

数据库管理-第394期 从数据角度如何用好分布式数据库(20251209)
作者:胖头鱼的鱼缸(尹海文)
Oracle ACE Pro: Database
PostgreSQL ACE
OpenTenBase ACE
10年数据库行业经验
拥有OCM 11g/12c/19c、MySQL 8.0 OCP、Exadata、CDP等认证
墨天轮MVP,ITPUB认证专家
圈内拥有“总监”称号,非著名社恐(社交恐怖分子)
公众号:胖头鱼的鱼缸
CSDN:胖头鱼的鱼缸(尹海文)
墨天轮:胖头鱼的鱼缸
ITPUB:yhw1809
IFClub:胖头鱼的鱼缸
除授权转载并标明出处外,均为“非法”抄袭

上月在北京交参会流期间,午餐时与首席探讨了分布式数据库中数据(表)逻辑结构的优化设计思路。需要先明确的是,本文聚焦于分布式数据库分片表的设计场景,单表的使用逻辑相对独立,复制表则需结合分片表协同部署。
本文内容包含演绎成分,不代表涉及人员的技术水平,特此说明。
数据库架构
首先,绝大多数分布式数据库的架构体系中,包含三类核心节点:
- 访问节点:承担外部应用与数据库集群的交互入口角色,负责将外部访问请求路由至集群内对应节点,同时具备一定的汇聚计算功能。
- 元数据节点:存储数据库集群的全量元数据,是集群管理和内部请求路由的核心依据。
- 数据节点:集群中实际存储业务数据的节点,所有数据节点存储的数据总量扣除副本冗余后即为全量业务数据,同时承担集群内绝大部分数据计算任务。
需说明的是,不同厂商的分布式数据库对上述节点的命名及细分功能存在差异,比如有角色/角色负责全局事务管理,但核心职能均可归为这三类,本文暂不展示具体架构图,避免倾向性。接下来重点分析集群中无法规避的节点交互路径:
- 访问节点与元数据节点:访问节点需依托元数据节点的信息,明确集群节点拓扑及数据分布规则,从而将请求精准路由至对应数据节点,同时基于元数据生成全局执行计划以提升查询效率。
- 访问节点与数据节点:业务数据实际存储于各数据节点,访问节点需将请求路由至目标数据节点,并完成计算结果的最终汇聚与反馈(特殊场景下可无需汇聚)。
