

一、对你有什么帮助:了解技术背景是什么
本文 聚焦在传统电信,银行等企业
大版本(版本4.0 升级版本5.0)平滑升级过程中
-
新版本消息 发送老版本
-
老版本消息发送新版本
常见的三个问题
-
第一个问题: 消息类型不一致
-
第二个问题:消息结构体大小不一致
-
第三个问题:脑裂了。
前面通过 2个问题通过
-
自定义协议,预留字段
-
序列化(ENCODE/DECODE)
-
RPC:Golan Protobuf
期望是编译的时候静态检查,在执行之前避免问题。
本文主要描述第三个问题 脑裂怎么办?服务之间如何同步消息
净研究一些没用知识,
升级直接重启,服务不可用,如何,
我更期望希望的
如果实现代码自动化一键部署修改,来节省开发者成本,以人为本
这样的产品
#ContextO# 在设计之初解决了这个问题
ContextOS 通过集群化、模块化、自动化的方式,
只用一个 20M 大小的程序文件,
就可以在各种设备上,一键启动完整的云计算服务与云研发环境。
二、先把事情描述清楚:滚动升级遇到 脑裂怎么办?
-
多演练,多演练 ,多演练
-
在测试中发现问题,能描述清楚
-
本文聚焦在 测试期间发生的问题
-
下面是网络资料,请勿对标入号
-
下面的描述都是泛泛而谈,如果这样汇报绝对 被挨批一顿
无论是集中式文件系统还是数据库集群,要有效防范脑裂
分布式系统脑裂事故案例(来源网络)
| 技术栈 | 事故简述 | 核心原因 | 关键解决方案 |
| ------------------------------ | ---------------------------------------------------------------------- | ------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------------- |
| Redis 集群
(证券交易系统) | 跨机房光纤被挖断,导致网络分区,形成两个“主集群”,委托订单数据不一致。 | 网络分区导致哨兵误判主库下线,触发切换,形成双主。 | 1. 部署仲裁节点于第三独立区域。
2. 优化配置:缩短主节点超时时间,加快故障检测。
3. 配置写入保护:如 min-replicas-to-write,防止孤立主节点接受写请求。 |
| ZooKeeper 集群
(电商订单系统) | 大促期间网络分区,5节点集群分裂,形成两个独立子集群,导致分布式锁失效、订单重复处理。 | 网络分区后,子集群各自选举出Leader,且恢复后未能正确合并。 | 1. 遵循多数派原则:确保集群节点数(如3、5、7)能明确形成多数派,避免平票。
2. 完善监控与故障演练,建立系统性防御体系。 |
| 达梦数据库守护集群
(即时归档模式) | 心跳网络故障,且监控器部署在备库服务器上,导致监控器误判主库故障并触发切换,但数据不一致,备库无法打开,形成“双主”脑裂[^用户提供文章]。 | 1. 架构部署不当:监控器与数据节点同居,产生偏见判断。
2. 归档模式选择:即时归档模式在网络中断时易导致数据不一致的切换[^用户提供文章]。 | 1. 监控器独立部署:置于独立于主备的第三台服务器。
2. 更改归档模式:将“即时归档”改为“实时归档”,利用其 KEEP_RLOG_PKG 机制避免不必要的切换,增强自恢复能力[^用户提供文章]。 |
| 通用HA集群
(如Pacemaker) | 双节点集群联系中断后,双方争抢共享资源(如VIP、存储),导致服务混乱或数据损坏。 | 缺乏法定票数(Quorum):双节点无法形成多数派,任何一方失联都会导致状态误判。 | 1. 引入仲裁机制:使用第三方仲裁者(仲裁节点、共享盘)。
2. 避免单纯双节点:至少配置3个节点以满足法定票数。 |
GlusterFS与Oracle RAC脑裂案例对比(来源网络)
| 对比维度 | GlusterFS (分布式文件系统) | Oracle RAC (数据库集群) |
| ----------- | -------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------ |
| 典型事故场景 | 升级或重启时未停止服务,导致两节点复制卷数据不一致。 | 私有网络(Interconnect)故障或系统资源耗尽导致心跳超时,引发节点驱逐。 |
