

前言
随着AI技术的发展,LLM的迭代的数据正在降低,相对来说基于LLM周边的工具花样层出不穷,应用的多样性带来了底层工具的复杂性,比如有个业界知名的“拖拉拽”的工作流工具,数据库就需要关系型数据库、向量数据库、缓存数据库支撑,提升了业务复杂度同时也降低了硬件资源的利用率。
当我想着市面有没有一款数据库能够实现上面的功能的时候,我带着这个疑问搜索的时候,看到了OceanBase最新发布的seekdb,不仅能满足多模态存储的问题,产品是开源的,更更更吸引人的地方是资源占用率超级低,只需要1核2G内存就可以流畅体验。
最近在观察研发同事查询数据库来判断问题或执行SQL语句来解决某些问题时,消息不对称和不了解数据库系统的工作原理,不知道在哪个数据库执行的问题较多,造成了无效的工作量激增,给研发和运维的同事都造成了很多的困扰,以前测试了vanna将自然语言转化为SQL语言执行的场景和我的工作场景还有很大差距,线上系统需要经过堡垒机登录并且线上数据库众多,因此无法直接执行对应的sql语句。
基于以上的需求,使用SeekDB + LangChain 了一个自然语言转化为SQL语句,并自动发送邮件的agent。
一、 数据库基本环境准备
1.1 SeekDB部署
SeekDB 部署有多种方式,可以是rpm安装、源码安装、python包引用、docker安装等等。
基于兼容性和迁移方便两个方面考虑,我使用docker安装SeekDB 。
# docker run -d \
--name oceanbase-container \
-p 2881:2881 \
-v /opt/oceanbase/data:/var/lib/oceanbase \
--restart unless-stopped \
7e6795cf7427
# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
94e5a730f6bb 7e6795cf7427 "/root/start.sh" 5 weeks ago Up 6 hours 0.0.0.0:2881->2881/tcp oceanbase-container
这样一个SeekDB 就已经运行起来了。
1.2 连接SeekDB
SeekDB 可使用obclient连接或mysql客户端,默认的库是没有密码的,更方面开发人员快速开发迭代。
mysql -h127.0.0.1 -P2881 -uroot -p -Ddb_metadata
1.3 查看SeekDB信息并创建需要使用的对象
连接上数据库可以查看数据库版本和数据库当前连接信息。
mysql> select version();
+----------------------------------+
| version() |
+----------------------------------+
| 5.7.25-OceanBase SeekDB-v1.0.0.0 |
+----------------------------------+
1 row in set (0.01 sec)
mysql>
mysql> show processlist;
+------------+------+------------------+-------------+---------+------+--------+------------------+
| Id | User | Host | db | Command | Time | State | Info |
+------------+------+------------------+-------------+---------+------+--------+------------------+
| 3221674373 | root | 172.17.0.1:48658 | db_metadata | Query | 0 | ACTIVE | show processlist |
| 3221487776 | root | 127.0.0.1:57444 | ocs | Sleep | 1 | SLEEP | NULL |
+------------+------+------------------+-------------+---------+------+--------+------------------+
2 rows in set (0.01 sec)
本次我使用到的向量数据库功能包括向量、稀疏向量、全文检索索引;关系数据库功能包括普通表和json数据类型。
1.4 向量数据库功能
向量数据库主要保存数据的向量信息,使用向量相似度检索数据,找到语义相似的文档,项目中使用向量数据库主要是使用rag,保存一些经验总结的文档方便在agent中使用。
mysql> desc hybrid_search_demo;
+------------------+---------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------------+---------------+------+-----+---------+-------+
| id | varchar(4096) | NO | PRI | NULL | |
| embedding | VECTOR(2560) | YES | | NULL | |
| document | longtext | YES | | NULL | |
| metadata | json | YES | | NULL | |
| sparse_embedding | SPARSEVECTOR | YES | | NULL | |
| fulltext_content | longtext | YES | | NULL | |
+------------------+---------------+------+-----+---------+-------+
6 rows in set (0.00 sec)
mysql> show index from hybrid_search_demo
;
+--------------------+------------+-------------+--------------+------------------+-----------+-------------+----------+--------+------+------------+-----------+---------------+---------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+--------------------+------------+-------------+--------------+------------------+-----------+-------------+----------+--------+------+------------+-----------+---------------+---------+------------+
| hybrid_search_demo | 0 | PRIMARY | 1 | id | A | NULL | NULL | NULL | | BTREE | available | | YES | NULL |
| hybrid_search_demo | 1 | vidx | 1 | embedding | A | NULL | NULL | NULL | YES | VECTOR | available | | YES | NULL |
| hybrid_search_demo | 1 | vidx_fts | 1 | fulltext_content | A | NULL | NULL | NULL | YES | FULLTEXT | available | | YES | NULL |
| hybrid_search_demo | 1 | vidx_sparse | 1 | sparse_embedding | A | NULL | NULL | NULL | YES | VECTOR | available | | YES | NULL |
