

AI一文扫盲
最近几年,AI相关名词越来越多:看着看着就懵了,所以总结一下常见的高频词,辅助大家来理解
——星河璀璨
![]() 每周速递来了~ - 社区问答- OceanBase社区-分布式数据库
每周速递来了~ - 社区问答- OceanBase社区-分布式数据库
AI
├── LLM
│
├── Embedding
├── 向量数据库
├── RAG
│
├── Agent
│ ├── Tools
│ ├── Skills
│ └── Workflow
│
└── Function Calling
1. AI (人工智能)
-
定义: 人工智能(Artificial Intelligence),英文缩写为AI。是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新技术科学。
-
通俗解释: AI = 让机器像人一样“理解” 和“思考”。
常见的能力包含:
- 聊天
- 写代码
- 分析数据
- 识别图片
2. LLM (大预言模型)
-
定义: 大模型LLM(Large Language Model)是指具有大规模参数和复杂计算结构的机器学习模型。
-
通俗解释: LLM = 一个超级会说话的“语言预测机器”
他本质是在做:
根据前文预测下一个词
eg:qianwen3.5-4b、openai
# 示例
from openai import OpenAI
client = OpenAI(api_key="你的API_KEY")
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "user", "content": "请解释什么是SQL索引"}
]
)
print(response.choices[0].message.content)
3. Prompt (提示词)
-
定义: Prompt 是一种指令或信息,它引导或触发 AI 系统做出回应。在与 AI 如 ChatGPT 的交互中,每当我们输入一段文字,无论是问题、命令还是陈述,这段文字就是一个 Prompt。
-
通俗解释: Prompt = 你给AI的指令
写得好 → 回答质量高
写得乱 → 回答也乱
Prompt 的作用
触发回应:Prompt 是与 AI 进行交流的起点,它告诉 AI 我们需要什么样的信息或反应。
引导对话:通过使用特定的 Prompt,我们可以引导 AI 沿着特定的思路或话题进行回答。
