OBCE V4 来了 https://www.oceanbase.com/training/obce
对比V3有部分内容是大变化的,数据迁移在V4的OBCE课程中不再是单独一门课了。迁移有关的调整到了V4的OBCP课程中,也相对合理,迁移是偏工程实践,方法论参考V3版本的基本足够,发展到现在大部分人聚焦的更多是怎么用好(个人观点,不喜勿喷! ![]() )。
)。
整理了几张图,来快速看看OBCE V4版本有哪些内容,看看有哪些知识点是你平时工作常遇到的或者较关注,来留言讨论说一说,组队学习。

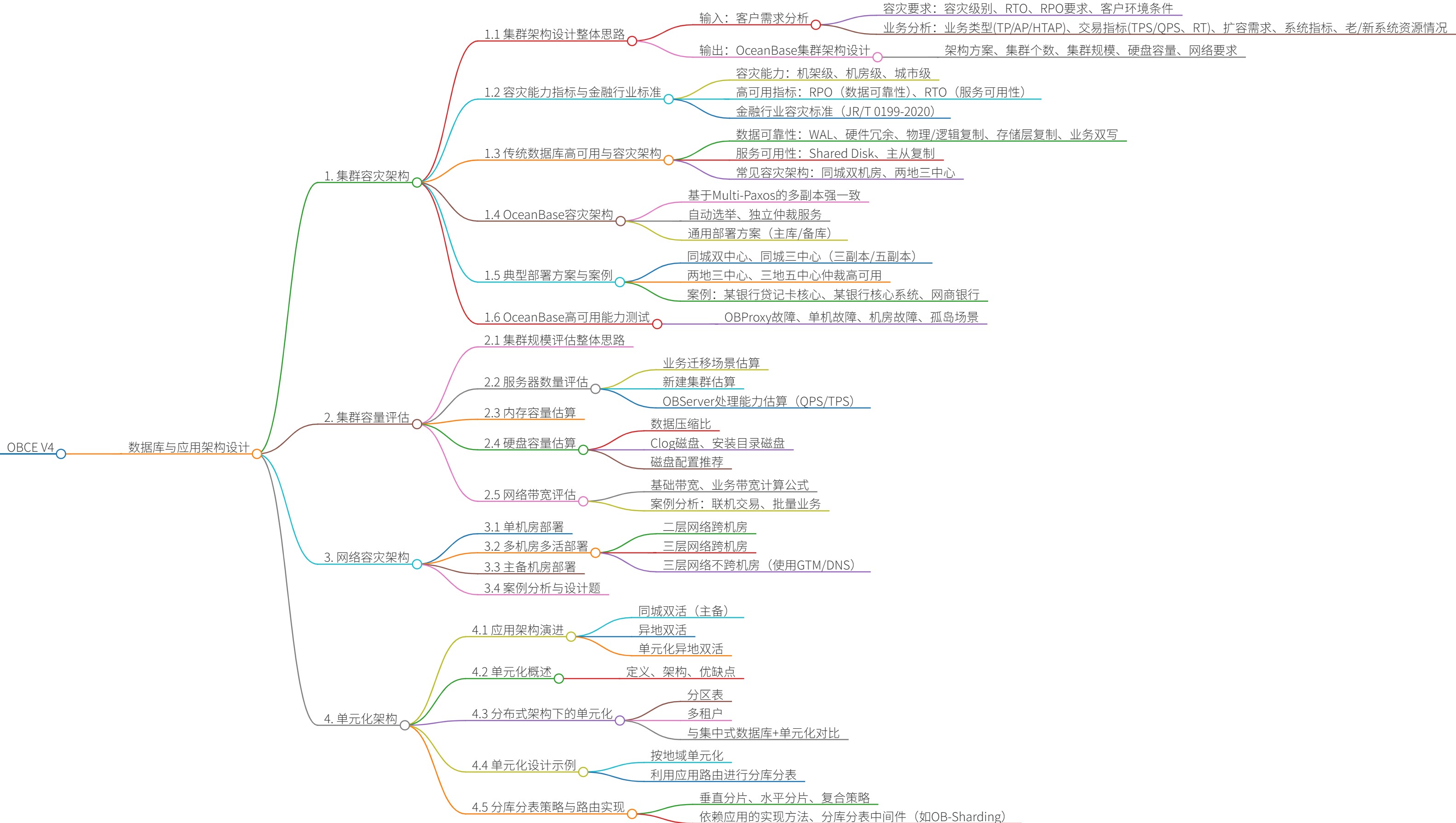
让你来做数据库与应用架构设计,您会想到哪些问题? 
- OceanBase如何实现同城双中心双活架构?
- 基于两套独立三副本集群,租户互为主备,通过Paxos协议保证RPO=0,支持机房级故障自动切换。
- 从Oracle迁移到OceanBase时,如何科学评估集群规模?
- 需结合旧系统CPU资源、业务增长倍数、CPU换算比、容灾倍数等因素,按单Zone逻辑核数推算总OBServer数量。
- 两地三中心五副本架构中,主城市故障后如何实现快速接管?
- 主城市4副本+备城市1副本组成Paxos组,主城故障时依赖剩余副本+仲裁服务降副本(5→3),备集群异步同步接管业务(RPO≈0)。
- 如何评估OceanBase生产环境的网络带宽需求?
