【 使用环境 】生产环境
【 OB or 其他组件 】OB、OCP
【 使用版本 】OB 4.2.5.1,OCP 4.3.5
【问题描述】OCP创建备租户中间卡住不动,应该怎么处理?
【复现路径】创建备租户,主备同步方式:基于网络,备份集存储类型:COS
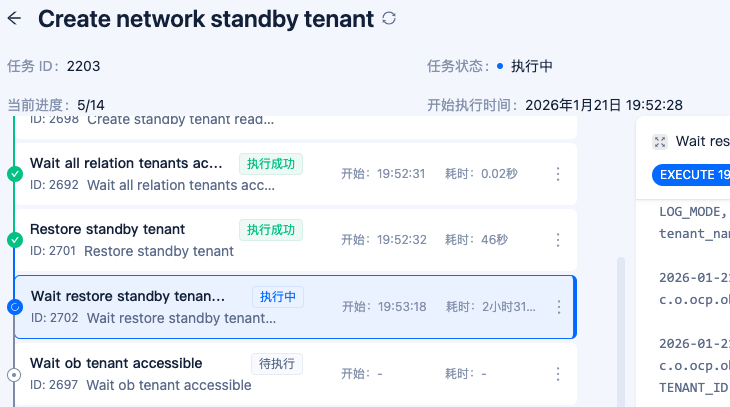
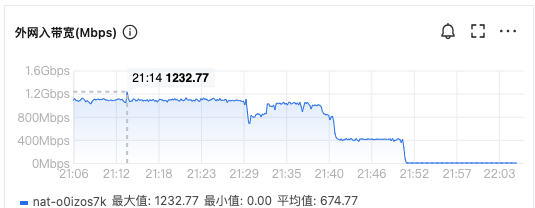
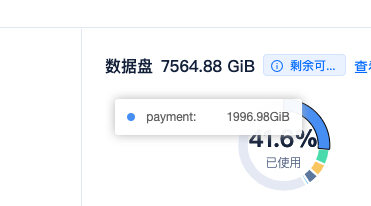
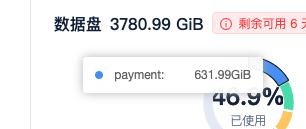
【日志】
[2026-01-21 21:50:09.780084] INFO New syslog file info: [address: “10.6.0.2:2882”, observer version: OceanBase_CE 4.2.5.1, revision: 101000092024120918-6388bc0561faecba5f75a662c6e11c3dd0598de9, sysname: Linux, os release: 6.6.110-42.4.tl4.x86_64, machine: x86_64, tz GMT offset: 08:00]
[2026-01-21 21:50:09.779878] INFO [RS] do_work (ob_common_ls_service.cpp:140) [3018370][T1017_COMMONLSS][T1017][YB420A060002-000648BF81552B02-0-0] [lt=19] [COMMON_LS_SERVICE] finish one round(ret=0, ret=“OB_SUCCESS”, tmp_ret=0, tmp_ret=“OB_SUCCESS”, idle_time_us=1000000)
[2026-01-21 21:50:09.779957] INFO [RS] report_sys_ls_recovery_stat_in_trans_ (ob_recovery_ls_service.cpp:1074) [2411241][T1012_RecLSSer][T1012][YB420A060002-000648C3D19519AB-0-0] [lt=2] report sys ls recovery stat(ret=0, ret=“OB_SUCCESS”, sync_scn={val:1769003409492243000, v:0}, only_update_readable_scn=true, tenant_info={tenant_id:1012, tenant_role:“STANDBY”, switchover_status:“NORMAL”, switchover_epoch:0, sync_scn:1769003409487988000, replayable_scn:1769003409487988000, readable_scn:1769003408986021000, recovery_until_scn:4611686018427387903, log_mode:“NOARCHIVELOG”, max_ls_id:1006}, ls_recovery_stat={tenant_id:1012, ls_id:{id:1}, sync_scn:{val:1769003409492243000, v:0}, readable_scn:{val:1769003408986021000, v:0}, create_scn:{val:1, v:0}, drop_scn:{val:1, v:0}, config_version_:{proposal_id:24, config_seq:2}}, comment=“iterate no log”)
[2026-01-21 21:50:09.780680] INFO [RS] report_sys_ls_recovery_stat_in_trans_ (ob_recovery_ls_service.cpp:1074) [1421889][T1004_RecLSSer][T1004][YB420A060002-000648C1BDA6E90C-0-0] [lt=2] report sys ls recovery stat(ret=0, ret=“OB_SUCCESS”, sync_scn={val:1769003409590455000, v:0}, only_update_readable_scn=false, tenant_info={tenant_id:1004, tenant_role:“STANDBY”, switchover_status:“NORMAL”, switchover_epoch:0, sync_scn:1769003409371461000, replayable_scn:1769003409371461000, readable_scn:1769003409213363000, recovery_until_scn:4611686018427387903, log_mode:“NOARCHIVELOG”, max_ls_id:1003}, ls_recovery_stat={tenant_id:1004, ls_id:{id:1}, sync_scn:{val:1769003409590455000, v:0}, readable_scn:{val:1769003409288119000, v:0}, create_scn:{val:1, v:0}, drop_scn:{val:1, v:0}, config_version_:{proposal_id:28, config_seq:2}}, comment=“iterate log end”)