影响输出:AI 的回应会根据 Prompt 的内容而变化。一个明确、具体的 Prompt 通常会得到更精确和相关的回答。
# 示例
prompt = """
你是一名数据库专家,请用简单语言解释:
什么是SQL索引?
并给一个例子。
"""
4. Embedding (向量化)
- 定义: Embedding(嵌入)是指把文本(也可能包括图像、视频等其他模态数据)转成能表达语义信息的浮点数向量,向量之间的数学距离可以反映对应文本之间的语义相关性
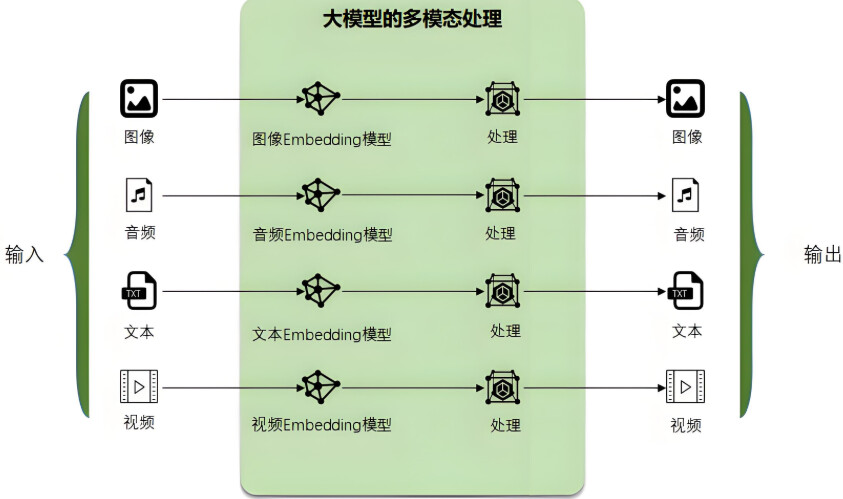
- 通俗解释: 把一句话变成一串数字。
例如:
“ERP卡顿” → [0.124, -0.334, 0.987, …]
用于:
- 语义搜索
- 相似度计算
# 实例
response = client.embeddings.create(
model="text-embedding-3-small",
input="ERP系统性能优化"
)
vector = response.data[0].embedding
print(len(vector)) # 向量维度
更多信息参考:Transformer | 一文带你了解Embedding(从传统嵌入方法到大模型Embedding) - 知乎
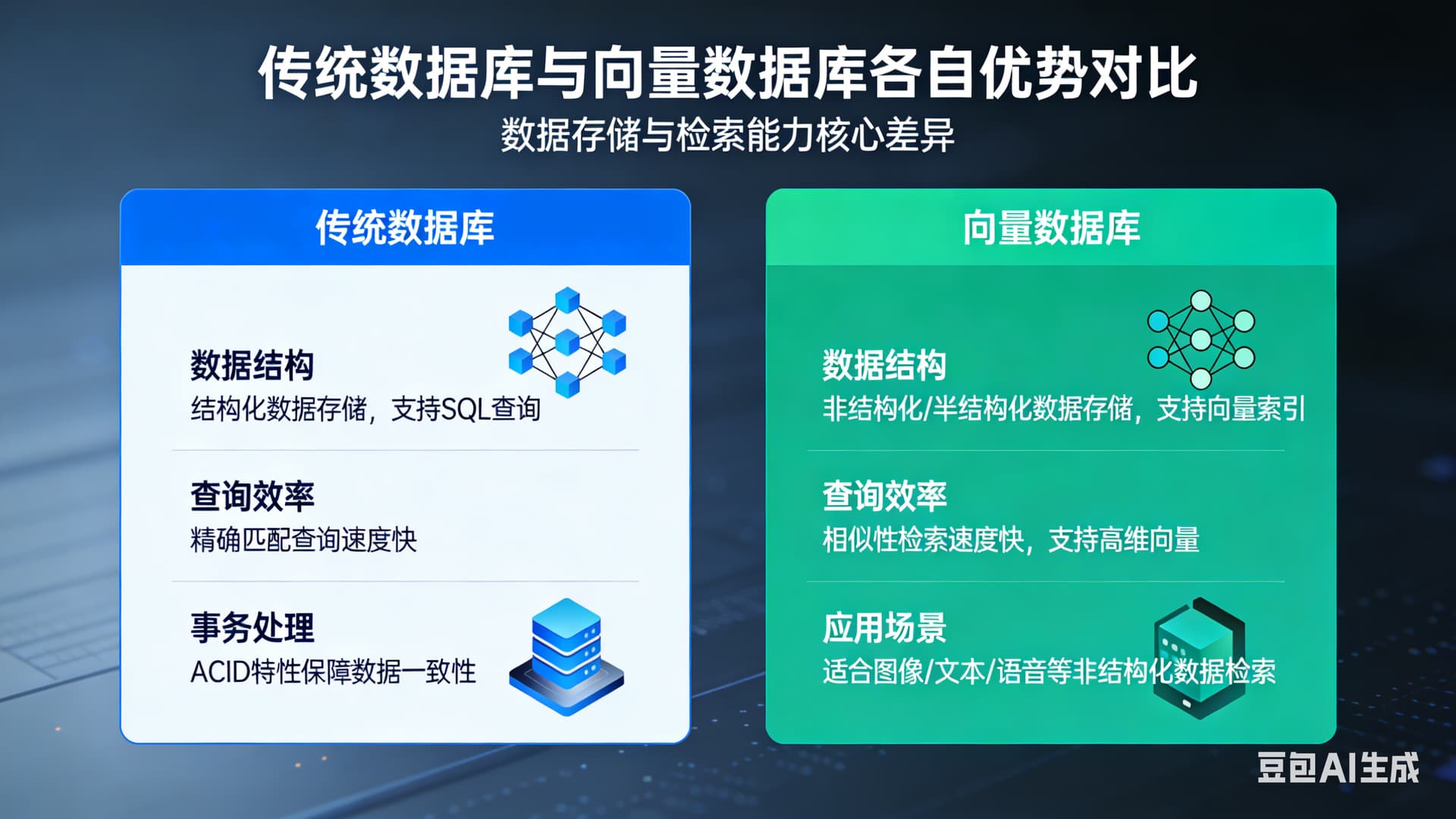
5. Vector Database (向量数据库)
-
定义: 向量数据库是一种专门用于存储和处理向量数据的数据库系统。它以向量为基本数据类型,将向量作为数据的主要组织形式。
-
通俗解释:
普通数据库按“精确匹配”查数据。
向量数据库按“语义相似”查数据。

# 示例
# 导入 numpy 数学计算库
# numpy 主要用于向量、矩阵计算
import numpy as np
# 创建第一个向量
# 你可以理解为:一句话转换成的数字表示
v1 = np.array([0.1, 0.3, 0.5])
# 创建第二个向量
# 代表另一句话的数字表示
v2 = np.array([0.1, 0.2, 0.4])
# 计算两个向量的“点积”
# 点积公式:a1*b1 + a2*b2 + a3*b3
# 用于衡量两个向量的相似程度
similarity = np.dot(v1, v2)
# 打印相似度结果
print("相似度:", similarity)
真实项目中可以用:seekdb!!