+--------------------+------------+-------------+--------------+------------------+-----------+-------------+----------+--------+------+------------+-----------+---------------+---------+------------+
4 rows in set (0.00 sec)
项目中使用的表中列包括:
- embedding:存储稠密向量,用于语义相似度搜索。
- document:存储原始文档内容,是搜索的“原始素材”。
- metadata:存储文档的元数据。
- sparse_embedding:存储稀疏向量,侧重于关键字权重匹配。
- fulltext_content:用于全文检索的文本内容,配合全文检索索引实现精准关键字搜索。
使用的索引包括:
- vidx:为稠密向量创建的索引,加速向量相似度计算。
- vidx_fts:为全文检索字段创建的索引,加速关键字全文搜索。
- vidx_sparse:加速稀疏向量的相似度搜索。
1.5 关系数据库表
mysql> desc db_metadata;
+-------------+----------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------------+----------------------+------+-----+---------+----------------+
| db_id | int(10) | NO | PRI | NULL | auto_increment |
| db_ip | varchar(20) | NO | | NULL | |
| db_port | smallint(5) unsigned | NO | | NULL | |
| server_name | varchar(20) | YES | | NULL | |
| tenant_name | varchar(20) | YES | | NULL | |
| db_type | varchar(20) | YES | | NULL | |
| db_comment | varchar(256) | YES | | NULL | |
+-------------+----------------------+------+-----+---------+----------------+
7 rows in set (0.00 sec)
mysql> desc table_metadata;
+---------------+----------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------------+----------------------+------+-----+---------+-------+
| db_ip | varchar(20) | NO | | NULL | |
| db_port | smallint(5) unsigned | NO | | NULL | |
| table_owner | varchar(50) | YES | | NULL | |
| table_name | varchar(50) | YES | | NULL | |
| column_meta | json | YES | | NULL | |
| index_meta | json | YES | | NULL | |
| table_comment | varchar(50) | YES | | NULL | |
+---------------+----------------------+------+-----+---------+-------+
7 rows in set (0.00 sec)
db_metadata表用于保存数据库元数据库信息,包括**数据库地址、端口、租户名、类型及提示信息,**用于保存线上数据库的所有数据库相关信息。
table_metadata表用于保存数据库中的表、列、数据类型、索引及提示信息,快速找到业务相关的表信息,用来生成业务的SQL语句;索引信息在SQL语句执行出现性能问题时提供优化支撑。
二、LangChain环境构建
LangChain v1 Agent 经架构重构实现生产级成熟度,以统一的 createAgent API 为核心,整合 LangGraph 提供底层支撑,精简命名空间保障版本兼容。核心强化中间件精细化管控、工具调用优化、多模态跨模型兼容及会话状态管理能力,可适配智能数据分析、企业级助手、多智能体协同等场景,兼顾低门槛开发、高灵活定制与生产级稳定性。
2.1 agent rag构建
- 在本项目中,RAG 模块基于已完成向量嵌入的知识库,快速检索并匹配与用户需求适配的 SQL 解决方案。有如下几个优势:速度快、消耗低、跨语言和生态统一等。
import os
from typing import List, Dict, Any, Optional
from langchain_ollama import OllamaEmbeddings
from langchain_core.documents import Document
from langchain_oceanbase.vectorstores import OceanbaseVectorStore
class SQLRAGKnowledgeBase:
"""基于OceanBase的动态SQL案例RAG知识库(可导入复用)"""
def __init__(
self,
ollama_base_url: str,
ob_connection_args: Dict[str, Any],
ollama_embed_model: str = "llama3",
ob_table_name: str = "hybrid_search_demo",
ob_embedding_dim: int = 768,
ob_vidx_metric_type: str = "l2",
drop_old: bool = False
):
# 初始化嵌入模型+维度适配
self.embeddings = OllamaEmbeddings(
base_url=ollama_base_url,
model=ollama_embed_model
)
self.embedding_dim = ob_embedding_dim
# 维度适配(解决模型维度与OB配置不匹配)
test_emb = self.embeddings.embed_query("测试")
self.actual_dim = len(test_emb)
print(f"📌 RAG嵌入模型实际维度:{self.actual_dim} | OB配置维度:{self.embedding_dim}")
if self.actual_dim != self.embedding_dim:
def adapt_embedding(text):
emb = self.embeddings.embed_query(text)
return emb[:self.embedding_dim] if len(emb) > self.embedding_dim else emb + [0.0]*(self.embedding_dim - len(emb))
self.embeddings.embed_query = adapt_embedding
# 验证OceanBase连接
try:
from sqlalchemy import create_engine
engine = create_engine(
f"mysql+pymysql://{ob_connection_args['user']}:{ob_connection_args['password']}@{ob_connection_args['host']}:{ob_connection_args['port']}/{ob_connection_args['dbname']}"
)
with engine.connect() as conn:
print("✅ OceanBase连接成功!")
