【 使用环境 】生产环境
【 OB or 其他组件 】
【 使用版本 】4.3.5.4
【问题描述】
集群架构1-1-1。
单机配置:
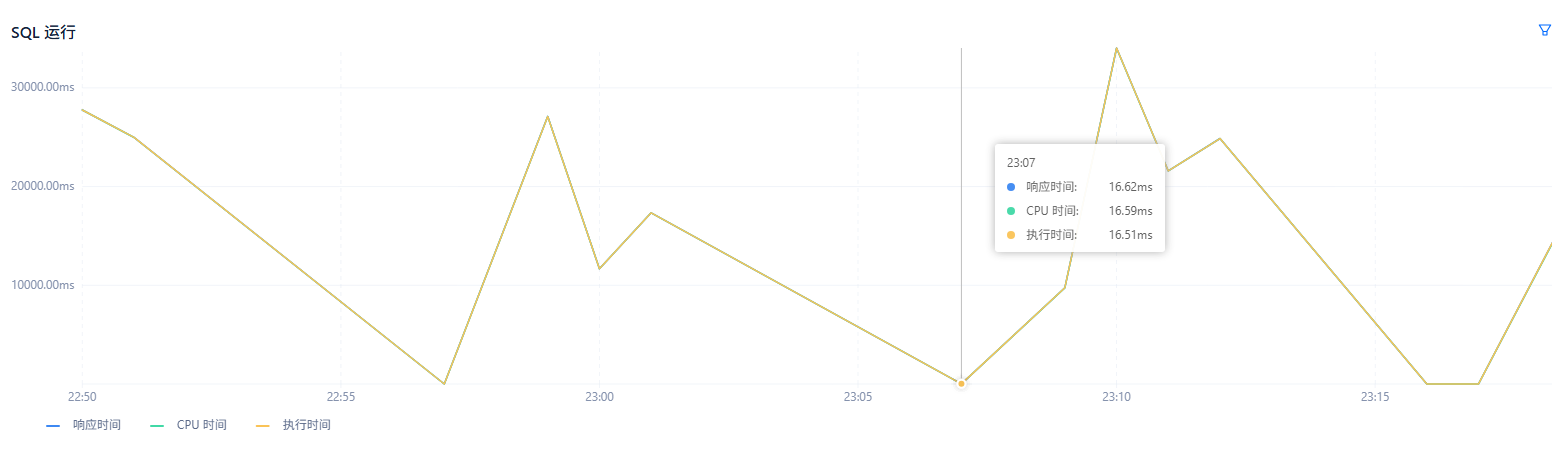
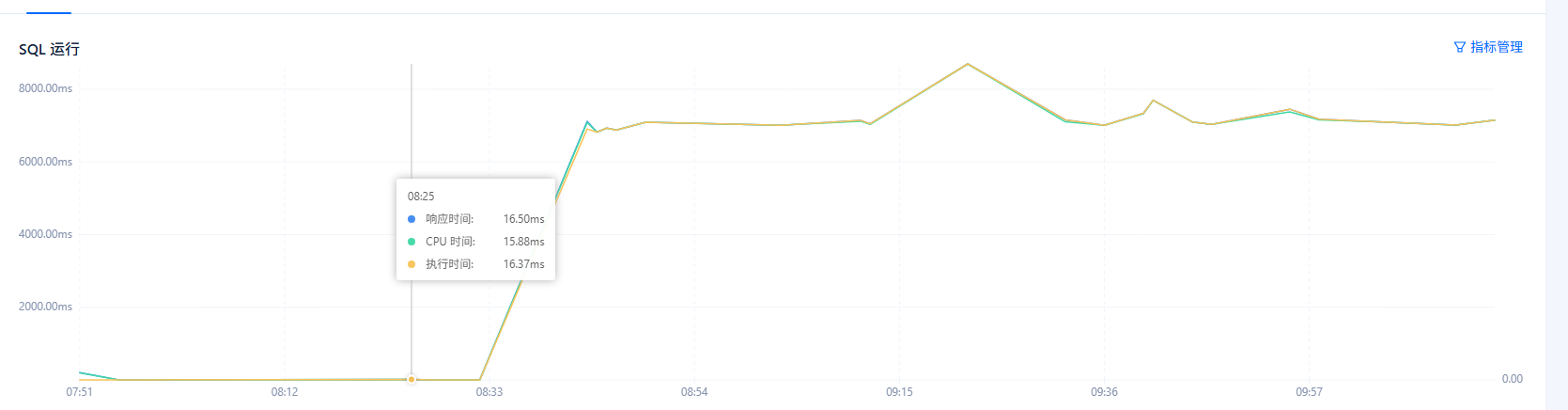
集群整体查询都变慢,不走索引。
巡检信息:
obdiag_check_report_observer_2026-03-13-17-08-37.log (126.9 KB)
observer.log抛出异常
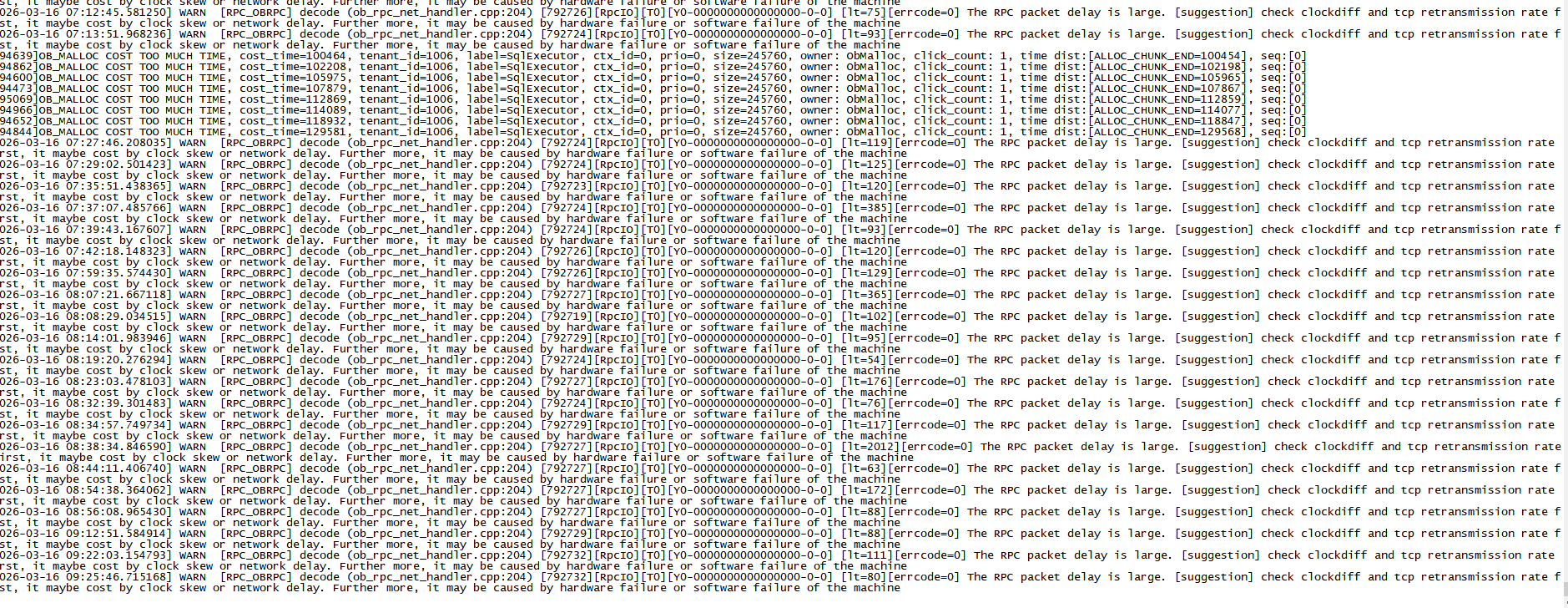
检查时钟也无异常

网络重传率也不高

大量sql本来执行计划是很优秀的。却突然走了一条拉闸计划,还不会自己修正
【 使用环境 】生产环境
【 OB or 其他组件 】
【 使用版本 】4.3.5.4
【问题描述】
集群架构1-1-1。
单机配置:
集群整体查询都变慢,不走索引。
巡检信息:
obdiag_check_report_observer_2026-03-13-17-08-37.log (126.9 KB)
observer.log抛出异常
检查时钟也无异常
网络重传率也不高
大量sql本来执行计划是很优秀的。却突然走了一条拉闸计划,还不会自己修正
根据您提供的信息,集群整体查询速度变慢,并且不走索引。以下是可能的原因和建议:
EXPLAIN 命令来查看执行计划,确认是否使用了预期的索引。EXPLAIN SELECT * FROM your_table WHERE your_condition;