- 需计算基础带宽(心跳、选举等)与业务带宽(Clog同步),并考虑日志压缩、业务峰值、批量导入等场景流量放大。
- 单元化架构中,分区表与分库分表如何选择?
- 分区表适合数据水平拆分、对业务透明;分库分表适合跨机房/城市访问优化、业务单元风险隔离与极致容量场景。
- 三地五中心仲裁架构如何降低部署成本并保证高可用?
- 采用4F(全功能副本)+1A(仲裁服务)部署,利用仲裁服务实现偶数副本容灾,减少硬件投入,支持城市级故障RTO<8秒。
- 金融行业容灾等级6级(RPO=0,RTO≤2分钟)如何通过OceanBase实现?
- 基于Multi-Paxos多副本强一致、自动选主与独立仲裁服务,实现数据零丢失与秒级故障恢复,支持远程集群自动切换。
- OB-Sharding在分库分表场景下如何保证路由效率与事务一致性?
- 通过SQL解析计算Sharding Key、改写路由,支持透明读写分离、分布式事务(如DTX),并集成OBProxy实现高可用与运维管控。
面对开发人常问的数据库应用最佳实践,您会想到哪些问题? 
1. 如何配置连接池参数才能兼顾性能和稳定性?
- 涉及参数:initialSize、maxActive、minIdle、maxWait等
- 关键点:根据业务峰值设置maxActive,设置validationQuery定期检查连接有效性
- 常见误区:盲目增大连接数导致数据库压力过大
2. Statement缓存和PreparedStatement缓存的区别和适用场景是什么?
- Statement缓存是连接级别的,只在同一连接内有效
- PreparedStatement缓存可以是连接池级别的,支持跨连接复用
- 调优参数:cachePrepStmts、prepStmtCacheSize
3. 批量操作应该选择Multi-Query还是ArrayBinding?
- Multi-Query适合文本协议,支持批量INSERT/UPDATE/DELETE
- ArrayBinding适合PS协议,Oracle模式特有,性能更优
- 关键配置:rewriteBatchedStatements、useServerPrepStmts
4. 大结果集查询时如何避免内存溢出?
- 流式结果集:FetchSize=Integer.MIN_VALUE
- 游标结果集:useCursorFetch=true,分批获取数据
- 全量结果集:仅适用于小数据量场景
