【 使用环境 】生产环境 or 测试环境
【 OB or 其他组件 】
【 使用版本 】
【问题描述】
集群为3副本集群,2.10是主副本。2.8和2.9是从副本。 允许弱读。
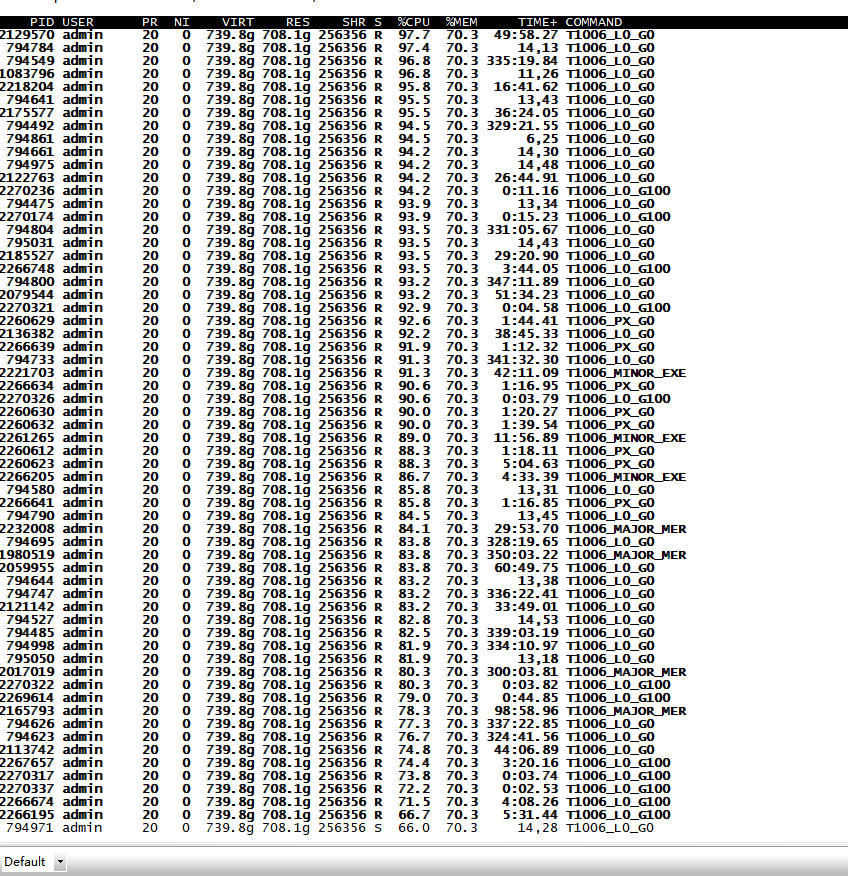
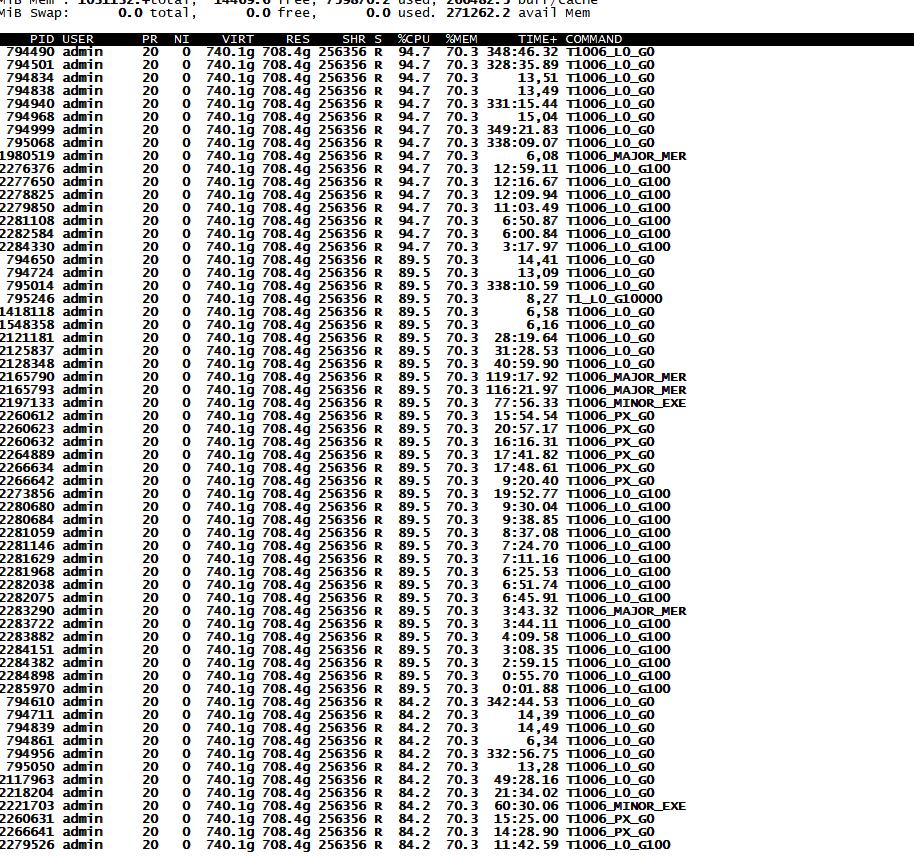
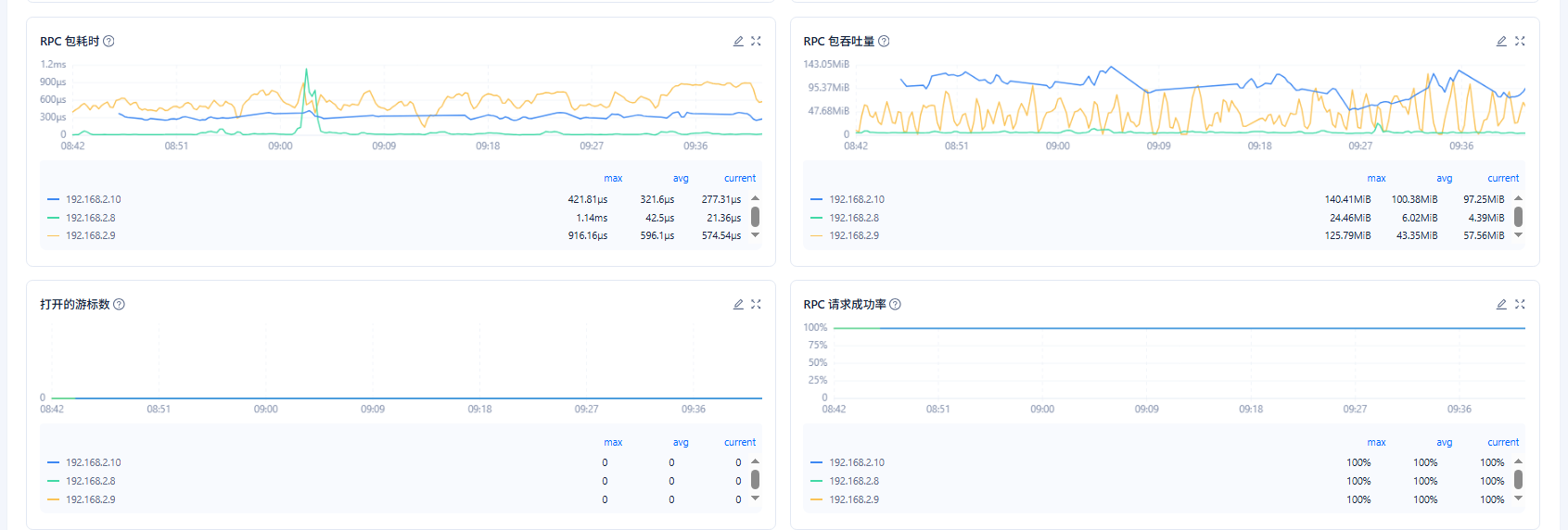