except Exception as e:
print(f"❌ OB连接失败:{str(e)}")
raise
# 初始化OB向量存储
self.ob_vector_store = OceanbaseVectorStore(
embedding_function=self.embeddings,
table_name=ob_table_name,
connection_args=ob_connection_args,
vidx_metric_type=ob_vidx_metric_type,
include_sparse=True,
include_fulltext=True,
drop_old=drop_old,
embedding_dim=self.embedding_dim,
)
self.documents: List[Document] = []
print(f"✅ RAG知识库初始化完成(OB表:{ob_table_name})")
def _build_document(self, business_logic: str, sql: str, supplement: str = "") -> Document:
full_text_content = f"业务逻辑:{business_logic}\nSQL语句:{sql}\n补充信息:{supplement}".strip()
return Document(
page_content=full_text_content,
metadata={"business_logic": business_logic, "supplement": supplement, "sql": sql}
)
def insert(self, business_logic: str, sql: str, supplement: str = "") -> None:
"""插入SQL案例到OB知识库"""
new_doc = self._build_document(business_logic, sql, supplement)
self.documents.append(new_doc)
try:
self.ob_vector_store.add_documents(documents=[new_doc])
print(f"✅ 案例插入成功:{business_logic[:20]}...(累计{len(self.documents)}条)")
except Exception as e:
print(f"❌ 案例插入失败:{str(e)}")
raise
# 全局变量:存储初始化后的RAG知识库实例
rag_kb = None
def init_rag_kb(
ollama_base_url: str,
ob_connection_args: Dict[str, Any],
ollama_embed_model: str = "llama3",
ob_table_name: str = "hybrid_search_demo",
ob_embedding_dim: int = 768,
drop_old: bool = False
):
"""初始化RAG知识库(供外部调用)"""
global rag_kb
rag_kb = SQLRAGKnowledgeBase(
ollama_base_url=ollama_base_url,
ollama_embed_model=ollama_embed_model,
ob_connection_args=ob_connection_args,
ob_table_name=ob_table_name,
ob_embedding_dim=ob_embedding_dim,
drop_old=drop_old
)
return rag_kb
def search_sql_case_func(query: str, k: int = 3) -> str:
"""检索OB中的相似SQL案例(Agent调用的工具函数)"""
global rag_kb
print(f"\n🔍 开始检索相似SQL案例:{query[:50]}...")
