

集群的observer日志一直在滚动报错renameat failed,报错路径的属主、权限和可用空间均没有问题,尝试在报错路径下新建文件后修改文件名也没有问题,这是什么原因。
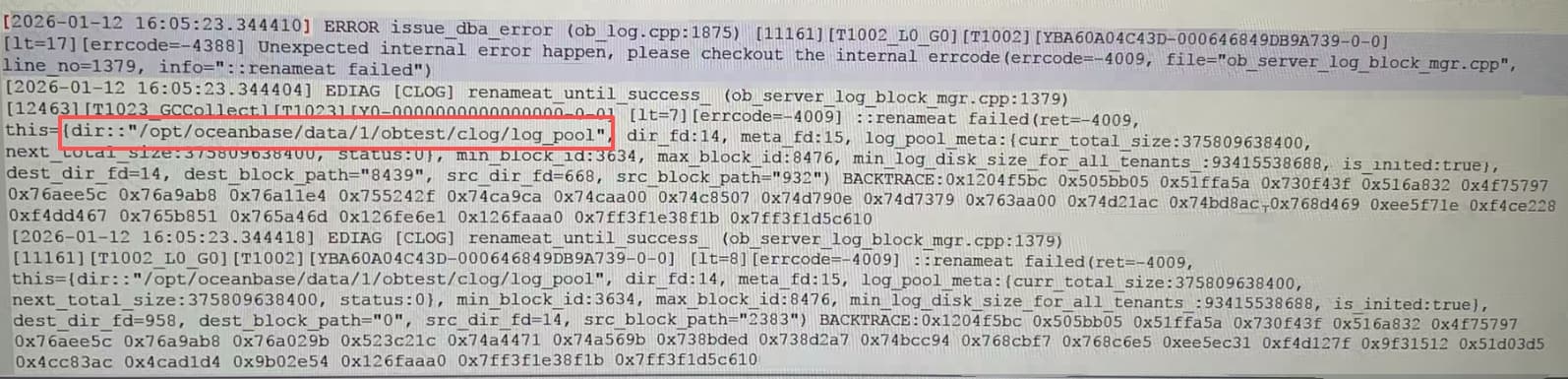
看下磁盘空间
df -h /opt/oceanbase/data/
检查 clog 目录大小
du -sh /opt/oceanbase/data/1/obtest/clog/

发下以下执行结果
df -i /opt/oceanbase/data/
dmesg | tail -50 | grep -i "error\|fail"
getenforce
ls -la /opt/oceanbase/data/1/obtest/clog/log_pool/ | head -10
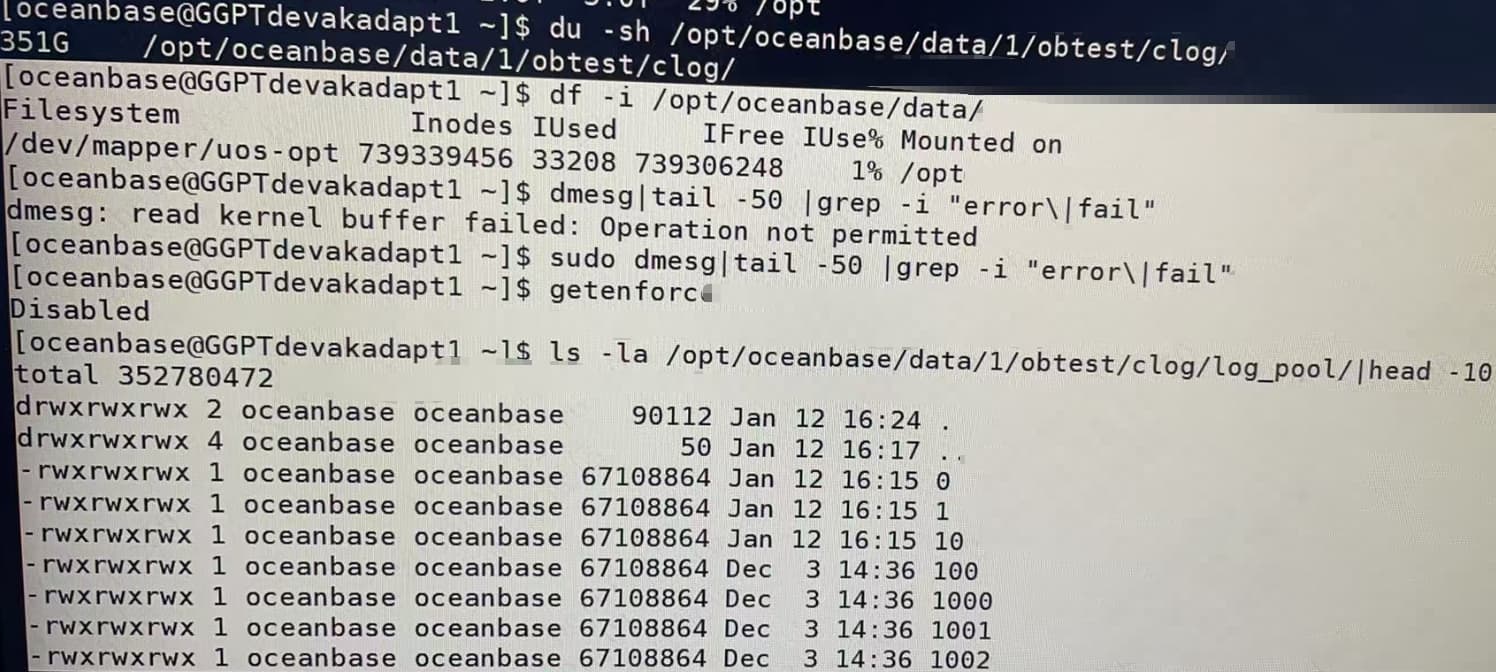
看下这个结果
ls /opt/oceanbase/data/1/obtest/clog/log_pool/ | wc -l
grep "renameat failed" /opt/oceanbase/log/observer.log | wc -l