ANALYZE TABLE 命令来更新统计信息。ANALYZE TABLE your_table;
top
free -m
iostat -x 1
ping -c 4 <remote_ip>
obser.log 抛出异常的信息,需要进一步分析这些异常日志,找出具体的问题。tail -f /path/to/obser.log
obdiag 工具进行了巡检,但 obdiag 报告中的一些任务失败了。建议重新运行 obdiag 并检查详细的报告。obdiag check --all
SHOW VARIABLES LIKE 'innodb_buffer_pool_size';
SHOW VARIABLES LIKE 'query_cache_size';
SHOW FULL PROCESSLIST;
集群整体查询速度变慢可能是由多种因素引起的,包括索引使用不当、系统资源不足、网络问题、日志异常等。通过上述步骤逐项排查,可以逐步定位问题并采取相应的解决措施。希望这些建议对您有所帮助。
更多信息请查看:
这个问题涉及到CPU和obdiag的平衡,根据我的经验,适当调整your会有帮助。
IO和CPU没有做好科学配置
仔细讲讲,万分感谢。或者有没有经验贴
开启新篇章!!
同sql在不同时间段性能不一致吗?
OceanBase 社区已接收您的帖子,正在跟进中。
开启新篇章!!
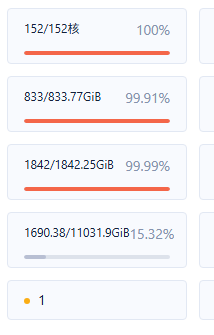
帮忙,截下图,看看 【 集群 - 资源管理 】 界面,的具体使用情况,IP可以打码,其它发全一点。
主要是想了解下 152核的CPU是如何分配的,是全部分给了业务租户么? 留给 SYS 租户多少?(尽量给SYS租户 4C12G以上)。
现象:集群sql计划突变,计划不优。
原因:
1、dml操作较多,还会有buffer表的问题。
2、查询中in传入参数数量不同的会生成不同的sql_Id。生成的执行计划会很多,达到plan cache上限以后,会淘汰掉执行计划。表的dml操作很多,导致的统计信息不准或者失效而算子估算有问题,走了不优的执行计划。
当前可实行解决方案:
1、相似的文本可以尝试绑定 format outline
2、dml操作多的表考虑重新收集统计信息
3、内存允许的条件下扩容plan cache
4、buffer表问题可以修改table_mode
短期可以通过绑定执行计划解决,长期建议租户开启spm功能,避免执行计划突变,详情见:https://www.oceanbase.com/knowledge-base/oceanbase-database-1000000003137377
set global optimizer_use_sql_plan_baselines = true;
set global optimizer_capture_sql_plan_baselines = true;
alter system set sql_plan_management_mode = ‘OnlineEvolve’;
只配用社区办的穷鬼。
用不了高贵的官版spm
不过现在AI牛逼了。 我让AI来搞一套SPM试试
看看看看