if rag_kb is None:
return "❌ 检索失败:请先调用init_rag_kb初始化RAG知识库"
try:
ob_store = rag_kb.ob_vector_store
# 提取全文检索关键词(过滤无意义词汇)
fulltext_query = " ".join([
word for word in query.split()
if word not in ["查询", "删除", "系统", "中", "的", "含", "数据", "备份", "并", "把", "发到"]
])
# 混合全文+向量检索
matched_docs = ob_store.similarity_search_with_fulltext(
query=query,
fulltext_query=fulltext_query,
k=k
)
# 过滤低相似度案例(阈值0.7)
high_similar_docs = [doc for doc in matched_docs if doc.metadata.get('score', 0.0) >= 0.7]
if not high_similar_docs:
return "未找到相似的SQL案例,请基于表结构自行编写。"
# 格式化检索结果
formatted = ["=== 🔍 相似SQL案例(来自OceanBase RAG) ==="]
for i, doc in enumerate(high_similar_docs, 1):
formatted.append(f"\n【案例{i}】")
formatted.append(f"业务逻辑:{doc.metadata['business_logic']}")
formatted.append(f"SQL语句:\n```sql\n{doc.metadata['sql'].strip()}\n```")
formatted.append(f"补充信息:{doc.metadata['supplement']}")
return "\n".join(formatted)
except Exception as e:
return f"❌ 检索工具异常:{str(e)}"
2.2 基于SeekDB的混合搜索
代码基于 SeekDB 的核心能力重构检索逻辑,摒弃单一向量检索的局限性,充分发挥其「全文检索 + 向量语义检索」的融合优势:先通过全文检索快速过滤无关关键词,再通过向量检索精准匹配语义相似的 SQL 案例,并增设 0.7 相似度阈值过滤低质量结果,既提升了检索效率,又极大增强了 SQL 方案匹配的精准度。
2.3 tools工具
如果在rag中没有找到对应的SQL 案例,模型会转而使用元数据库中保存的线上数据库元数据信息自主生成SQL语句。这其中使用了多个tools实现,模型以React的模式运行,最终生成实现业务功能SQL语句。基于 LangChain 的BaseTool封装一套标准化的数据库元数据查询工具,支持多实例数据库列表查询、全量表信息查询、指定库表信息查询,并适配同步 / 异步调用,满足 Agent 工具链的使用需求。
代码中封装的工具集包含三个工具:
ListDbTool:列出所有数据库实例信息(IP、端口、类型、描述),适用于Agent 需要了解有哪些可用的数据库实例。
ListAllTableTool:列出所有数据库的全量表信息(表结构、字段、注释、索引),适用于Agent 需要全局了解所有表的结构。
ListSingleDbTableTool:查询指定 IP + 端口的数据库下的表信息,适用于Agent 聚焦单个数据库,需精准查询其表结构。
三、 实战效果
3.1 案例1(使用tools)
下面的案例提出了问题:在crm系统中删除所有VIP等级客户的信息,并把SQL发到135****5492@139.com。以下内容为agent的完整输出。
📌 RAG嵌入模型实际维度:2560 | OB配置维度:2560
✅ OceanBase连接成功!
✅ RAG知识库初始化完成(OB表:hybrid_search_demo)
🔍 开始检索相似SQL案例:删除VIP等级客户信息...
{'messages': [HumanMessage(content='在crm系统中删除所有VIP等级客户的信息,并把SQL发到135****5492@139.com', additional_kwargs={}, response_metadata={}, id='2e50c1a2-bffb-47b9-b79d-eb2a9cc5e97b'), AIMessage(content='', additional_kwargs={}, response_metadata={'model': 'qwen3:14b', 'created_at': '2026-01-20T04:11:30.451654164Z', 'done': True, 'done_reason': 'stop', 'total_duration': 13902457608, 'load_duration': 3704576678, 'prompt_eval_count': 1068, 'prompt_eval_duration': 385964077, 'eval_count': 625, 'eval_duration': 9684433204, 'logprobs': None, 'model_name': 'qwen3:14b', 'model_provider': 'ollama'}, id='lc_run--019bd999-88c4-7130-aec6-493c4ea2e259-0', tool_calls=[{'name': 'search_sql_case', 'args': {'k': 3, 'query': '删除VIP等级客户信息'}, 