5. LOB大对象读写性能差,如何优化?
- 根据数据大小选择INROW(<8K)或OUTROW存储
- 使用LOB Locator实现按需加载,避免一次性读取
- 配置参数:supportLobLocator、useLobLocatorV2
6. 分布式环境下如何实现负载均衡?
- 负载均衡策略:RANDOM、SERVERAFFINITY、ROTATION
- 黑名单机制:自动屏蔽异常节点
- 配置方式:URL参数或独立配置文件
7. 如何配置会话状态缓存提升性能?
- 参数useLocalSessionState控制是否缓存会话状态
- 缓存内容包括:自动提交状态、隔离级别、只读事务等
- 可减少与数据库的交互次数,提升事务处理性能
8. 批量操作超时或执行慢,如何排查?
- 检查ob_query_timeout参数是否足够
- 确认是否触发了Batch DML优化(is_batched_multi_stmt=1)
- 调整large_query_worker_percentage为大查询分配更多资源
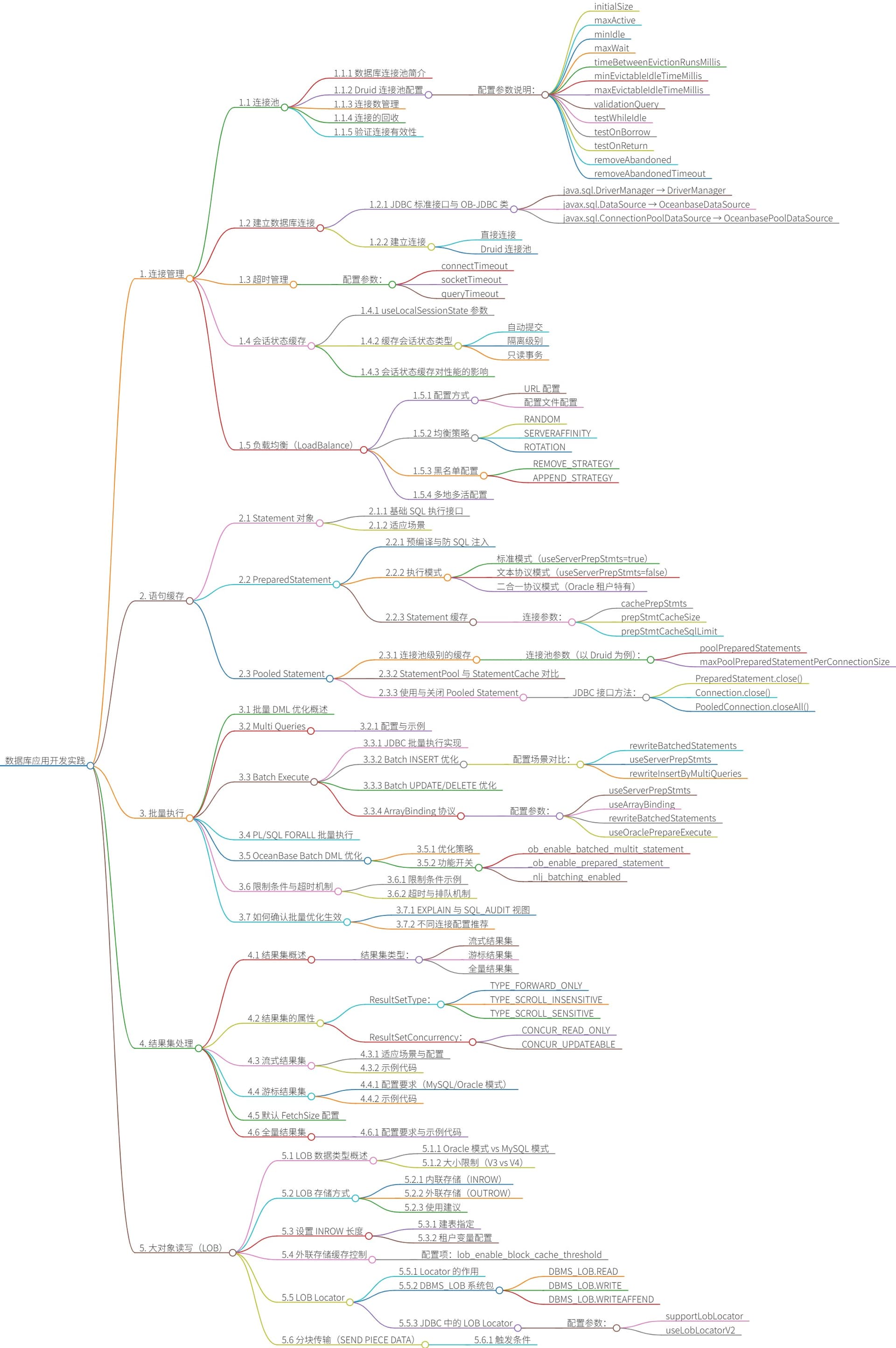
绕不开优化器原理与SQL调优,您会想到哪些问题? 
- 统计信息看起来准确,为什么优化器仍然选择了错误的执行计划?
- 涉及数据倾斜检测、直方图类型选择、动态采样机制
- 优化器在NLJ和Hash Join之间到底基于什么做选择?
- 核心是代价估算,涉及连接顺序、索引可用性、数据分布等多因素
- 分布式JOIN性能不佳时,应该从哪些方向优化?
- 数据分发策略选择(PKEY/HASH/BROADCAST)、Runtime Filter应用、Batch Rescan机制
- 分区表查询时快时慢,如何诊断?
- 静态/动态分区裁剪机制、分区键选择、数据倾斜的影响
- SPM开启后执行计划反而变差,如何处理?
- 基线计划质量、演进模式选择、与Hint/Outline的优先级关系
- 大IN LIST查询解析慢有什么优化手段?
- IN LIST改写阈值设置、VALUES TABLE转换机制
- 为什么有时候强制Hint不生效?
- Hint语法规范、QB_NAME使用、与优化器特性的兼容性
- 如何保证分页查询的稳定性?
- 排序唯一性要求、
_preserve_order_for_pagination配置
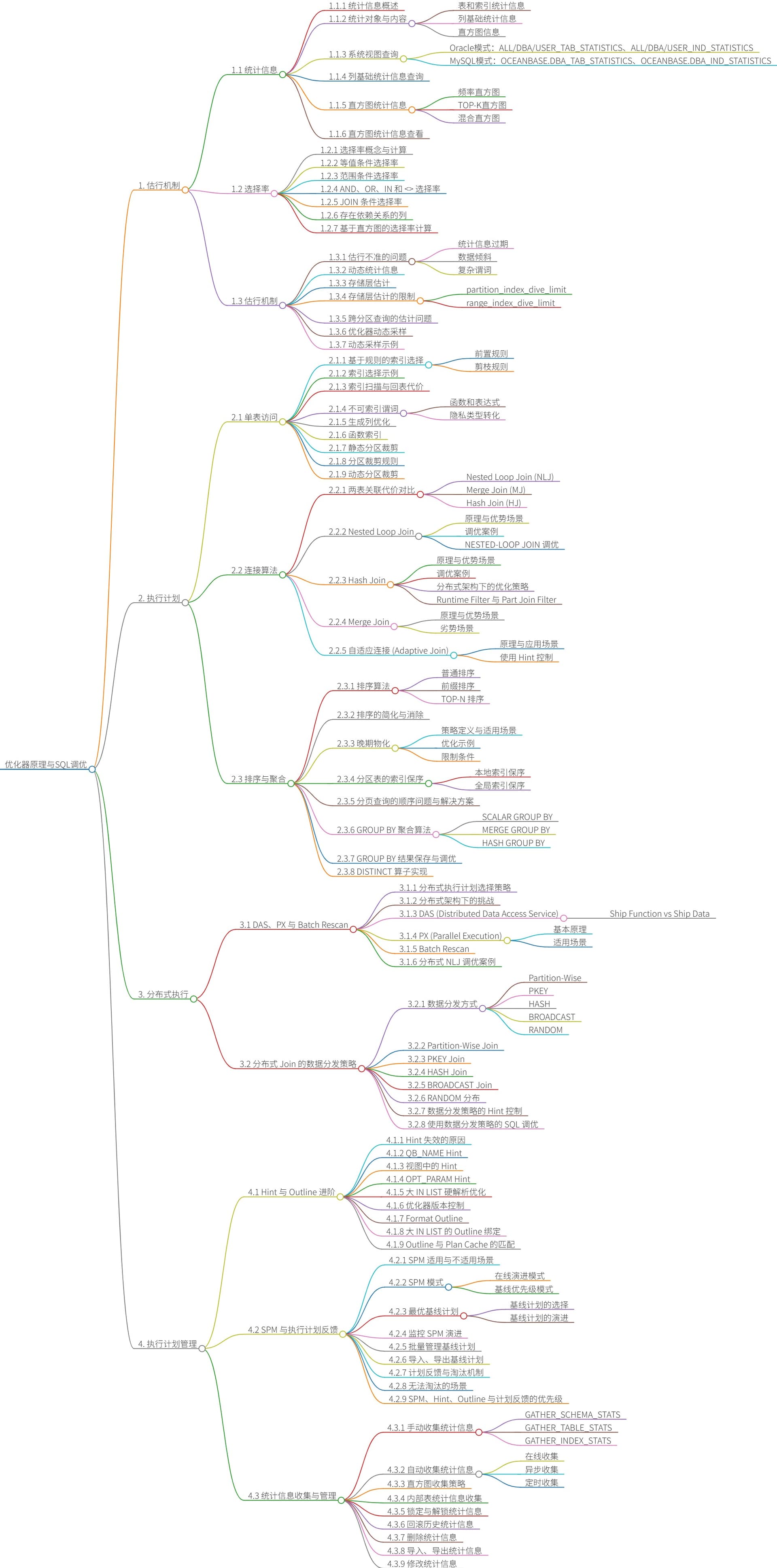