| 核心触发原因 | 网络分区与两副本无仲裁的脆弱架构,无法形成多数派决策。 | 网络心跳异常(如IPC发送超时),在双节点架构下同样面临平局风险。 |
| 关键现象 | 文件被标记为 “Is in split-brain”;文件属性显示副本间数据相互指责。 | 集群日志报错:CRS-1612(网络丢失)、CRS-1608(被驱逐)、ORA-29740(被成员逐出)。 |
| 解决方案与防护 | 1. 人工修复:使用 heal 命令指定权威副本强制同步。
2. 架构预防:生产环境必须使用三副本或引入仲裁卷(Arbiter),遵循多数派原则。 | 1. 自动仲裁:依赖投票盘(Voting Disk) 机制自动裁定幸存节点,并强制驱逐(Evict) 失败方。
2. 架构建议:采用 “2+1”跨站点部署,确保故障时拥有多数节点的站点存活。 |
请描述问题:
场景是什么
网络连接状态:
-
HA节点 ↔ 节点A:
 正常通讯
正常通讯 -
HA节点 ↔ 节点B:
正常通讯 -
节点A ↔ 节点B:
 无法直接通讯
无法直接通讯 -
节点A 和节点B 和其他节点
正常通讯
服务配置:
- 一个节点 多个网卡,节点A和节点B 链路中断 ,但是节点B可能与其他节点通讯正常
三、一次只解决一个问题:三个节点挂掉一个,还有2个不能解决你遇到实际问题
-
HA节点 ↔ 节点A:
正常通讯 -
HA节点 ↔ 节点B:
正常通讯 -
节点A ↔ 节点B:
无法直接通讯
如何解决
3.1 思路
-
一个节点是无法感受另外一个节点故障的,通过ping 心跳检测 都有缺陷,还有更多因素 如果依靠这样设计,问题越修改越多,还影响节点本身业务。
-
遇到难题,我解决不了,让别人 解决依靠独立高可用组件(HA 是高可用意思) 其他节点获取HA消息
-
高可用组件本身 支持选举
-
高可用组件实现方式 先可以不考虑raft,paxos高级方式,传统电信,银行 等软件没有采用这个方式
-
高可用组件(HA) 监控各种故障,节点故障,进程故障,网络故障,磁盘故障等
-
高可用组件(HA)异步通知 注意 一定异步通知。
假设:
HA负责故障发现,通知到每个节点,每个节点 根据自己业务做各自处理
3.2 ceph 升级过程中如何避免脑裂
升级顺序控制
Cephadm严格执行升级顺序以维护quorum:
-
mgr- Manager守护进程 -
mon- Monitor守护进程 -
crash- 崩溃收集模块 -
osd- OSD守护进程 -
mds- MDS守护进程
ceph mon 节点如何通知mds osd lib 获取其他节点故障?
- 在Ceph架构中,Monitor(MON)节点是集群状态信息的唯一权威来源和决策中心。
它并不直接、主动地向所有组件(如MDS、客户端)广播故障信息,
而是通过维护和更新一个统一的集群映射(Cluster Map)
-
MDS Map仅在启用CephFS(文件系统)时存在,它管理文件系统的元数据服务
-
OSD Map是Cluster Map中最核心、变化最频繁的部分之一,它描述了数据存储层的状态
-
Monitor Map记录了MON节点集群本身的成员信息和状态,是客户端找到集群入口的“通讯录
-
查询命令:ceph mon/mds/osd dump
Ceph 的故障通知机制是 基于版本化的映射扩散:
-
Monitor 作为真相来源,维护并广播集群状态
-
所有组件(OSD、MDS、客户端)主动订阅并缓存映射
-
通过递增 epoch 号确保状态一致性
-
结合推送和拉取确保及时更新
ceph 如何选举的
Ceph通过Monitor Quorum机制和Paxos算法来避免脑裂问题
When a Ceph Storage Cluster runs multiple Ceph Monitors for high availability,
Ceph Monitors use `Paxos`_ to establish consensus about the master cluster map.
A consensus requires a majority of monitors running to establish a quorum for
consensus about the cluster map (e.g., 1; 2 out of 3; 3 out of 5; 4 out of 6;
etc.).