'id': '59f80e4f-5d6a-49c8-ba5a-b0f9fbfca9d4', 'type': 'tool_call'}], usage_metadata={'input_tokens': 1068, 'output_tokens': 625, 'total_tokens': 1693}), ToolMessage(content='未找到相似的SQL案例,请基于表结构自行编写。', name='search_sql_case', id='fe5fae00-12e3-469f-9e65-15b7d21873a1', tool_call_id='59f80e4f-5d6a-49c8-ba5a-b0f9fbfca9d4'), AIMessage(content='', additional_kwargs={}, response_metadata={'model': 'qwen3:14b', 'created_at': '2026-01-20T04:11:47.326200194Z', 'done': True, 'done_reason': 'stop', 'total_duration': 12147260707, 'load_duration': 3748750803, 'prompt_eval_count': 1121, 'prompt_eval_duration': 433091459, 'eval_count': 472, 'eval_duration': 7851548918, 'logprobs': None, 'model_name': 'qwen3:14b', 'model_provider': 'ollama'}, id='lc_run--019bd999-c62c-7640-88ef-e3f51856a7b8-0', tool_calls=[{'name': 'sql_db_list_db', 'args': {}, 'id': 'b4121504-6916-477d-8bce-bbad1d7a46c4', 'type': 'tool_call'}], usage_metadata={'input_tokens': 1121, 'output_tokens': 472, 'total_tokens': 1593}), ToolMessage(content='现网共有3 个数据库:
第1个数据库实例:192.168.9.224:2881
- 数据库类型:oceanbase
- 描述信息:学生管理系统数据库
第2个数据库实例:192.168.9.221:2881
- 数据库类型:oceanbase
- 描述信息:app1库
第3个数据库实例:192.168.56.200:2881
- 数据库类型:oracle
- 描述信息:CRM客户关系管理系统
', name='sql_db_list_db', id='d0fa3298-8237-441e-b7b6-82d80e142db5', tool_call_id='b4121504-6916-477d-8bce-bbad1d7a46c4'), AIMessage(content='', additional_kwargs={}, response_metadata={'model': 'qwen3:14b', 'created_at': '2026-01-20T04:11:52.990178261Z', 'done': True, 'done_reason': 'stop', 'total_duration': 5647784922, 'load_duration': 41196692, 'prompt_eval_count': 1294, 'prompt_eval_duration': 75778554, 'eval_count': 353, 'eval_duration': 5464200792, 'logprobs': None, 'model_name': 'qwen3:14b', 'model_provider': 'ollama'}, id='lc_run--019bd99a-010d-7c10-8a68-233a54059e2e-0', tool_calls=[{'name': 'list_single_db_table_tool', 'args': {'db_ip': '192.168.56.200', 'db_port': '2881'}, 'id': '727fe159-ad1e-4af5-a897-2990bb457d34', 'type': 'tool_call'}], usage_metadata={'input_tokens': 1294, 'output_tokens': 353, 'total_tokens': 1647}), ToolMessage(content='===== 数据库[192.168.56.200:2881]表信息 =====
该数据库下共有4张表:
【第1张表】
Schema:APP
表名:CRM_CUSTOMERS
表注释:CRM系统-客户基础信息表
字段数量:9
字段详情:
- CUSTOMER_ID NUMBER(10):客户唯一标识,主键
- CUSTOMER_NAME VARCHAR2(50):客户姓名
- GENDER CHAR(1):性别:M(男)、F(女)、U(未知)
- PHONE VARCHAR2(20):客户手机号,唯一约束
- EMAIL VARCHAR2(100):客户邮箱
- ADDRESS VARCHAR2(200):客户详细地址
- CREATE_TIME DATE:客户记录创建时间
- CUSTOMER_LEVEL VARCHAR2(20):客户等级:普通客户/VIP客户/钻石客户
- IS_VALID CHAR(1):客户状态:Y(有效)、N(无效)
------------------------------------------------------------
