“社区的每一次进步,都离不开开发者和共建者的支持。”这是老纪(OceanBase 开源生态总经理封仲淹,花名纪君祥)在1月31日的OceanBase社区嘉年华中,对社区用户表达的衷心感谢。

感恩有你,开源同行:2025年OceanBase社区回顾
从2023年开始,每年年底与大家相聚的“社区嘉年华”,已经成为我们最期待的事。这不仅仅是一场活动,更是所有OceanBase社区的开发者、贡献者和朋友们的一次“回家”和共创。今年,我们以“一路有你”为主题在上海相聚,老纪与大家面对面分享了社区的初心,并一起畅想了2026年我们共同期待的模样——一个更开放、更好玩、真正属于每一位开发者的成长平台。
过去一年,最让我们骄傲的不是数字的增长,而是社区里自然生长出的那些生动而自发的联结:
•论坛里,越来越多的开发者开始主动“结对子”,新手的问题常被秒回,深度的技术讨论也时常激荡出新的火花;
•新入驻的近百位博主主动把实战中的“踩坑”笔记和心得分享出来,形成了独特的、真实的技术文库;
•许多朋友和社区一起组织了“城市交流会”,也在线上直播和培训营中贡献实操经验。
这些成果,本质上是所有参与者用热情和时间共同浇灌出的风景。每一位的参与,无论形式,都在让这个共有的“知识库”更加丰富,也让“一个人走”的学习过程变成了“一群人一起玩”。
正是基于这样的联结,我们在嘉年华现场设置了一个特别环节——技术开放麦,并为大家准备了一份小而暖的致谢和荣誉授予仪式。这不仅是感谢,更是一份面向所有开发者的共建邀请:2026年,我们决心与大家一起,不只是数据库运维能力更上一层楼,更要跟上AI时代的步伐,围绕seekdb打造一个真正好用的AI开发者学习与实验平台。在这里,成长不是任务,而是一场值得享受的探索与共创之旅。
未来的社区,将不仅仅围绕数据库,更会积极拥抱AI开发者生态。我们期待与你一起,从这里出发,让技术学习变得有趣,让开源贡献变得自然,让每一个好的想法都能找到伙伴,共同落地。
社区嘉年华:OceanBase 的开源理念与新年规划
大家好,我是来自OceanBase社区的封仲淹,花名纪君祥,很荣幸跟大家分享社区的进展和2026年规划。
过去几年的嘉年华活动,我们最大的重点是数据库客户,今年玩一些不一样的东西,增设了AI Coding、AI开源项目开放麦、开源社区集市等。现场除了社区用户外,还来了AI开源社区的伙伴和很多对AI感兴趣的开发者。社区的slogan——开源开放、生态共赢背后,增加了许多新的元素。
•生态共赢:世界很大, 我们期待结识更多的朋友,与AI生态上下游联合推出更有价值的解决方案。
•拥抱AI:培养开发者,寻找更多支持上层 AI 的机会点。
•出海:走出中国,面向世界,与开发者一起探索更多场景。
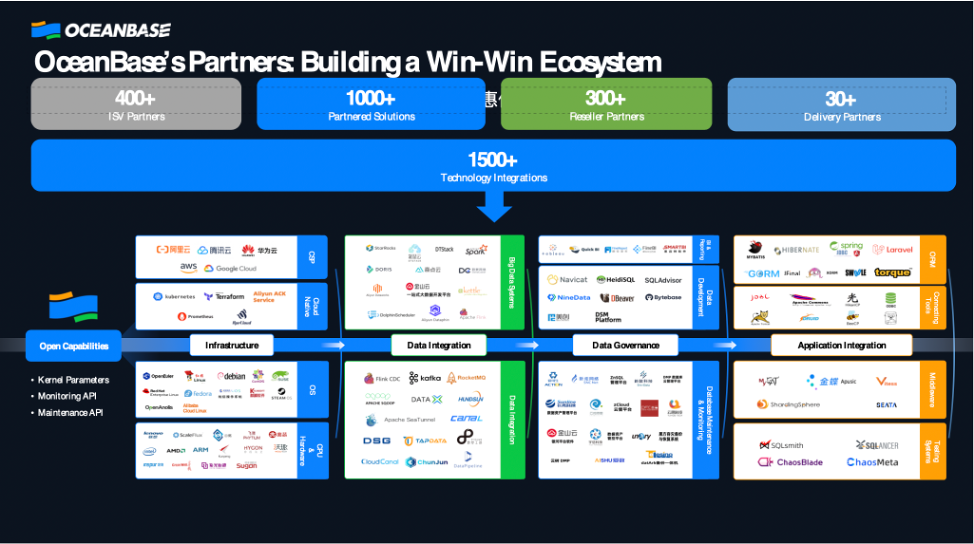
这张图片很少对外分享,但它的背后有一个非常有意思的事情:在招标或者竞标的时候这张图能够提升我们的核心竞争力。OceanBase对于企业来说是一个非常好的partner,因为它非常容易适配,已经有1600+多家技术厂商的系统和OceanBase完成了适配,大家可以在我们的官网或者Google查询。
今天有很多生态伙伴到场,特别感谢:RAGFlow、Dify、LangChain Community、FastGPT、Nowledge Labs、TEN Framework、CAMEL-AI 、Datawhale、蚂蚁百灵、refly、CeHive、Astron Agent、WasmEdge、Bonjour、pulsar、钉钉、爱可生开源、极星会、模力工厂、大创智等,希望在新的一年,一起愉快地玩耍。