3.2 oceanbase 升级过程中如何避免脑裂
- 成为OB贡献者(5):从一道OBCE再探Paxos

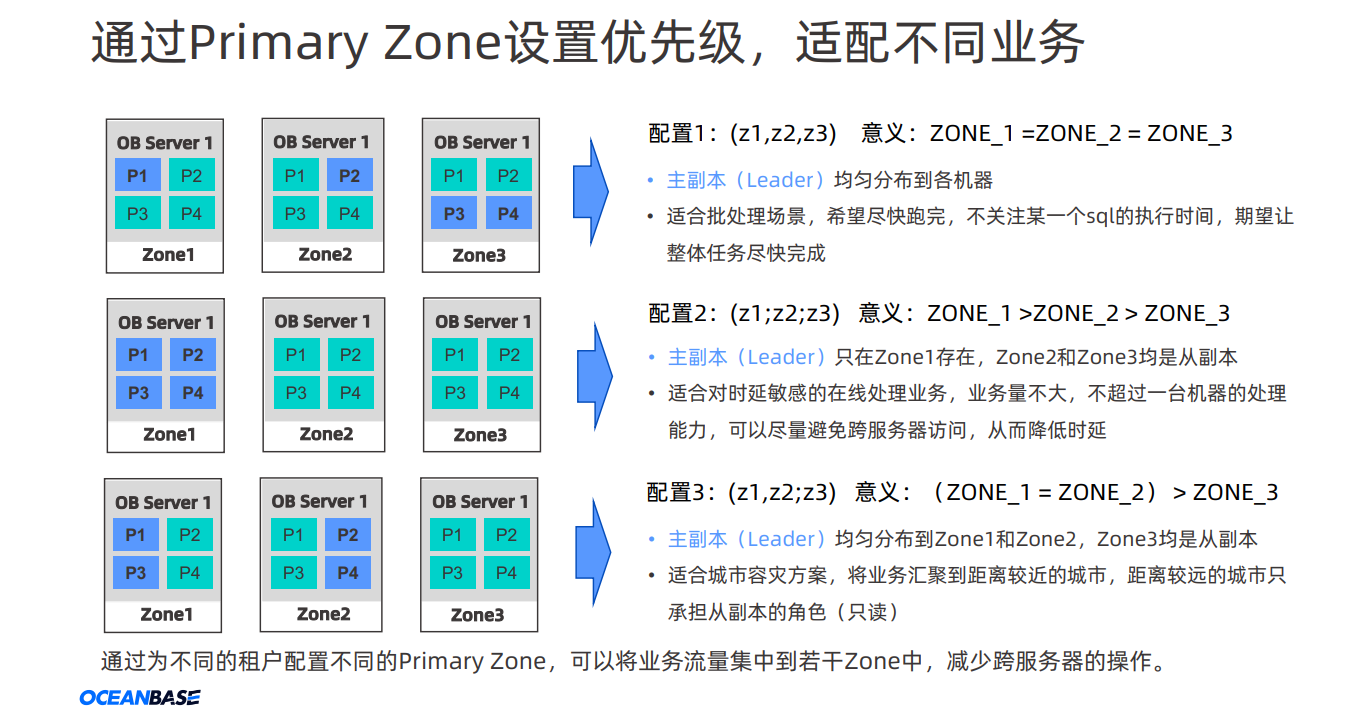
三地五中心部署模式
理解:C城市作用
如果C城市的节点失效,这将影响Paxos协议的多数派决策过程,因为C城市节点在投票过程中扮演重要角色
-
无法达成多数派共识:由于C城市节点的失效,如果A和B城市的节点之间无法形成多数派,那么在没有额外机制的情况下,系统将无法选出新的领导节点,这可能导致无法进行新的数据写入操作。
-
数据写入停滞:在Paxos协议中,新的数据写入需要多数派的同意。如果无法形成多数派,新的写入请求将无法执行,这可能导致业务中断
同类产品对比:
在Oracle ASM同城双活配置中,为了防止AB网络或机房中断导致的服务不可用,通常会引入第三方机房进行投票决策,这种配置也称为“仲裁”。
第三方机房的作用是在两个主要机房之间发生网络中断或其他故障时,提供决策支持,以确保系统的高可用性。
-
TiDB升级全流程与后问题深度排查:从平滑迁移到故障修复
3.3 Tidb 升级过程中如何避免脑裂
TiDB的高可用性核心依赖于Raft共识算法和PD(Placement Driver)集群。
-
Raft协议通过“多数派”原则和严格的Leader选举机制来避免脑裂。
-
PD集群作为整个TiDB集群的“大脑”,本身也是一个基于etcd(使用Raft协议)的高可用集群,通常由至少3个节点构
祝:
睡前关闭电子产品
你可能意识到 通过你眼睛看到手机视频画面就是整个世界
你可能意识到 通过耳朵听到手机声音 就是宇宙万物声音
你可能意识到 通过双手拿着手机温度 就是人间温度
错觉,手机不是世界,不是宇宙 更不是人间温暖
错误 手机就是残次品
低头拿着 才能看,必须手拿着才能看,必须 躺着 趴着,才能看
必须熬夜 才能看 每次看手机都是一次死亡
因为 手机拿着手机 手机绕过完美防御 ,1000G速度信息传送到大脑,你不收控制接受一切
因为 眼睛看着手机 画面 ,眼睛一眨不眨 思维停止,全部情绪 手机提供,24*h
因为 低头躺着拍着看手机 ,固定身体,固定你活动,一切提供购物,社交,哪怕拍摄真实内容,新闻 都是虚拟的。都是黑客帝国画面