【第2张表】
Schema:APP
表名:CRM_EMPLOYEES
表注释:CRM系统-员工信息表
字段数量:7
字段详情:
- EMPLOYEE_ID NUMBER(10):员工唯一标识,主键
- EMPLOYEE_NAME VARCHAR2(50):员工姓名
- DEPARTMENT VARCHAR2(50):所属部门:销售部/客服部/技术部等
- POSITION VARCHAR2(50):员工职位
- PHONE VARCHAR2(20):员工手机号
- HIRE_DATE DATE:入职日期
- IS_ACTIVE CHAR(1):在职状态:Y(在职)、N(离职)
------------------------------------------------------------
【第3张表】
Schema:APP
表名:CRM_ORDERS
表注释:CRM系统-订单主表
字段数量:7
字段详情:
- ORDER_ID NUMBER(10):订单唯一标识,主键
- CUSTOMER_ID NUMBER(10):关联客户ID(关联app.crm_customers表)
- EMPLOYEE_ID NUMBER(10):关联员工ID(关联app.crm_employees表)
- ORDER_DATE DATE:下单时间
- TOTAL_AMOUNT NUMBER(12):订单总金额
- ORDER_STATUS VARCHAR2(20):订单状态:待支付/已支付/已发货/已完成/已取消
- PAY_METHOD VARCHAR2(20):支付方式:微信支付/支付宝/银行卡/现金
------------------------------------------------------------
【第4张表】
Schema:APP
表名:CRM_ORDER_ITEMS
表注释:CRM系统-订单明细表
字段数量:6
字段详情:
- ITEM_ID NUMBER(10):订单明细唯一标识,主键
- ORDER_ID NUMBER(10):关联订单ID(关联app.crm_orders表)
- PRODUCT_ID NUMBER(10):关联产品ID(关联crm_products表)
- QUANTITY NUMBER(5):购买数量
- UNIT_PRICE NUMBER(10):购买时的产品单价
- SUBTOTAL NUMBER(12):明细小计金额(quantity*unit_price)
------------------------------------------------------------', name='list_single_db_table_tool', id='9db0ad1d-1496-47e2-862b-7b3cb9d88ab7', tool_call_id='727fe159-ad1e-4af5-a897-2990bb457d34'), AIMessage(content='', additional_kwargs={}, response_metadata={'model': 'qwen3:14b', 'created_at': '2026-01-20T04:12:03.856869508Z', 'done': True, 'done_reason': 'stop', 'total_duration': 10851899841, 'load_duration': 38445030, 'prompt_eval_count': 2079, 'prompt_eval_duration': 286595019, 'eval_count': 655, 'eval_duration': 10393421277, 'logprobs': None, 'model_name': 'qwen3:14b', 'model_provider': 'ollama'}, id='lc_run--019bd99a-172c-7c63-9de6-9b994d58eaa2-0', tool_calls=[{'name': 'send_email', 'args': {'cc_emails': [], 'content': "业务需求:删除CRM系统中所有VIP等级客户的信息
执行数据库:192.168.56.200:2881
操作SQL:
-- 步骤1:创建临时表备份VIP客户数据
CREATE TABLE APP.CRM_CUSTOMERS_VIP_BACKUP AS
SELECT * FROM APP.CRM_CUSTOMERS
WHERE CUSTOMER_LEVEL = 'VIP客户';
-- 步骤2:删除VIP客户数据
DELETE FROM APP.CRM_CUSTOMERS
WHERE CUSTOMER_LEVEL = 'VIP客户';
-- 恢复方案:若需恢复数据,可执行以下语句
-- INSERT INTO APP.CRM_CUSTOMERS SELECT * FROM APP.CRM_CUSTOMERS_VIP_BACKUP;
-- DROP TABLE APP.CRM_CUSTOMERS_VIP_BACKUP;", 'content_type': 'plain', 'subject': 'CRM系统删除VIP客户数据操作', 'to_emails': ['13502445492@139.com']}, 'id': '5c1972e3-b4a0-4afd-90ed-d63ff338f000', 'type': 'tool_call'}], usage_metadata={'input_tokens': 2079, 'output_tokens': 655, 'total_tokens': 2734}), ToolMessage(content="✅ 邮件发送成功!