如图,2.9副本机器cpu一直99%下不去
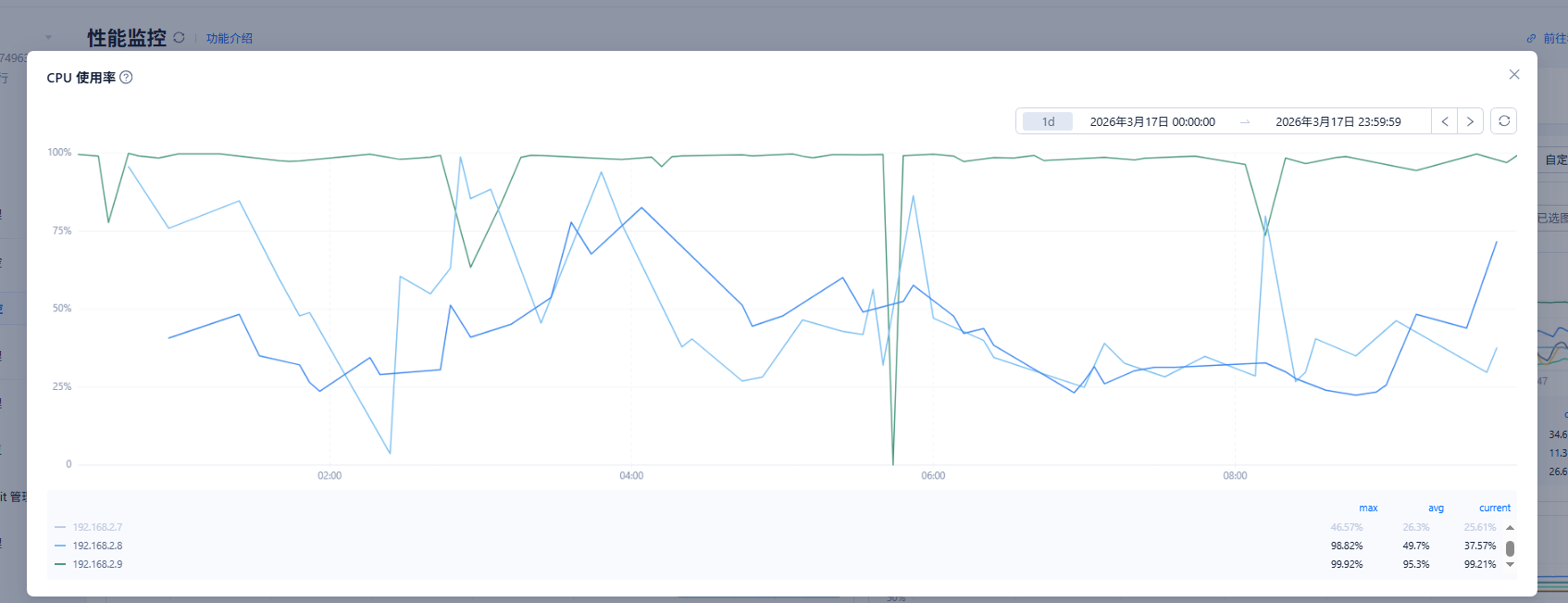
2.8和2.9都是从副本,但是只有2.9存在rpc吞吐量。2.8没有
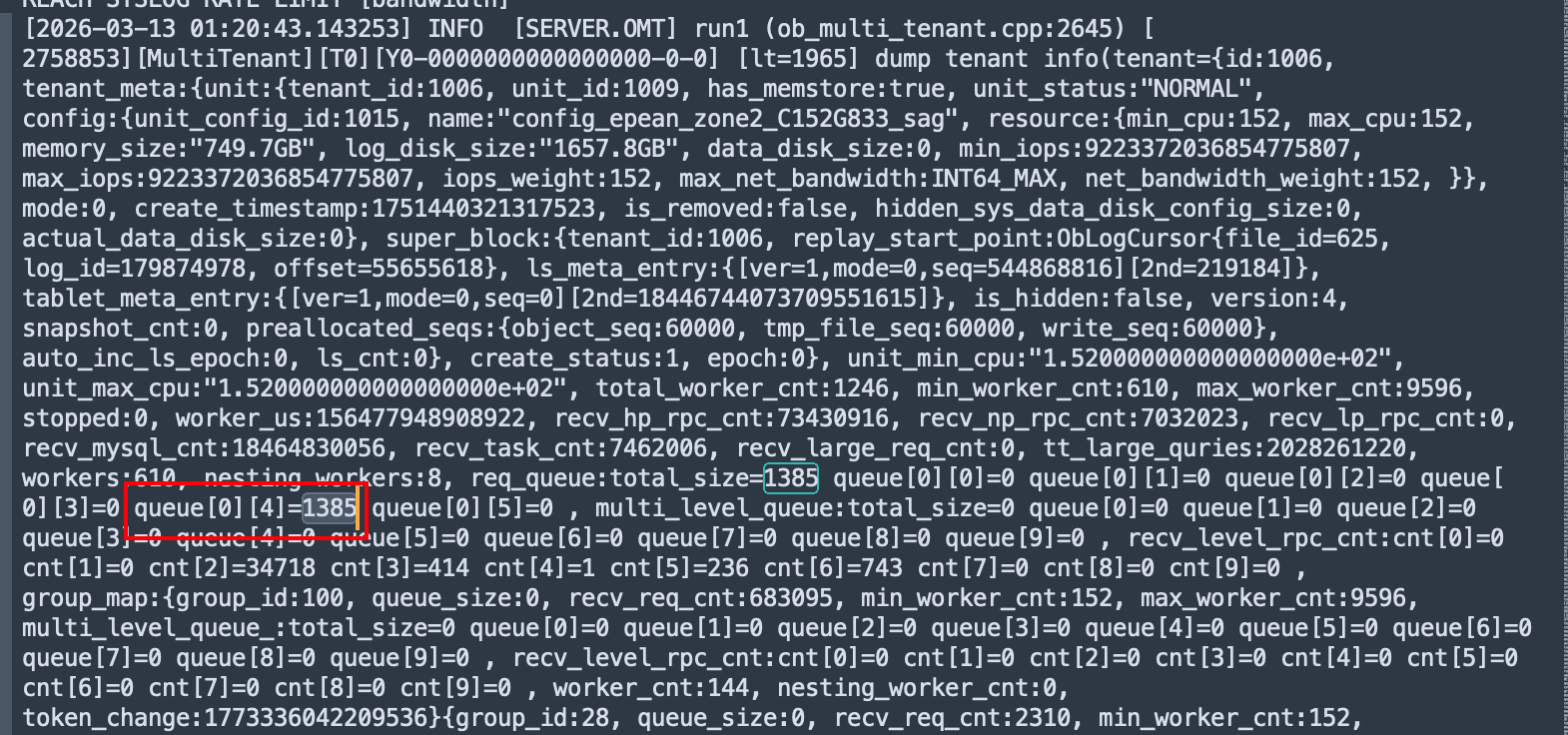
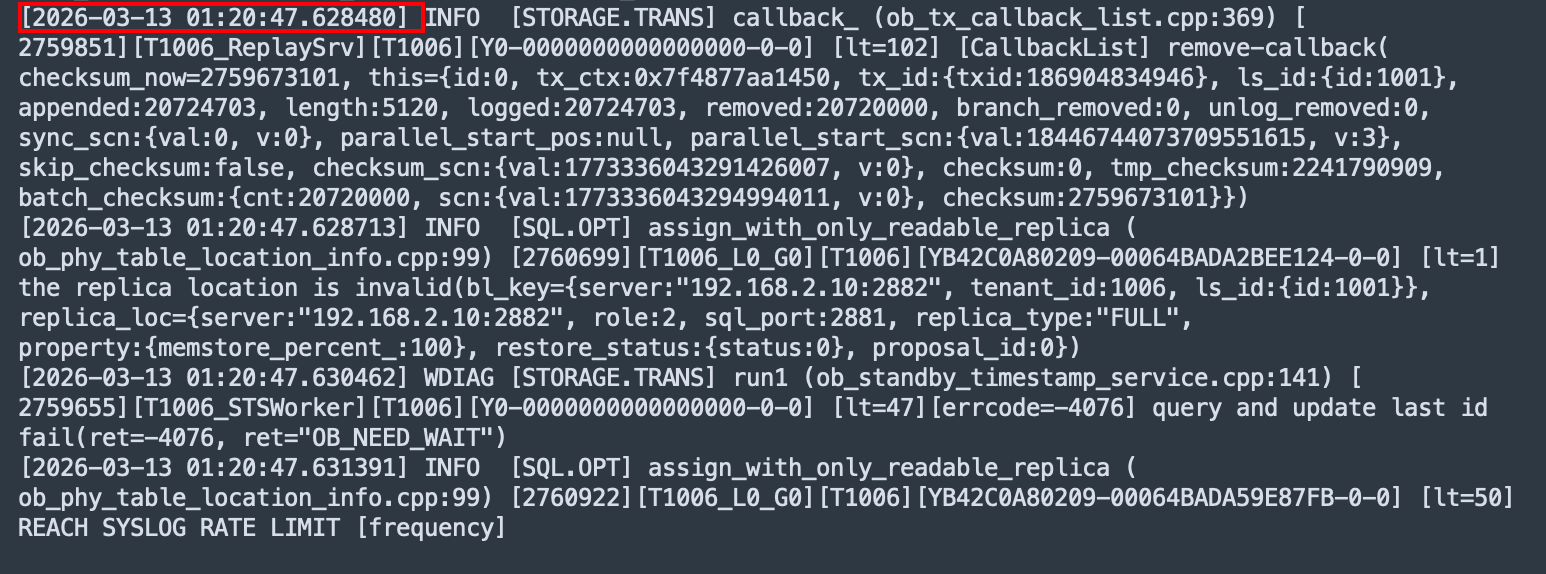
