Giant
#1
【 使用环境 】生产环境 or 测试环境
【 OB or 其他组件 】
【 使用版本 】
【问题描述】清晰明确描述问题
【复现路径】问题出现前后相关操作
【附件及日志】推荐使用OceanBase敏捷诊断工具obdiag收集诊断信息,详情参见链接(右键跳转查看):
【SOP系列 22 】——故障诊断第一步(自助诊断和诊断信息收集)
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手] 即可召唤小助手,欢迎试用!
enable_rebalance=true
enable_tranfer=true
partition_balance_interval_schedule=2h
server_balance_disk_tolerance_percent=1
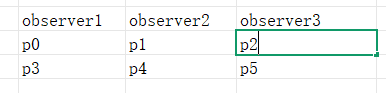
如果 p0,p1,p2,p3,p4 都是 30G p5 是600G。
疑问1.
会不会把p2 移走,那样分区数不在均衡了???
4 个赞
论坛小助手
#3
在您提到的情况下,OceanBase 会尝试通过数据迁移来保持各服务器之间的数据分布均衡,特别是在设置了 enable_rebalance=true 和 enable_transfer=true 的情况下。但是,您的问题涉及到了特定的分区大小差异和磁盘平衡容忍度设置。为了准确地了解这种情况下的行为,我们可以利用 obdiag 工具来收集相关信息,尤其是关于 unit 数据不平衡的诊断信息。
日志采集场景: unit迁移/缩小 副本不均衡问题
日志采集命令: obdiag gather scene run --scene=observer.unit_data_imbalance
请您先使用上述命令收集日志并提供给我们,这将有助于我们分析您的 OceanBase 集群中的数据分布情况及迁移策略。同时,为了更全面地理解您的环境,请您提供以下信息:
- 您当前使用的 OceanBase 版本是什么?
- 集群中服务器的磁盘空间使用率是多少?是否有接近满载的情况?
- 在设置这些参数之前,您是否观察到了任何明显的磁盘使用不均现象?
- 您是否有手动触发过 rebalance 操作,如果有,请说明时间及操作细节。
- 当前集群的负载情况如何?是否存在高并发写入或查询?
- 是否有其他相关的配置项可能影响数据迁移的行为?
这些信息将帮助我们更精确地诊断问题,为您提供有效的解决方案。感谢您的配合!
附上敏捷诊断工具 obdiag 使用帮助链接
2 个赞
辞霜
#4
会进行均衡任务,均衡优先级分区数>磁盘均衡。之前有遇到过表分区大小相差大导致均衡任务不结束反复进行分区迁移问题。建议尽量保持分区大小不要相差太大
1 个赞
辞霜
#5
balancer_tolerance_percentage(单元级磁盘均衡容忍度)
-
参数名:balancer_tolerance_percentage
-
默认值:10%
-
取值范围:[1, 100)(百分比)
-
作用范围:单元(Unit)之间的磁盘空间均衡
-
说明:
-
指定所有单元之间磁盘空间利用率不平衡的容忍度
-
平均磁盘空间利用率 = 总空间 / 单元数量
-
当任意单元的磁盘空间超出平均使用率的 ±10% 时,系统会启动重均衡任务
-
示例:如果设置为 10,且租户有 2 个单元,平均每个单元应使用约 50% 的总值。当某个单元的磁盘空间超出平均使用率的 ±10% 时,会触发重均衡
2 个赞
Giant
#7
新版本 有增加了 分区权重, 他们的 优先级呢 ??
包含 unit迁移 日志流迁移 分区权重迁移 分区数迁移 分区磁盘触发迁移 的优先级。
负载均衡优先级:
租户间的负载均衡(unit) > 租户内日志流的负载均衡 > 分区权重的负载均衡(热点数据) > 分区数量的负载均衡 > 分区磁盘大小的负载均衡
您看下对不对呢 ???
辞霜
#8
分区均衡策略的优先级顺序如下:分区属性对齐(table group对齐) > 分区数量均衡 > 分区磁盘均衡
Giant
#11

设置权重了 , 材料上 应该 比 分区数量优先级高吧??
这个充分说明 权重大于 分区数量吧?
1 个赞
Giant
#13
但是一个表的一级分区 明显是一个均衡组, 集群也是根据均衡组进行均衡的 , 一个均衡组都无法实现均衡,集群肯定不均衡吧。 我认为均衡组是均衡的最小单位。
帮忙确认下,如果一级分区均衡组都设置了权重, 优先级是不是大于 每个observer上或者日志流的分区数均衡??? 谢谢
辞霜
#14
均衡组(Balance Group)本身没有直接的权重。权重在分区
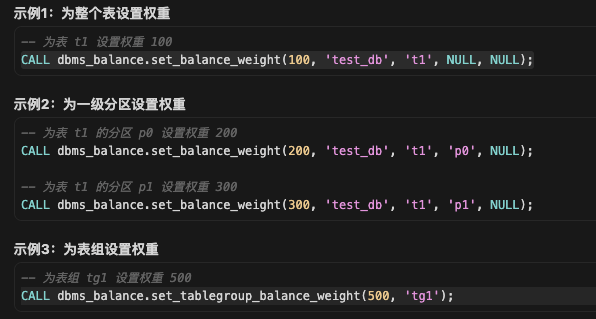
分区属性对齐(table group对齐) > 分区数量均衡 > 分区磁盘均衡
对于OceanBase问题,除了文中提到的方法,还可以考虑obdiag和enable的结合使用。