在开发者侧,我分享几个特别有意思的事情。
第一点,近期seekdb的所有研发会切换到GitHub。
第二点,我们给大家准备了大量上手的issue,期望能够跟更多开发者共建。
第三点是我们即将要推出Data X AI的实战训练课程,期待与大家能够给一些建议和一起共创。
回到社区,我们在2026年将会主动与更多技术社区互动,定期邀请开发者走进OceanBase。

那么,为什么我们要做这些事情,以及为什么推出轻量化AI原生数据库——seekdb呢?
在AI时代,数据处理已显现出两个趋势。一是数据会越来越多,且走向融合;二是模型的融合,为了充分发挥数据的价值,模型的一些能力将逐渐沉淀到数据层或数据库中。在趋势之下,我们面临的挑战是数据SQL直接调用AI,以及AI怎么理解数据的问题。我们跟阿里、蚂蚁,以及行业内的用户交流AI 的深度理解。比如coding、travelagent、智能客服Agent等,当走进深水区的时候,它们对数据需求和理解不再是标量或向量,而是混合数据。这会带来接口、计算、存储方面的技术问题。
对于用户来说,使用方式会变,会做一些创新型业务;对公司来说,会让公司的成本下降,执行效率或者说运行效率提升。

今天大家都处于初级阶段,但是我们放眼业界前沿的公司,比如Oracle、Data bricks、Snowflake、MongoDB,发现大家都在探索一件事情:将数据模型的能力沉淀到数据底座上,有些是沉淀在数据库内核中,有些是沉淀在SDK中,有些是沉淀在强关联的上层系统中,如上下文工程中的Memory 系统。

基于这个技术趋势,我们在AI能力方面包括seekdb、PowerMem,在2026年有一些初步规划。
1.seekdb
我们昨天发布了对Mac系统的支持,坦白讲,原生支持Mac版是OceanBase一直想做的事情,大家知道为什么吗?因为OceanBase对所有硬件资源的掌控非常low level。为了追求性能,自己控制资源,比如内存管理、I/O管理、buffer管理,甚至cpu、numa、cgroup的管理等,以至于牺牲了一些系统适配性方面的能力。
seekdb的出现,让我们有机会原生支持Mac版本。希望大家能够玩起来,如果有什么问题可以提给我们,其他的功能点由于时间关系不详细介绍了,

特别分享一个TableFork的功能。这个功能非常有意思,而且能够在很多地方使用。比如最简单的,我们跟AI coding交流,它可以快速fork仓库;再比如RAG场景,可以支持多个版本,也可以针对不同的用户,提供不同的版本或内容。

