

【 使用环境 】生产环境
【 OB or 其他组件 】OCP
【 使用版本 】4.4.0
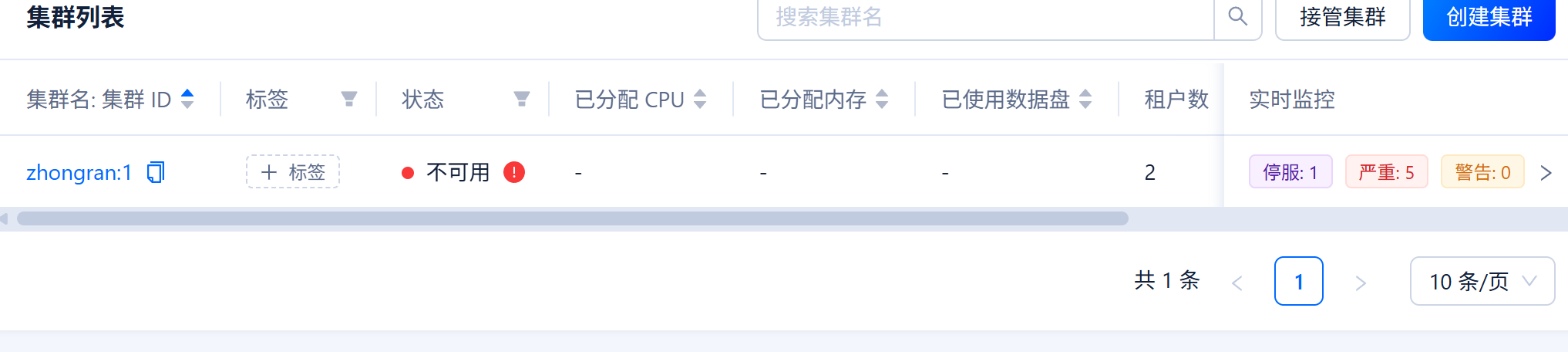
【问题描述】OCP上的集群显示不可用,主机状态都是正常的,我看了OB集群里某一台服务器,发现没有observer的进程了,我想手动在服务器上启动observer,提示error while loading shared libraries: libaio.so.1: cannot open shared object file: No such file or directory,我不知道启动对了没
【复现路径】问题出现前后相关操作
【附件及日志】

3 个赞
报错显示缺文件,确实不存在么
1 个赞
ocp界面不能拉起该节点么
lib报错问题可以参考下面这个帖子解决方法
1 个赞
学习了
刚刚又出现了这个问题,突然集群就不可用了,然后有两个节点的observer进程没有了,然后我停止了一下集群,又启动了一下,又变成可用了,这到底啥问题啊
有可能是触发某种bug导致core掉了,
cat /etc/sysctl.conf|grep core_pattern
看一下core目录下是否有core文件生成。
cat /etc/sysctl.conf|grep core_pattern执行这个没有东西
麻烦先提供一份停服时候的observer日志。这个参数如果没有 手动添加一下 下次复现出来就会自动生成出core文件了
集群发生CRASH ERROR了。优先打开core路径,需要对core文件分析方可
ob版本是多少
4.5.0的,最新的
刚刚想登录OCP,发现OCP都登不上去了,提示Unhandled exception, type=CannotCreateTransactionException, message=Could not open JPA EntityManager for transaction
执行下这个
jstack -l < java-pid > > jstack.txt
看下ocp是否僵住
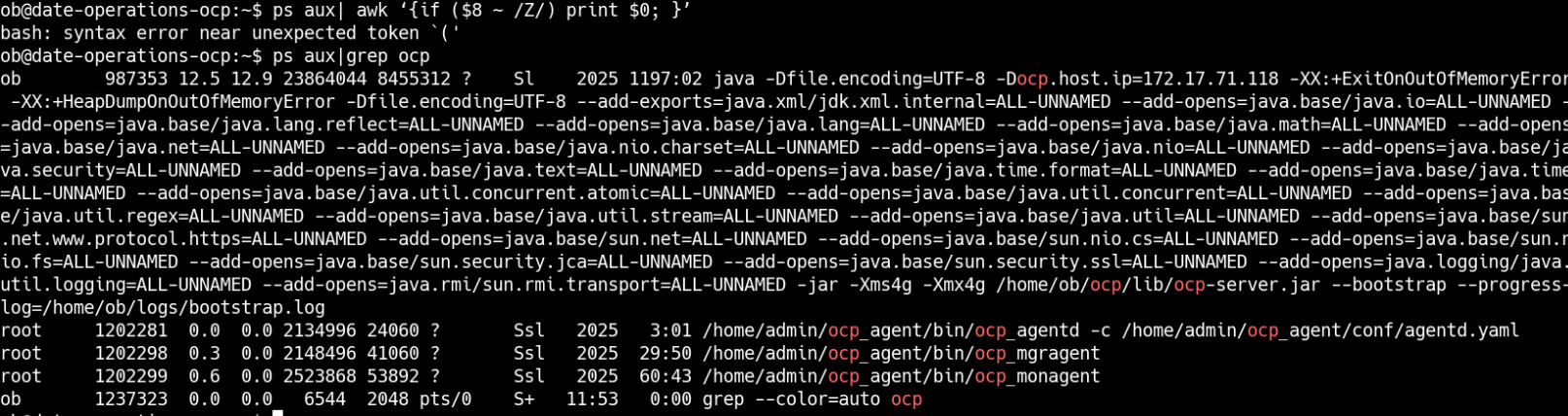
ps aux| awk ‘{if ($8 ~ /Z/) print $0; }’
ps aux|grep ocp
重启集群提示OBD-2000: (172.17.71.118) not enough memory. (Free: 27G, Buff/Cache: 25G, Need: 55G), Please reduce the memory_limit or memory_limit_percentage,这个是需要去哪里调整
这个参数好像无法调整,刚刚调整了下说是production_mode is True,无法调整,要整成false,但是好像就重新部署集群了,数据都会丢失
内存不支持调小。你这是主机内存未释放导致的
我是observer,opd,ocp装在一台机器上的
当前ocp还是无法打开么把metadb ocp进程都杀掉 释放一下内存 再使用obd重启
你好问一下,是arm环境么