- 收件人:['13502445492@139.com']
- 服务器:smtp.163.com:465", name='send_email', id='7846da4d-cac7-40ad-b00c-ad558b771ec4', tool_call_id='5c1972e3-b4a0-4afd-90ed-d63ff338f000'), AIMessage(content='{'input_tokens': 2371, 'output_tokens': 474, 'total_tokens': 2845})]}
邮件信息如下
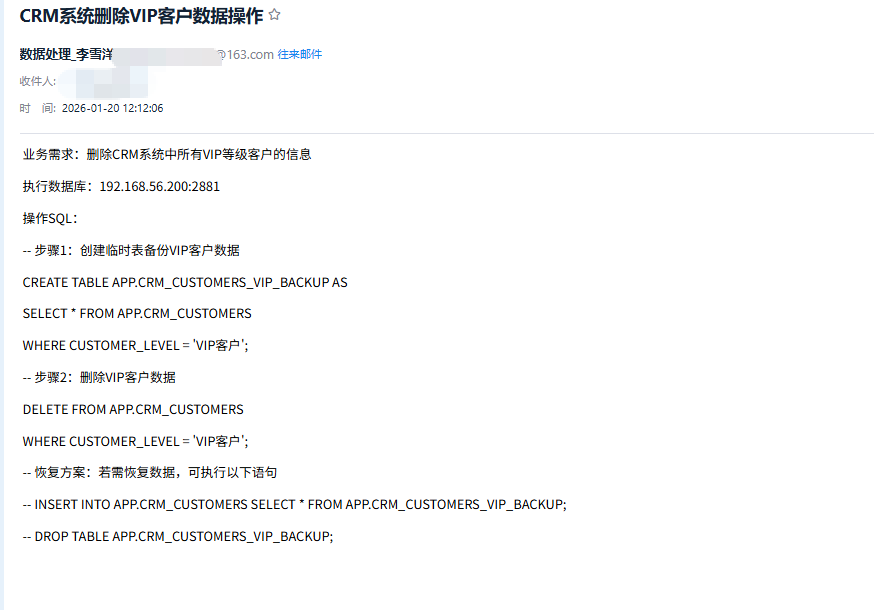
案例中没有在agent rag中找到类似的案例,因此使用tools查看元数据信息,最终生成SQL语句,并发送到了对应的邮箱。
整个系统基于 “LLM+RAG+Agent”,核心组件包括:
- LLM 层:基于 Ollama 部署的 qwen3:14b 模型,负责自然语言理解、SQL 生成、工具调度决策;
- RAG 层:以 OceanBase 为向量库,存储历史 SQL 案例,通过 “语义 + 全文” 混合检索匹配相似案例;
- Agent 层:LangChain Agent 作为核心调度器,管理自定义工具(元数据查询、RAG 检索、邮件发送);
3.2 案例2(使用agnet rag)
下面的案例提出了问题:查询CRM系统中VIP客户的已支付订单,包含客户、员工、订单信息。以下内容为agent的完整输出。
🔍 混合检索结果数:3
{'messages': [HumanMessage(content='查询CRM系统中VIP客户的已支付订单,包含客户、员工、订单信息', additional_kwargs={}, response_metadata={}, id='52d6600b-8428-4f81-92e8-5f353f156c4b'), AIMessage(content='', additional_kwargs={}, response_metadata={'model': 'qwen3:14b', 'created_at': '2026-01-20T09:45:17.793649369Z', 'done': True, 'done_reason': 'stop', 'total_duration': 14481259014, 'load_duration': 4015734716, 'prompt_eval_count': 1035, 'prompt_eval_duration': 401886454, 'eval_count': 586, 'eval_duration': 9925654265, 'logprobs': None, 'model_name': 'qwen3:14b', 'model_provider': 'ollama'}, id='lc_run--019bdacb-1e4f-71a2-99f1-f388f2cf364d-0', tool_calls=[{'name': 'search_sql_case', 'args': {'k': 3, 'query': '查询CRM系统中VIP客户的已支付订单,包含客户、员工、订单信息'}, 'id': 'cc3ce00d-73cb-49c5-8939-80b5ca67ac01', 'type': 'tool_call'}], usage_metadata={'input_tokens': 1035, 'output_tokens': 586, 'total_tokens': 1621}), ToolMessage(content="=== 🔍 OceanBase检索到的相似SQL案例 ===
【案例1】
业务逻辑:查询CRM系统中VIP客户的已支付订单,包含客户、员工、订单信息
SQL语句:
```sql
SELECT
c.customer_id, c.customer_name, c.vip_level,
e.employee_id, e.employee_name,
o.order_id, o.order_create_time, o.pay_status,
od.product_id, od.product_name, od.quantity, od.amount
FROM crm_customers c
LEFT JOIN crm_employee e ON c.follow_employee_id = e.employee_id
LEFT JOIN crm_orders o ON c.customer_id = o.customer_id
LEFT JOIN crm_order_details od ON o.order_id = od.order_id
WHERE c.vip_level IS NOT NULL
AND o.pay_status = '已支付'
ORDER BY o.order_create_time DESC;
补充信息:注意:1. 表名前缀为crm_;2. pay_status字段值为’已支付’才符合条件;3. 关联字段需确认无NULL值
【案例2】
业务逻辑:查询CRM系统中张三信息
SQL语句:
select * from crm_customers where EMPLOYEE_NAME = '张三';