- 数据节点与数据节点:部分分布式数据库中,关联分片的数据节点间需完成数据同步操作。不同数据库产品中,分片数据同步的发起主体(节点/组件/角色)及一致性保障机制存在差异,部分数据库中节点仅需完成同步结果的最终确认,此类交互的带宽占用通常较低(也是所有分布式数据库的设计目标)。
在数据逻辑设计阶段,核心原则之一是尽可能规避数据节点间的计算类交互。这一原则的底层逻辑可通过内存与网络的带宽、延迟特性对比体现:

综上,数据访问与计算的优化目标是:尽可能在数据节点内部通过内存完成数据读取与计算,最大程度减少跨数据节点的数据交互(此类交互除了带来延迟、带宽损耗外,还可能产生额外的内存开销)。要实现这一目标,需让业务关联数据尽可能存储于同一数据节点,使绝大多数数据获取请求仅需向访问节点传输最终计算结果即可。
设计落地
在集中式数据库中,数据可直接从内存中读取,关联查询性能极佳;且在完成合理的分区表配置后,基本无需额外关注表间关联的适配设计。但分布式数据库的场景截然不同:若订单主表与订单详表采用独立的分片策略(例如分别以主表ID、详表ID作为分片键),那么查询某一订单数据时,可能出现主表记录存储于某一分片,而对应的详表记录却分散在多个其他分片的情况,此时需基于主表ID执行跨分片关联查询。切勿忽视这类看似简单的查询:一旦查询量上升且数据分布无序,频繁的网状跨分片交互将大幅占用网络带宽,严重影响集群整体性能。
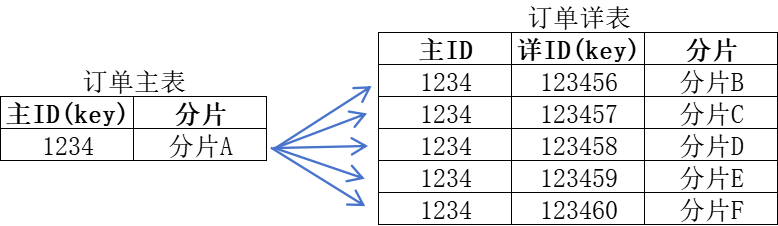
因此,将业务关联数据聚合存储于同一数据节点,是分布式数据库表结构设计的核心优化原则。仍以订单主表与订单详表为例,核心思路是统一分片策略——以订单主表ID作为两者的共同分片键,确保同一订单的主表记录与对应详表记录被路由至同一数据节点,从根源上避免跨分片关联查询。
针对这一需求,多数分布式数据库提供了标准化实现机制:例如通过主外键约束建立表间关联关系,或借助表组功能将关联表绑定为逻辑整体,在分片时强制遵循同一路由规则,最终实现关联数据的同节点存储,彻底规避无序跨分片交互带来的性能损耗。