运维维护对于系统管理与调优,您会想到哪些问题? 
- 如何基于分区权重实现热点数据的负载均衡?
- 通过
DBMS_BALANCE.SET_BALANCE_WEIGHT为热点分区设置权重,结合贪心算法将权重大的分区分散到不同日志流,解决自动负载均衡无法识别访问热度的问题。
- 如何在同一租户内实现TP与AP业务的资源隔离?
- 通过创建资源组(
CREATE_CONSUMER_GROUP)、资源管理计划(CREATE_PLAN)及计划内容(CREATE_PLAN_DIRECTIVE),按User、SQL或Function粒度控制CPU与IOPS使用上限,避免混合负载相互干扰。
- 如何控制后台合并(Compaction)任务对前台业务的影响?
- 通过资源隔离机制为
COMPACTION_HIGH/MID/LOW等后台任务组设置MIN_IOPS、MAX_IOPS与CPU_WEIGHT,或调整compaction_low_thread_score等并发参数,限制其资源占用。
- 如何优化百万级分区表的合并性能?
- 调整
compaction_dag_cnt_limit、compaction_schedule_tablet_batch_cnt等调度参数,提升并发处理能力;同时通过资源隔离控制合并任务的IO与CPU使用。
- 如何评估并提升备份恢复任务的性能?
- 通过
ha_low_thread_score、log_archive_concurrency等参数控制备份并发度;利用sys_bkgd_net_percentage调整网络带宽占用;使用独立网卡分离备份流量,并通过ob_admin工具检测存储介质性能。
- 如何避免统计信息收集任务影响业务性能?
- 调整自动收集窗口至业务低峰期;通过资源隔离限制统计信息收集任务的CPU与IO使用;对大表采用并行收集、降低采样率或关闭直方图收集以缩短耗时。
- Online DDL与Offline DDL如何选择与优化?
- Online DDL(如加列、删列)不阻塞读写,适用于业务高峰期;Offline DDL(如修改主键、字符集)需重整数据,建议在维护窗口执行。可通过启用并行DDL(如
_parallel_ddl_control)与异步Schema刷新(_publish_schema_mode=async)提升批量DDL执行效率。
- 为大表创建索引时应如何规划资源与监控进度?