补充信息:用户名张三是字符类型,注意数据类型转换问题
【案例3】
业务逻辑:查询CRM系统中张三信息
SQL语句:
select * from crm_customers where EMPLOYEE_NAME = '张三';
补充信息:用户名张三是字符类型,注意数据类型转换问题", name=‘search_sql_case’, id=‘9cdf39e3-f80e-4ced-ab88-367a8ed02c02’, tool_call_id=‘cc3ce00d-73cb-49c5-8939-80b5ca67ac01’), AIMessage(content="```sql
SELECT
c.customer_id, c.customer_name, c.vip_level,
e.employee_id, e.employee_name,
o.order_id, o.order_create_time, o.pay_status,
od.product_id, od.product_name, od.quantity, od.amount
FROM crm_customers c
LEFT JOIN crm_employee e ON c.follow_employee_id = e.employee_id
LEFT JOIN crm_orders o ON c.customer_id = o.customer_id
LEFT JOIN crm_order_details od ON o.order_id = od.order_id
WHERE c.vip_level IS NOT NULL
AND o.pay_status = ‘已支付’
ORDER BY o.order_create_time DESC;
**执行位置**:该SQL语句需在CRM系统的数据库实例上执行,建议连接以下数据库:
- IP地址:192.168.9.224
- 端口:2881
**说明**:
1. 表名前缀为`crm_`,字段如`vip_level`、`pay_status`等与案例描述一致
2. 通过`LEFT JOIN`关联客户、员工、订单及订单详情表
3. 过滤条件`pay_status = '已支付'`确保仅获取已支付订单
4. 结果按订单创建时间降序排列,便于查看最新订单", additional_kwargs={}, response_metadata={'model': 'qwen3:14b', 'created_at': '2026-01-20T09:45:34.905448075Z', 'done': True, 'done_reason': 'stop', 'total_duration': 14957874924, 'load_duration': 4045392756, 'prompt_eval_count': 1423, 'prompt_eval_duration': 540779854, 'eval_count': 585, 'eval_duration': 10236161279, 'logprobs': None, 'model_name': 'qwen3:14b', 'model_provider': 'ollama'}, id='lc_run--019bdacb-5f4a-7370-93ca-35d8a20aaa90-0', usage_metadata={'input_tokens': 1423, 'output_tokens': 585, 'total_tokens': 2008})]}
本案例中采用了SeekDB的“语义向量检索 + 全文关键词检索” 双引擎:
- 语义向量:将需求和案例转换成 2560 维向量,计算余弦相似度,确保 “语义匹配”;
- 全文关键词:检索CRM、VIP客户、已支付订单等核心关键词,避免因语义歧义漏检。
系统内置智能决策逻辑:
- 若 RAG 案例≥90% 匹配,且包含完整的表 / 字段 / 过滤逻辑,跳过冗余工具调用,直接生成 SQL;
- 若案例匹配度低(如删除 VIP 客户数据的需求),才触发 “查数据库→查表结构→生成 SQL” 的完整流程。
四、总结
在复杂的多数据库生产环境中,研发与运维之间因信息不对称而产生的沟通成本和操作风险,是一个长期存在的痛点。本文展示了一种创新的解决方案:通过将 OceanBase SeekDB 的多模态存储能力(关系型 + 向量 + 全文检索)与 LangChain Agent 的智能决策框架相结合,成功构建了一个能够理解自然语言、自主检索知识库、查询元数据并生成安全可靠 SQL 语句的智能助手。
这一方案不仅解决了“在哪执行”、“如何编写”的核心难题,更通过 RAG(检索增强生成)机制沉淀了团队的 SQL 编写经验,形成了可复用、可进化的知识资产。无论是直接复用历史案例,还是基于元数据动态生成新 SQL,Agent 都能确保操作的准确性和安全性,并通过邮件等工具无缝融入现有工作流。
实践证明,利用 “LLM + RAG + 多模态数据库” 的技术栈,可以有效弥合人与复杂系统之间的鸿沟,将繁琐、易错的手动查询过程,转变为高效、可靠的自动化服务,为团队提效和系统稳定保驾护航。
因社区字数限制,做了部分删减,如需查看完整内容请访问博客 用 OceanBase SeekDB + LangChain Agent 打造你的智能 SQL 助手-数据库技术博客-OceanBase分布式数据库