我的这个集群有三个zone,之前对zone3所在的节点进行服务下线后重新部署了oceanbase,再将zone3加入集群,模拟集群的扩缩容。这个报错应该是在扩缩容测试之后出现的。zone3上的部署和加入集群的操作如下:
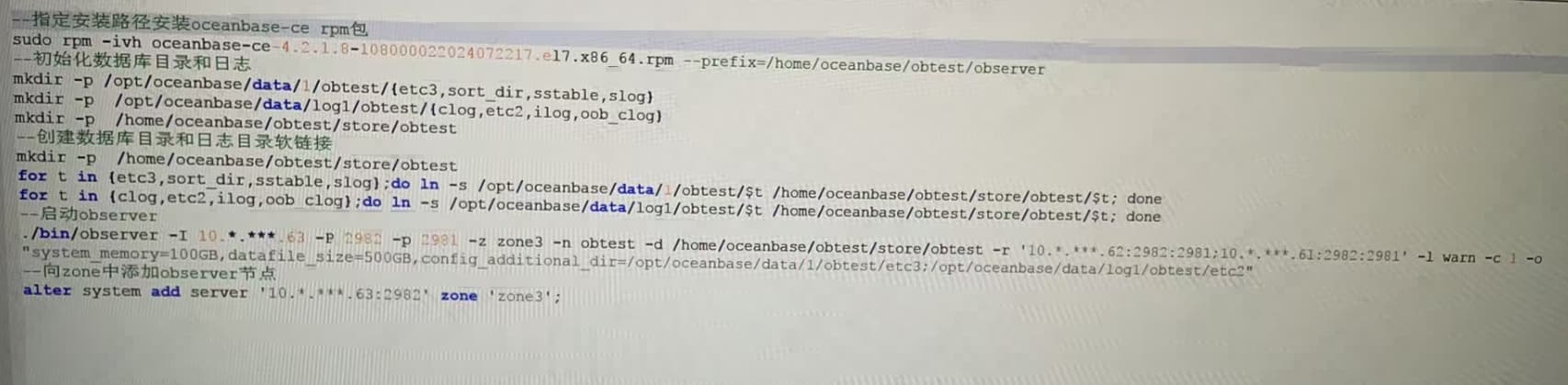
zone3的节点63下线后,其中的data,clog目录清空了吗?
报错日志是63的吗?其它两个节点也有吗?
最开始报renameat failed的时候,我去zone3所在节点服务器上看了,确实不存在该报错路径下的文件(zone1和zone2上是存在的),所以我重新在zone3上挂了软链,截图如下,但是挂了软链后也还是报这个错误。

zone3的节点63下线后,data,clog目录全部清空了,报错日志是在zone1和zone2上,zone3上没有报错
好的
已解决,跑了巡检提示集群的新增节点数据目录和其它节点的数据目录不一致