- 预先估算临时空间(全局索引约为索引大小的3~5倍);通过
PARALLELHint或Session变量设置并行度;通过资源隔离限制DDL任务的IO与CPU使用;通过GV$SESSION_LONGOPS实时监控创建进度与资源消耗。
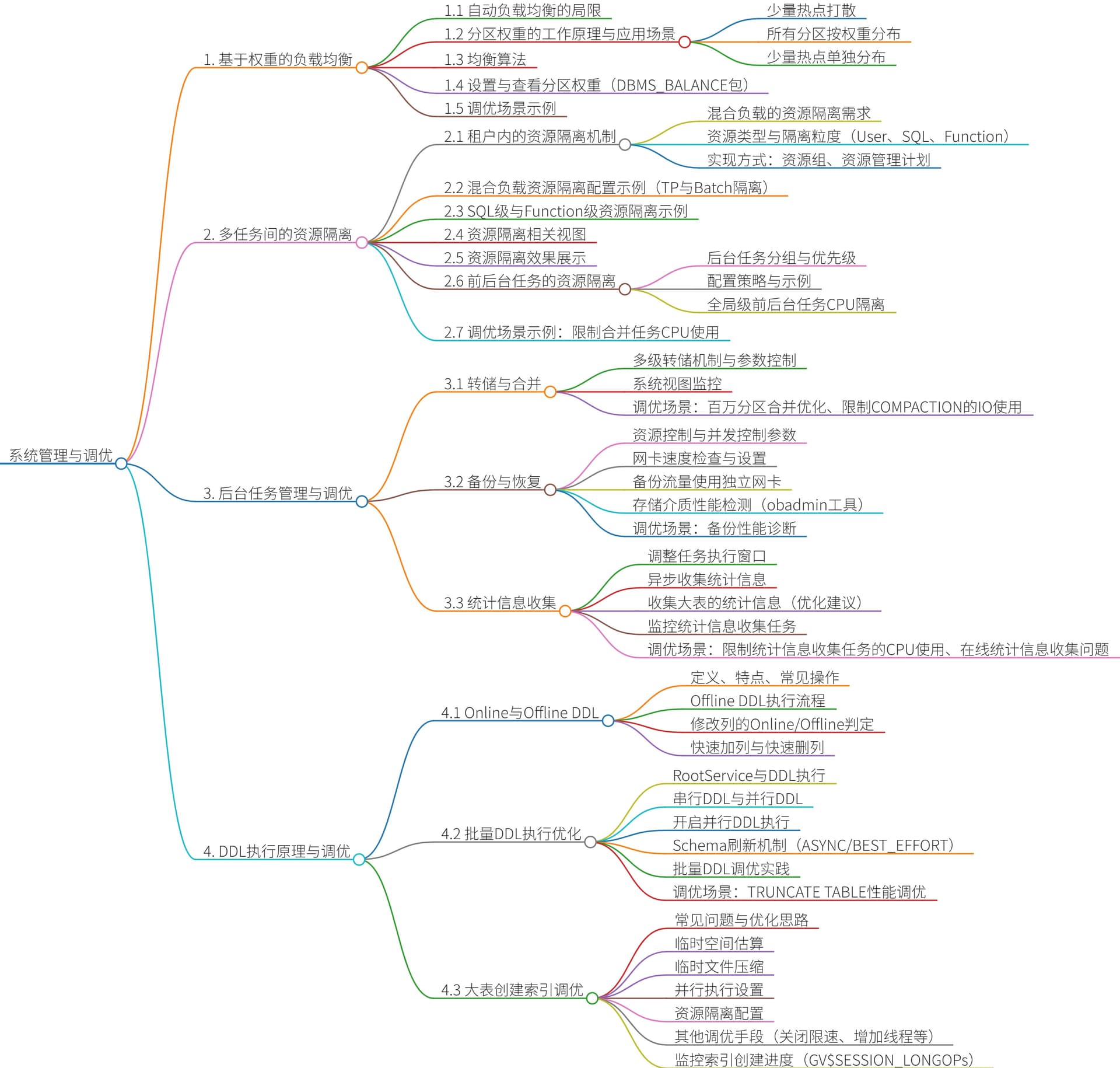
想了解数据高可用与容灾恢复,您会想到哪些问题? 
- OceanBase如何通过Multi-Paxos协议实现RPO=0的高可用?
- 基于Multi-Paxos协议实现多副本强一致日志同步,配合租约机制避免活锁与多主问题,确保少数派故障时数据不丢失、服务自动恢复(RTO<8s)。
- 仲裁服务(Arbitration)在容灾架构中起什么作用?如何部署与运维?
- 仲裁服务参与选举与成员变更投票,不存储数据,降低部署成本。通过
ALTER SYSTEM ADD ARBITRATION SERVICE部署,支持自动升降级(如4F1A降级为2F1A),并通过DBA_OB_ARBITRATION_SERVICE等视图监控状态。
- 主备租户(物理备库)如何实现日志同步与故障切换?
- 备租户通过日志传输服务(LTS)从主租户异步拉取Redo日志,基于RAW_WRITE模式持久化,通过日志回放服务(LRS)保持数据一致。支持Switchover(无损)与Failover(有损)切换,结合Service Name实现透明路由。
- 发生机房级故障时,OceanBase如何自动恢复服务?
- 依赖仲裁服务与剩余健康副本达成选举多数派,自动执行降级操作(如移出故障副本),修改Paxos成员数,确保剩余副本继续提供服务(RPO=0,RTO<8s)。故障恢复后支持自动或手动升级副本。
- 如何配置数据备份与日志归档以优化跨地域容灾?
- 通过
DATA_BACKUP_DEST与LOG_ARCHIVE_DEST设置备份源,结合region、idc属性将流量收敛在同机房;备份优先选择Follower,归档强制选择Leader,避免跨地域带宽消耗。
- 物理恢复租户时,如何实现原集群与跨集群恢复?
- 原集群恢复使用
ALTER SYSTEM RESTORE从备份与归档路径恢复至指定SCN/时间点;跨集群恢复需先通过PREVIEW获取所需backup_set与archive_piece,加载至目标集群后执行恢复。
- 表级恢复(Table-level Recovery)如何实现误操作数据修复?