observer.log cpu爆满开始的一个日志文件如下
observer.log.zip (31.7 MB)
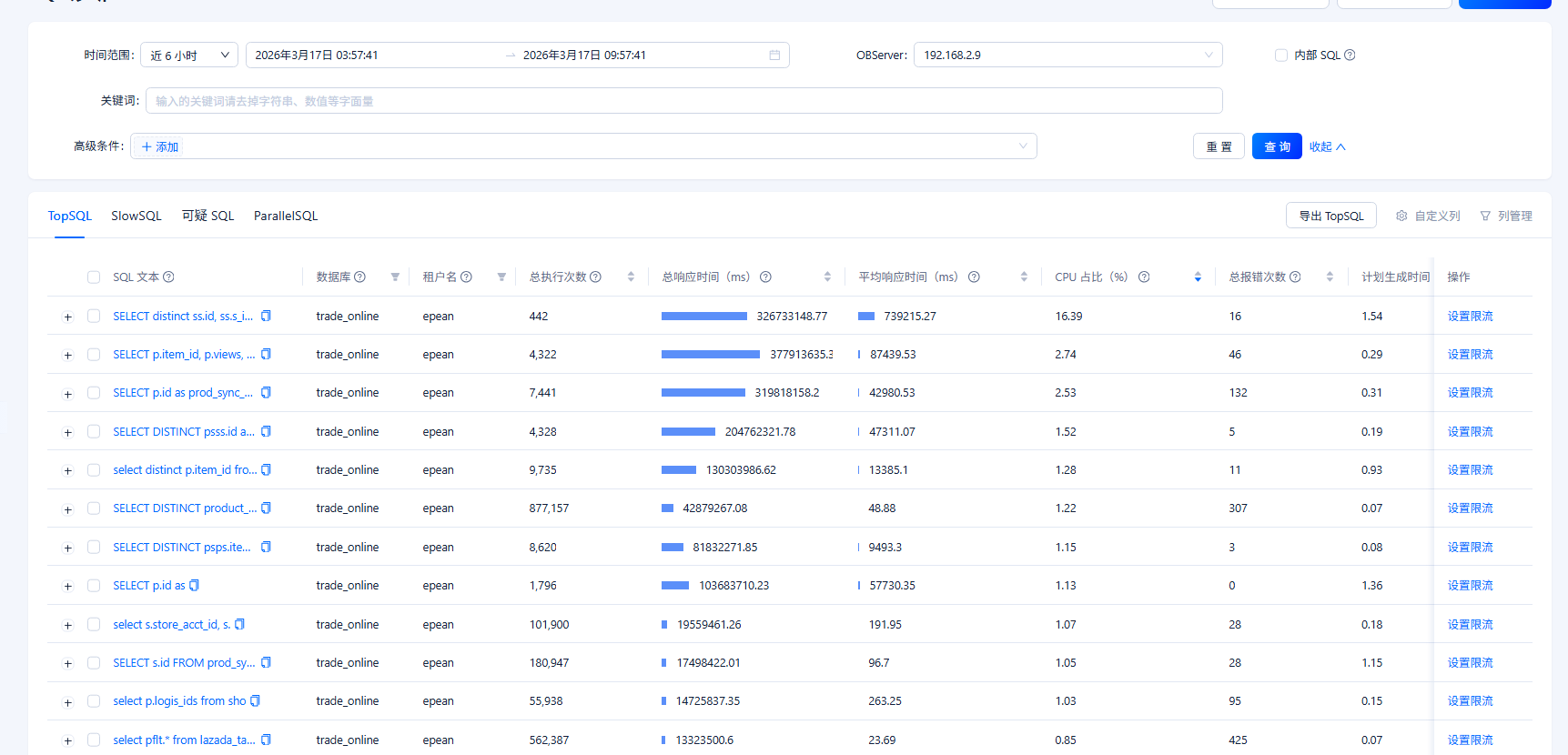
topSql排查
巡检信息稍后补充
【 使用环境 】生产环境 or 测试环境
【 OB or 其他组件 】
【 使用版本 】
【问题描述】
集群为3副本集群,2.10是主副本。2.8和2.9是从副本。 允许弱读。