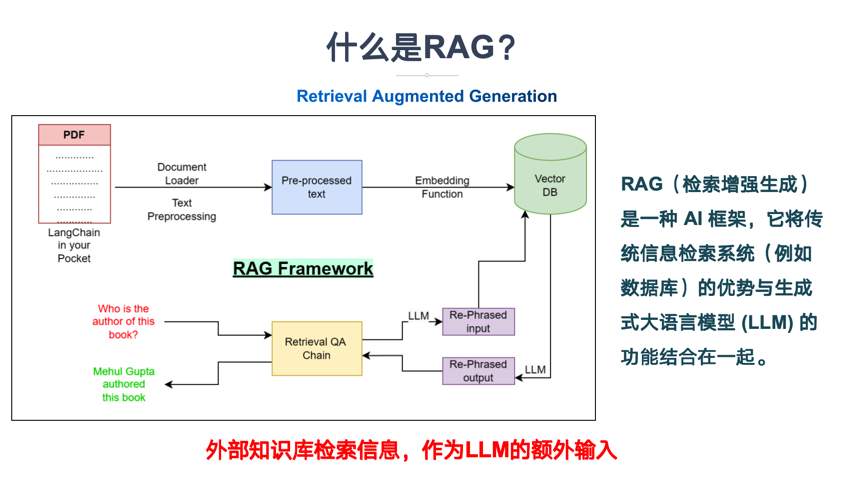
6. RAG (检索增强生成)
-
定义: RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合了信息检索技术与语言生成模型的人工智能技术。该技术通过从外部知识库中检索相关信息,并将其作为提示(Prompt)输入给大型语言模型(LLMS),以增强模型处理知识密集型任务的能力,如问答、文本摘要、内容生成等,RAG模型由FacebookAlResearch(FAIR)团队于2020年首次提出,并迅速成为大模型应用中的热门方案。
-
通俗解释:
流程:
- 查知识库
- 把结果给 LLM
- 再生成回答

# 假设这是从知识库检索到的内容
retrieved_text = "ERP卡顿通常与慢SQL和锁等待有关。"
question = "ERP为什么会卡顿?"
final_prompt = f"""
根据以下资料回答问题:
资料:
{retrieved_text}
问题:
{question}
"""
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": final_prompt}]
)
print(response.choices[0].message.content)
更多信息参考:一文彻底搞懂大模型 - RAG(检索、增强、生成)-CSDN博客
7.agent (智能体)
-
定义: 是指能够感知环境并采取行动以实现特定目标的代理体。
-
通俗解释:
LLM = 大脑
Agent = 大脑 + 手脚 + 工具
可以自动执行任务。
8. Function Calling(函数调用)
-
定义: 是一种赋予大语言模型(LLM)调用外部函数能力的机制,使其能够结合真实数据或执行特定操作来满足用户需求,而不仅仅依赖模型自身的推理能力。这一技术最早由 OpenAI 在 GPT-4 中引入,随后被其他模型广泛采用。
-
通俗解释: 让AI输出“调用哪个函数”
import json
# 模型假设返回
model_output = {
"function": "get_cpu_usage",
"args": {}
}
if model_output["function"] == "get_cpu_usage":