- 通过创建辅助租户从备份恢复至指定时间点,再通过跨租户并行导入将目标表数据导回生产租户,支持表、分区、分区内三级并行,最小化恢复时间与资源占用。
- 高可用对于磁盘静默错误与坏盘故障如何检测与处理?
- 通过后台巡检线程周期校验宏块数据(
builtin_db_data_verify_cycle);日志盘与数据盘分别通过性能延迟与IO错误阈值触发预警并自动切主停服,可通过_all_virtual_disk_stat监控磁盘状态。
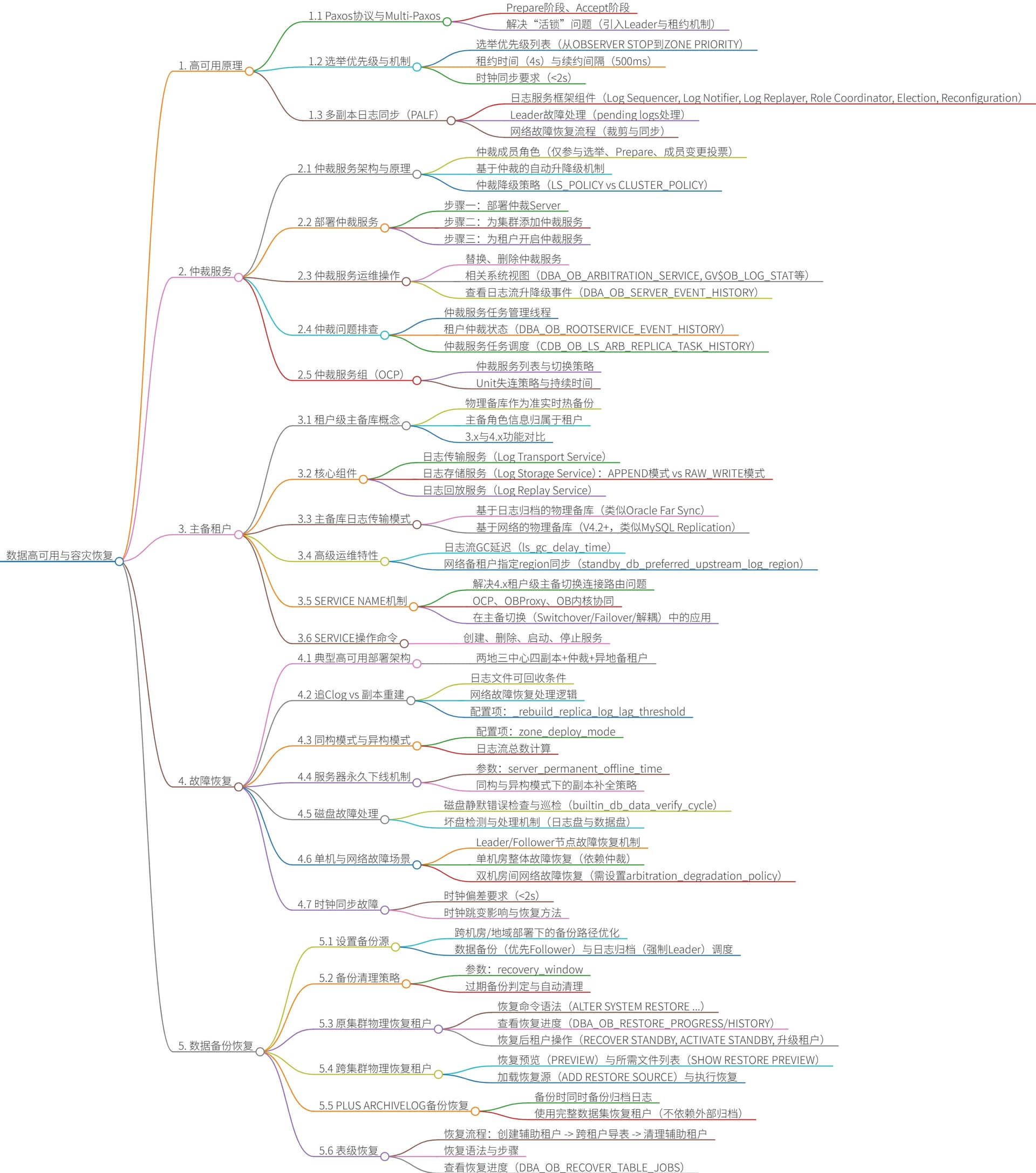
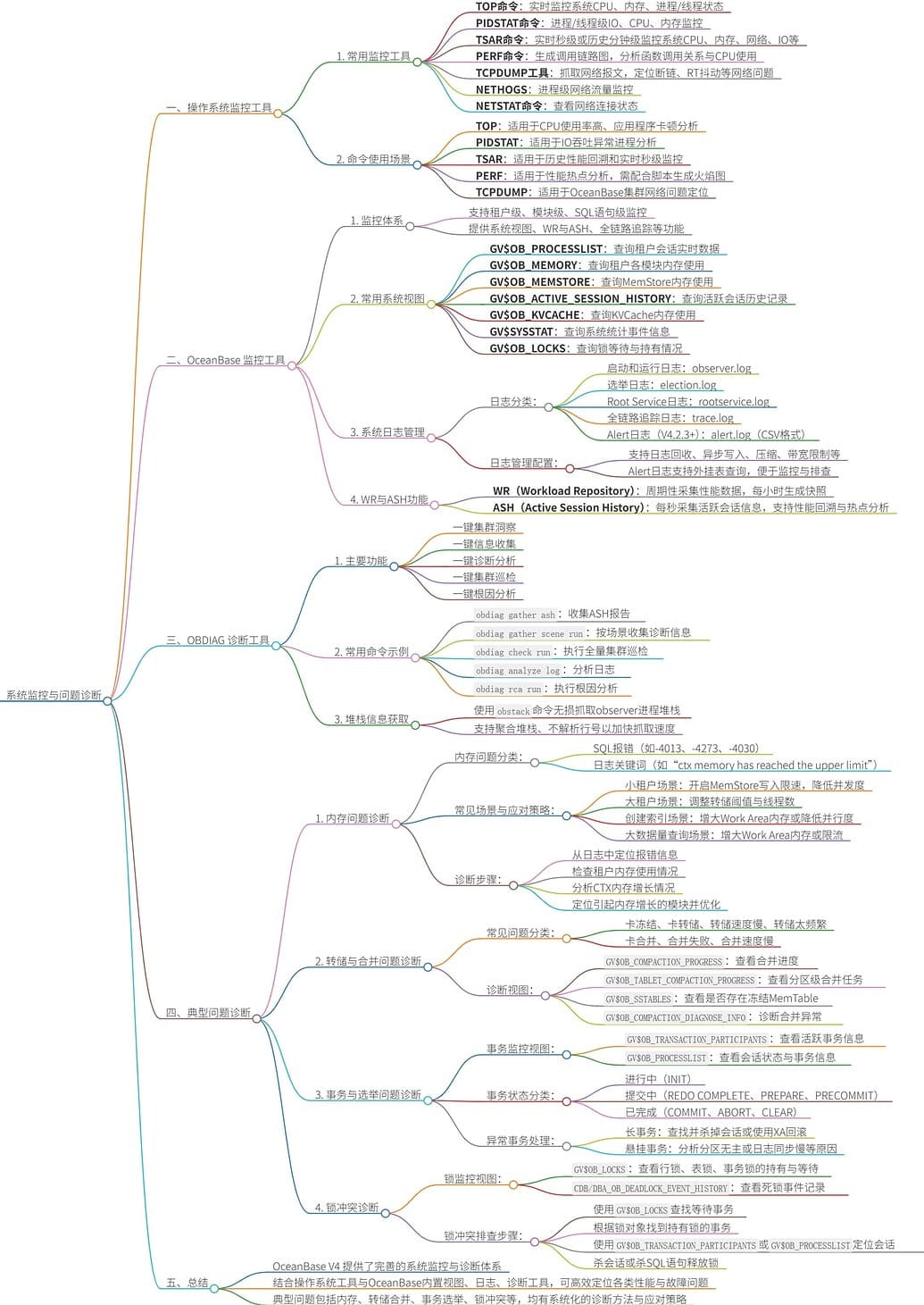
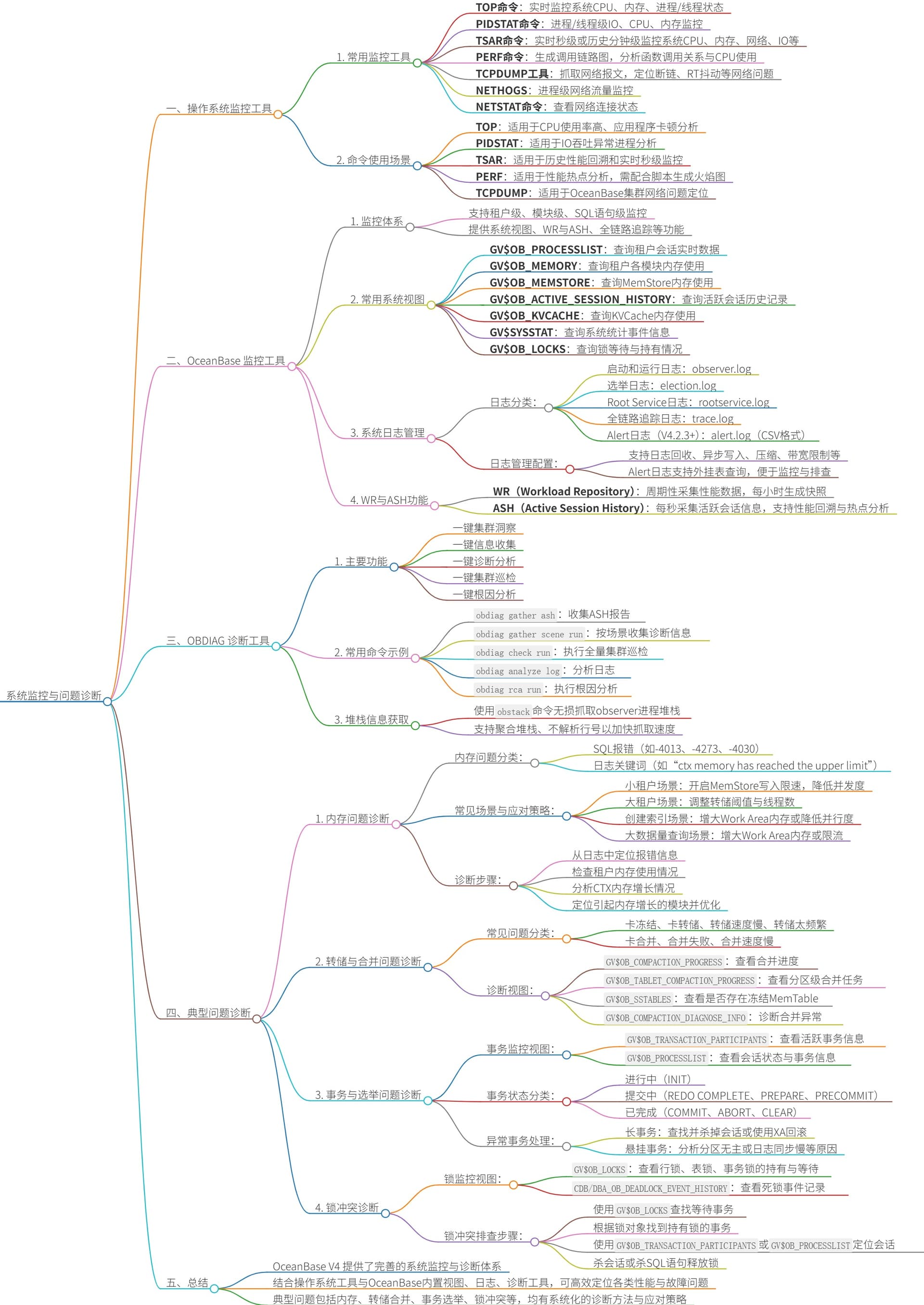
说到系统监控与问题诊断,你会关心哪些? 
- 如何构建OceanBase集群的系统级监控体系?
- 综合使用操作系统工具(如
top、tsar、pidstat、perf、tcpdump)与OceanBase内置监控视图(如GV$OB_PROCESSLIST、GV$OB_MEMORY),实现从硬件到数据库的全链路监控。
- 如何使用OceanBase系统视图定位性能瓶颈?
- 通过