如图,2.9副本机器cpu一直99%下不去
observer.log cpu爆满开始的一个日志文件如下
observer.log.zip (31.7 MB)
topSql排查
巡检信息稍后补充
从top sql查看应该还是sql造成的 看着cpu的占比不是很高 2.9节点 上查看一下这个信息 截图 top -H -p $(pgrep observer)
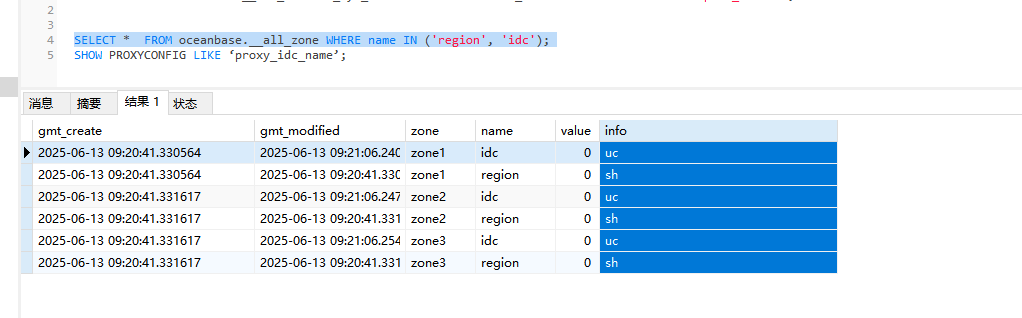
SELECT zone, name, value FROM oceanbase.__all_zone WHERE name IN (‘region’, ‘idc’);
SHOW PROXYCONFIG LIKE ‘proxy_idc_name’;
查询下proxy和ob的机房配置。默认情况下弱读请求会优先路由到与 OBProxy 同 IDC / 同 Region 的 follower