print(get_cpu_usage())
9. Tools(工具)
-
定义: 赋予语言模型调用外部预定义函数或API的能力。模型能根据用户意图,生成包含特定函数名和参数的请求,以执行外部操作。
-
通俗解释: 让AI的手能伸出虚拟世界。当AI自己做不了某件事时(比如查实时天气、订机票),它可以“摇人”,调用外部的软件程序来帮忙完成。
-
例如:
- 查数据库
- 运行Python
- 调接口
def run_sql(sql): return f"执行SQL: {sql}" question = "查询用户数量" sql = "SELECT COUNT(*) FROM users" print(run_sql(sql))
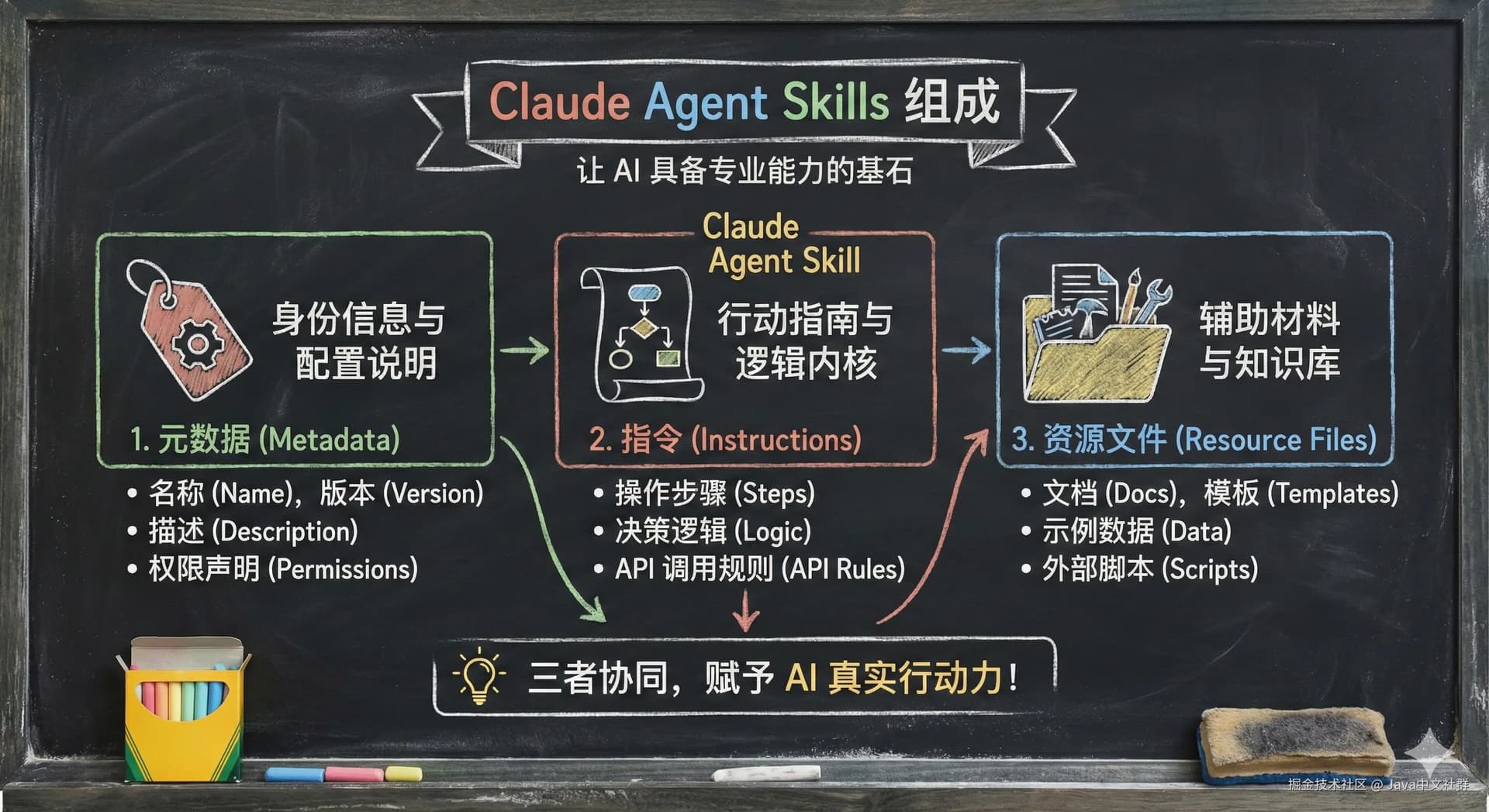
10. Skills(技能)
- 定义: 在 AI 界,Skills 就是让大模型按照某种特定的方法论去行动的机制
- 通俗解释: Skill = 封装好的一类能力模块
eg: SQL优化Skill、数据分析Skill、报表生成Skill
你可以把它理解为 “超级进化版的提示词”。因为它比普通提示词强得多,通常由三部分组成:
[!NOTE]
- 元数据 (Metadata): 包含对这个技能的简短描述。它保存在全局上下文中,因为体积小,所以非常节省 Tokens(省钱又省心)。
- 行动指南 (Action Guide): 这部分才是真正的提示词,规定了 AI 每一步该怎么做。
- 资源文件 (Resources): 这是最厉害的地方!它可能包含 Python 代码 或其他执行程序,保证程序在调用 Skill 时能完成复杂的动作。
def sql_optimize_skill(sql):
prompt = f"""
你是数据库专家,请优化以下SQL:
{sql}
"""
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
print(sql_optimize_skill("SELECT * FROM users"))
11. Workflow(工作流)
-
通俗解释: 多步骤流程自动执行。
-
例如:
-
读取慢SQL
-
分析原因
-
生成优化方案
-
输出报告
-