GV$OB_PROCESSLIST实时查看会话SQL执行状态,结合GV$OB_ACTIVE_SESSION_HISTORY (ASH)回溯历史活跃会话,快速定位CPU、锁、IO等资源热点。
- 如何诊断和解决OceanBase内存使用异常问题?
- 利用
GV$OB_MEMORY、GV$OB_MEMSTORE等视图分析租户内存使用分布;通过日志关键词(如“alloc failed”、“OOPS”)定位内存泄漏或超限模块,并采取调整内存参数、优化SQL等应对策略。
- 如何监控和诊断转储与合并任务异常?
- 通过
GV$OB_COMPACTION_PROGRESS、CDB_OB_MAJOR_COMPACTION等视图查看任务进度与状态;结合GV$OB_COMPACTION_DIAGNOSE_INFO分析任务失败原因,如磁盘满、内存不足、SSTable数量超限等。
- 如何发现和处理OceanBase中的长事务与锁冲突?
- 使用
GV$OB_TRANSACTION_PARTICIPANTS监控事务状态与时长;通过GV$OB_LOCKS视图定位锁等待与死锁;结合日志分析事务超时或锁冲突根因,并采取杀会话、调优事务参数等措施。
- 如何利用obdiag工具进行一键式集群诊断与信息收集?
- 通过
obdiag gather ash收集ASH报告,obdiag gather scene按场景(如SQL性能问题)收集诊断包,支持一键集群洞察、巡检、日志分析与根因定位,提升运维效率。