下定决心:
努力不挣钱没关系,
关键不要赔上百万,千万,
熬夜看手机就是 对眼睛,无法恢复的伤害。
一个亿也无法挽回。
手碰一下手机,耳朵听手机声音,看手机屏幕,还是看消息内容
陷入这样 虚拟世界,
无论现实遇到什么问题,哪怕活不到好工作,好项目,好机会
哪怕什么都不懂,努力 0收入 赔上百万,千万都不重要。
都不超过1个亿,最后还是赚了。
2026 重启手机,重启人生
对你操作系统赋予新意义开启
不要独自一个人看手机,
我们常常陷入这样的场景:
独自一人时,在餐厅、地铁、卧室、沙发或书桌前,
当你躺在那里,趴在哪里,做在哪里时候,身体固定狭小空间,无法互动 ,不自觉地掏出手机。
身体被困在狭小的物理空间里,无法动弹,
只能目光便只能被那方寸屏幕牢牢吸引,
你行为被 多巴胺诱惑,简单舒服即使反馈奖励 ,被平台设计各种陷阱控制
除非拥有极强的意志力,根本不选择痛苦迟到的奖励
与其对抗本能,甚至平台 不如改变环境。
请选择去户外,去操场,视眼开阔 看手机。
请主动为你的手机使用选择更健康的场景
核心行动准则1:为特定场景设立无手机时间
-
进入公司开始工作时
-
下班回到家中时
-
在餐厅用餐或社交时
-
乘坐地铁通勤时
行动建议:
-
在上述场景开始时,立刻将手机放入书包或固定在某个位置(如抽屉)。
-
给自己设定一个专注时限,例如至少接下来的3小时内不主动查看。
-
这能有效打破“无聊就刷手机”的循环,把注意力还给当下的人和事。
核心行动准则2:换个开阔的地方看手机
-
早晨起床后
-
下班之后
-
周末时光
行动建议:
-
可以选择去图书馆、咖啡馆、商场中庭或景点休息区,公司园区,马路边
-
在这些具有公共生活感的场所使用手机,
-
周围的环境流动能天然地分散你对屏幕的过度专注,避免陷入无休止的刷屏。
一句话描述:
普通人最简单方式,重启自己操作系统
-
固定21点入睡:1 R90睡眠方案之所以能这样的世界顶尖运动员所青睐,每天晚上的睡眠规律你可以
-
固定6点起床:2 成不了作家 你可以打开笔记本写一行文字,3 做不出产品产品你打开软件写一行代码,4 无法演讲信服的话,你自己说一句话。5 成不运动健身达人 你走到运动走一步