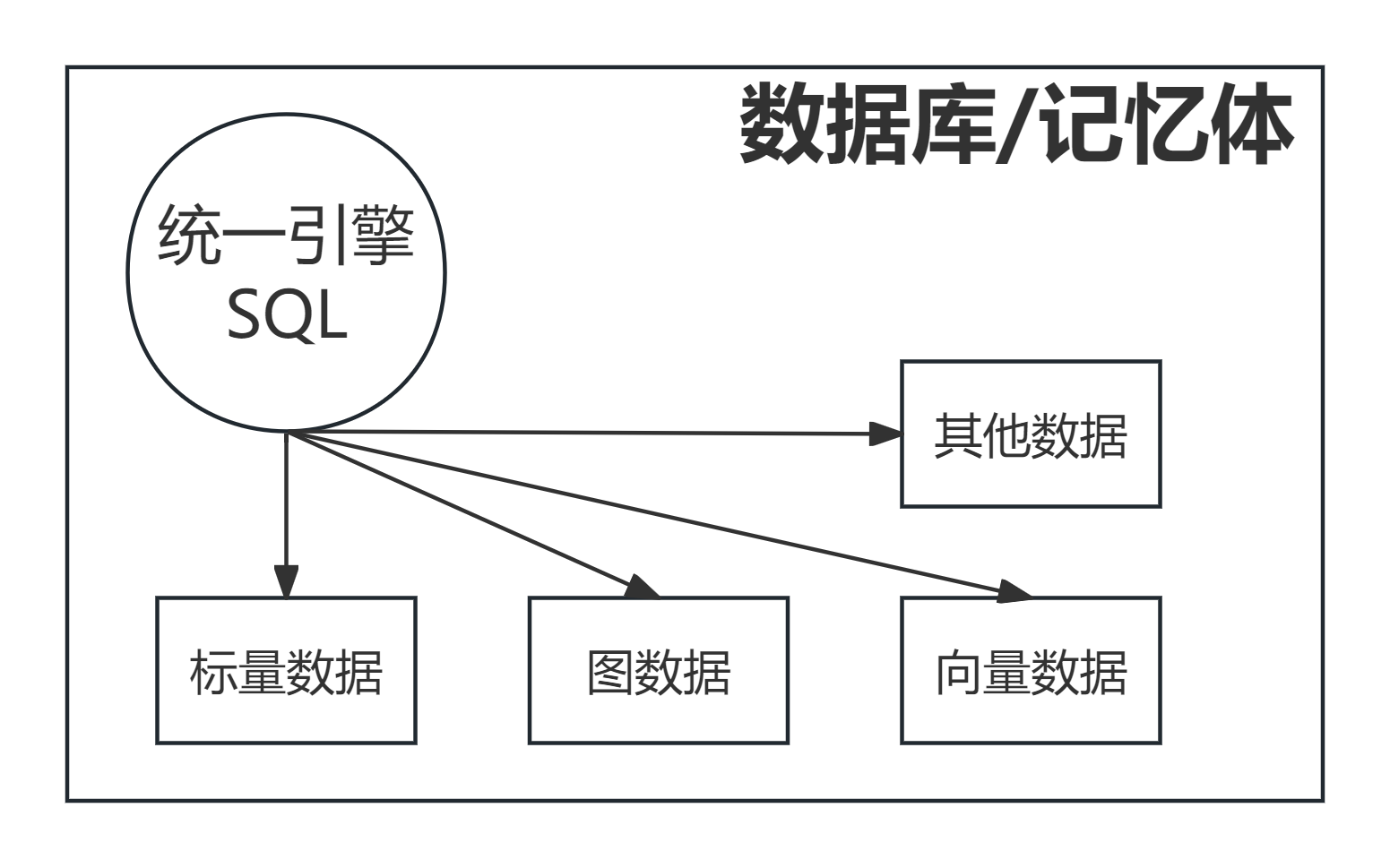
从当下的行业现状来看,AI Agent的发展仍处于相对粗放的初级阶段,绝大多数产品的记忆体设计,要么停留在简单的文件存储层面,要么是向量与文本的生硬拼接,尚未形成符合AI智能进化的记忆体系。这就像人类的原始认知阶段,只能对信息进行简单的记录与提取,无法进行深度的整合、关联与运用。
而记忆体,正是推动AI Agent从“粗放”走向“精细”的核心抓手。人脑的智能进化,离不开记忆系统的不断完善 —— 从短期记忆到长期记忆,从碎片化记忆到结构化记忆,从单模态记忆到多模态融合记忆,记忆系统的升级直接推动了人类认知能力的提升。对于AI Agent而言,亦是如此:当记忆体实现了标量+向量+图关系的多模融合,具备了自主的记忆分类、压缩、关联、溯源能力,能像人脑一样高效地存储、提取与运用记忆时,AI Agent的智能表现将实现脱胎换骨的变化。
未来的AI Agent,不再是简单的“指令执行器”,而是能依靠完善的记忆体,实现持续的自主学习、场景化决策与逻辑化思考的智能体。而记忆体的建设,也将成为AI Agent产品竞争的核心赛道——谁能打造出更贴近人脑逻辑、更高效、更精准的记忆系统,谁就能在AI时代的竞争中占据先机。OpenClaw作为一款开源的AI Agent框架,其记忆体的探索与改造,正是这一赛道上的一次重要实践,而这一实践的成果,也将为整个AI Agent行业的记忆体设计提供有价值的参考。