在线业务升级的回滚方案也很有意思,假设我今天晚上要上线一个新的系统,万一表的DDL改坏了,我可以整个表回滚,也可以整个库回滚。其他的功能比如全链路压测,以及混搜和检索的增强,大家也可以做一些探索。
1.PowerMem
PowerMem是一个非常轻量的,可以说是薄薄的一层,来解决上下文工程中的记忆问题,能力也在逐渐增强。
AI 应用想真正“好用”,必须解决“记忆”问题——它得记得你是谁、说过什么、偏好什么,还要能在合适的时候把这些信息准确地拿出来用。OceanBase PowerMem就是为这个目标而生的智能记忆系统。它不是简单把聊天记录存起来,而是把对话里真正有价值的信息“提炼成记忆”:该新增就新增、冲突就更新、重复就合并,让记忆库始终准确、干净、可用。同时我们引入了认知科学里的艾宾浩斯遗忘曲线,让系统像人一样对信息做时间衰减和权重管理——重要的记得更久,不重要的自然淡出,避免“越用越乱”。
对于开发者来说,PowerMem 提供友好的接入方式,支持Python SDK/MCP/HTTP API Server等多种接入方式。更关键的是,它天然支持 Multi-Agent:每个 Agent 有自己的记忆空间,也可以按权限共享协作;在检索侧,我们用向量 + 全文 + 图的混合检索与多路召回策略,把“该想起什么”这件事做得更稳、更准。再加上千人千面用户画像和多模态记忆能力,真正把“长期记忆”变成 AI 产品可落地的基础设施。

接下来我们会沿着路线图持续推进:从能力完善、稳定性与可观测性,到提供可视化管控台和上下文工程闭环。我们的目标很简单:让每一个 AI 应用,都拥有可靠、可管理、可进化的记忆
最后,特别感谢社区每位成员的关注和贡献,宣布我们2026年的5位社区大使以及授予2025年31位版主荣誉,请我们的CTO日照上台颁奖。


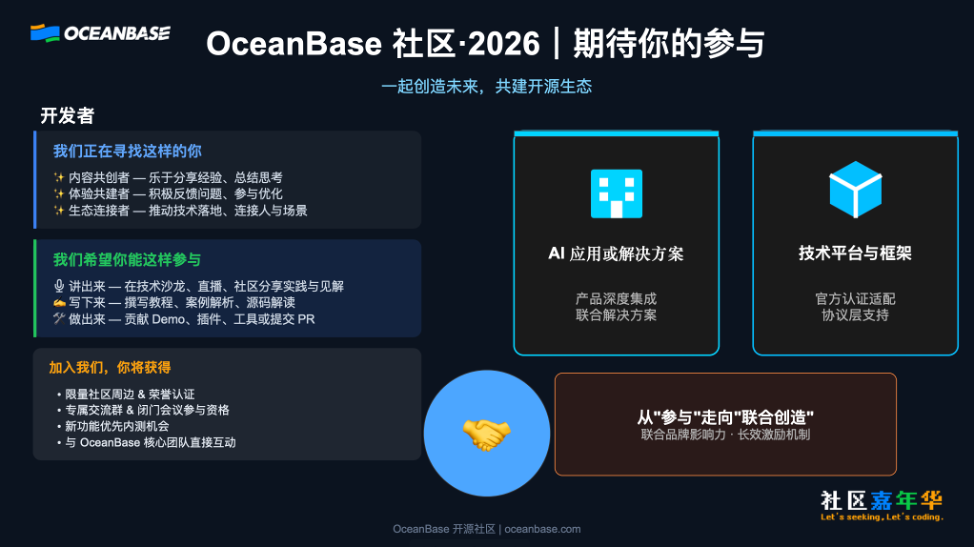
一起创造未来,共建开源生态
展望2026,我们将继续秉持开源初心,走向全球,与全球社区成员携手共进。期待在新的一年里,我们能共同推动更多技术创新,培育更丰富的社区生态,让开源精神在Data+AI领域绽放更耀眼的光芒。