- 如何通过Alert日志快速定位集群关键事件?
- Alert日志(
alert.log)以CSV格式记录关键INFO、WARN、ERROR事件,支持通过系统视图查询,便于监控集群启动、故障、资源告警等状态,辅助问题定界与恢复。
- 如何无损获取Observer进程堆栈以分析卡顿或死锁?
- 使用
obstack命令快速抓取Observer进程或热点线程的堆栈信息,避免pstack导致的进程挂起,适用于分析SQL执行卡顿、线程阻塞、死锁等现场问题。
- 如何监控和诊断选举与切主对事务的影响?
- 通过
DBA_OB_SERVER_EVENT_HISTORY查询选举事件,结合事务视图分析切主导致的会话超时、事务回滚等问题,理解有主改选、无主选举等场景下的业务表现与应对策略。
- 如何配置和管理OceanBase系统日志以支持高效诊断?
- 通过配置项(如
syslog_io_bandwidth_limit、enable_syslog_recycle)控制日志输出、压缩与回收策略,确保在问题发生时能获取完整、有效的诊断信息,同时避免日志膨胀影响性能。
后续有空再来看看大家讨论的是啥,待续......

如果还在看OBCP的下面帖子一键过去,把模拟题扫一扫,过了的来OBCE组队学习 ![]()