来学习
分布式数据库集中式用法 ![]()
没办法。旧项目,要分区的话,得等后面再规划了
学习下
obstack这个命令 不能直接调用 需要进入到observer目录下 obstack ${pid of observer} > obstack.trc
使用obstack打一下 堆栈信息
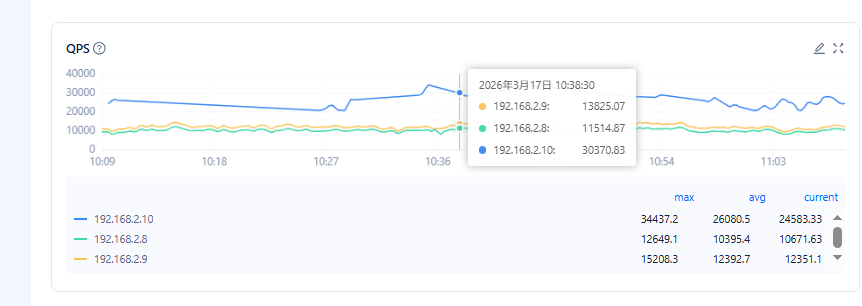
ocp上qps相关的截图 也发一下吧
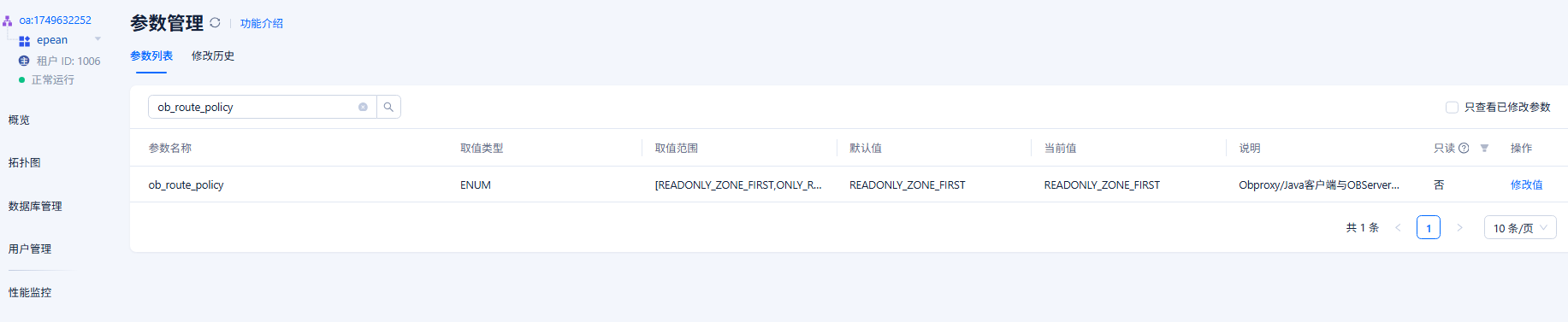
路由配置是设置的follower first么
ob_route_policy = ‘FOLLOWER_FIRST’;
堆栈中显示还是sql并行查询存在大量索引回表导致
UNMERGE_FOLLOWER_FIRST改成这个试试。上面是只读优先,follow副本不是只读副本