[2026-01-21 21:50:09.781130] INFO [RS] do_work (ob_recovery_ls_service.cpp:169) [2411241][T1012_RecLSSer][T1012][YB420A060002-000648C3D19519AB-0-0] [lt=9] REACH SYSLOG RATE LIMIT [bandwidth]
[2026-01-21 21:50:09.782298] INFO [RS] report_sys_ls_recovery_stat_in_trans_ (ob_recovery_ls_service.cpp:1074) [3018191][T1018_RecLSSer][T1018][YB420A060002-000648BF81A926DB-0-0] [lt=1] report sys ls recovery stat(ret=0, ret=“OB_SUCCESS”, sync_scn={val:1769003409690864000, v:0}, only_update_readable_scn=false, tenant_info={tenant_id:1018, tenant_role:“STANDBY”, switchover_status:“NORMAL”, switchover_epoch:0, sync_scn:1769003409388568000, replayable_scn:1769003409388568000, readable_scn:1769003409165387000, recovery_until_scn:4611686018427387903, log_mode:“NOARCHIVELOG”, max_ls_id:1003}, ls_recovery_stat={tenant_id:1018, ls_id:{id:1}, sync_scn:{val:1769003409690864000, v:0}, readable_scn:{val:1769003409266802000, v:0}, create_scn:{val:1, v:0}, drop_scn:{val:1, v:0}, config_version_:{proposal_id:23, config_seq:2}}, comment=“iterate log end”)
[2026-01-21 21:50:09.789107] INFO [RS] do_work (ob_common_ls_service.cpp:140) [1239828][T1_COMMONLSSe][T1][YB420A060002-000648B951F7A507-0-0] [lt=14] REACH SYSLOG RATE LIMIT [bandwidth]
[2026-01-21 21:50:09.791233] WDIAG [RS] check_can_do_recovery_ (ob_tenant_thread_helper.cpp:321) [3372452][T1022_RecLSSer][T1022][YB420A060002-000648C2C754E90F-0-0] [lt=8][errcode=-4018] fail to get restore job(ret=-4018, tenant_id=1022)
[2026-01-21 21:50:09.791238] WDIAG [RS] do_work (ob_recovery_ls_service.cpp:156) [3372452][T1022_RecLSSer][T1022][YB420A060002-000648C2C754E90F-0-0] [lt=4][errcode=-4018] can not do recovery now(ret=-4018, ret=“OB_ENTRY_NOT_EXIST”, tenant_id_=1022)
[2026-01-21 21:50:09.827779] WDIAG [RS] check_can_do_recovery_ (ob_tenant_thread_helper.cpp:321) [3372453][T1022_RecLSSer][T1022][YB420A060002-000648C2C745BAB4-0-0] [lt=9][errcode=-4018] fail to get restore job(ret=-4018, tenant_id=1022)
[2026-01-21 21:50:09.827783] WDIAG [RS] do_work (ob_recovery_ls_service.cpp:156) [3372453][T1022_RecLSSer][T1022][YB420A060002-000648C2C745BAB4-0-0] [lt=3][errcode=-4018] can not do recovery now(ret=-4018, ret=“OB_ENTRY_NOT_EXIST”, tenant_id_=1022)
[2026-01-21 21:50:09.851481] INFO [RS] manage_heartbeat_ (ob_heartbeat_service.cpp:408) [1239904][T1_HBService][T1][YB420A060002-000648B951B62CA0-0-0] [lt=15] manage_heartbeat_ has finished one round(ret=0, ret=“OB_SUCCESS”)
[2026-01-21 21:50:09.852805] INFO [RS] do_work (ob_standby_schema_refresh_trigger.cpp:70) [2857398][T1016_StandbySc][T1016][YB420A060002-000648BE27055ACE-0-0] [lt=13] REACH SYSLOG RATE LIMIT [bandwidth]