首席提出另一个让能让大家更易看懂的解释:
用一句DBA都能看懂的SQL就行。
select * from a union select * from b@dblink这样的可以。
但是select * from a,b@dblink where a.id=b.id这样不行。
dblink表示非本节点(分片)。
用过Oracle和DB2 dblink以及MySQL的FEDERATED 应该有体会吧
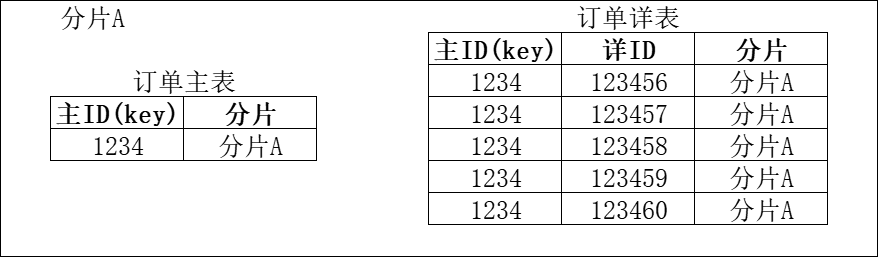
在与首席的交流中首席的主要问题集中在如何让分片的数据更加平衡,我以我主要服务的运营商场景为例说明分片设计思路:可按地市维度采用列表式分片策略,以四川省为例,若为每个地市单独设置一个分片,将和这个地市相关的所有数据关联存放至一个分片内,则针对单一地市的数据访问仅需操作对应分片,无需跨分片关联查询。但该方案存在明显问题——不同地市的数据体量差异显著(如成都与甘孜的用户量差距),直接按地市分片会导致数据倾斜,进而造成同规格服务器承载的分片出现显著性能差异。
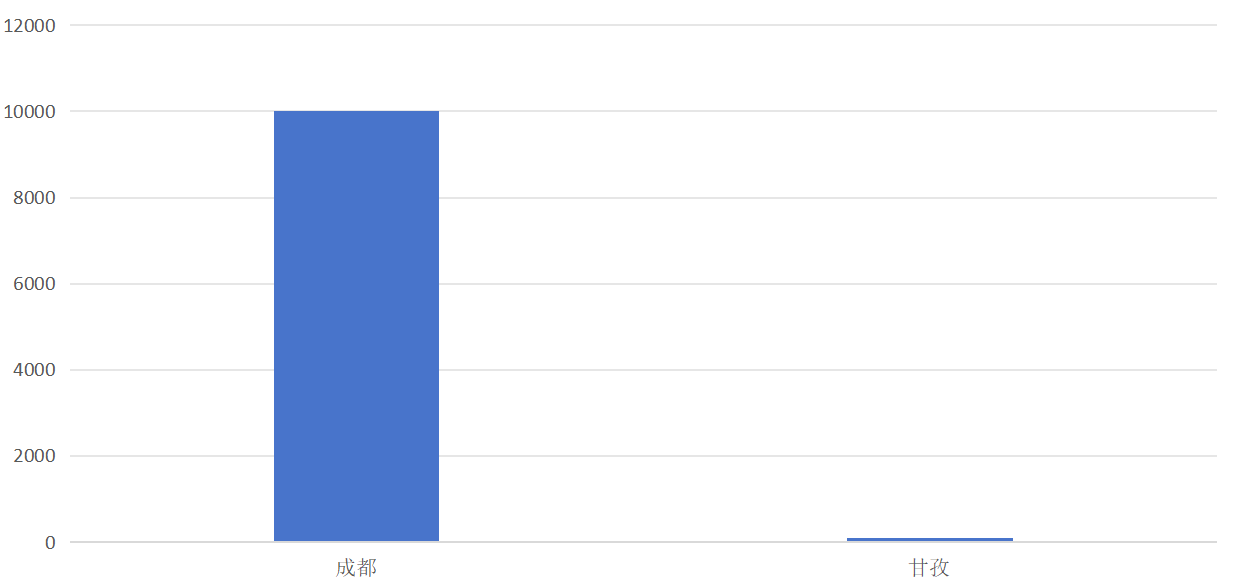
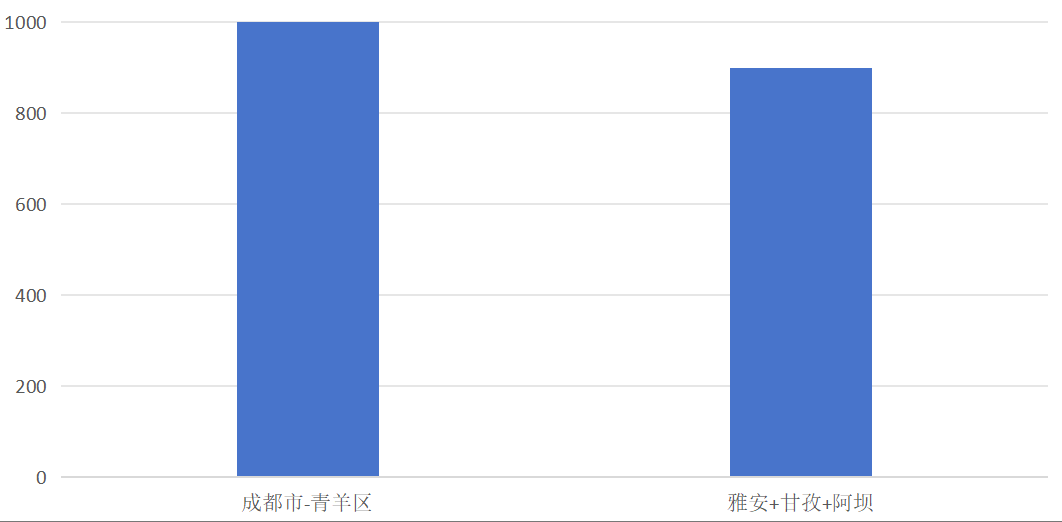
针对该问题,需结合实际数据量调整分片策略:将数据量较小的多个地市合并为一个虚拟分组,将数据量较大的地市按行政区(或其他合理维度)拆分为多个虚拟分组,以此平衡各分组对应分片的数据量与访问量,避免性能失衡。
首席疑惑
在交流过程中,首席提出了以下的场景:
以订单场景为例。一个表1000万的规模,数据分别来自10个用户(或者叫渠道或者叫子公司)。
传统行业就是这样:ABCDEFGHIJ,结果是A占比70%、BCDEFGHIJ合计30%(但B发展非常迅猛)。
这就像天下才学共一石,曹子建独占八斗。请问这时候怎么划分?
A独占一个分片OK;B因为发展迅猛独占一个分片有点浪费,但是也只能这样;CDEFGHIJ合计一个分片。
似乎没问题了,但是问题才刚开始:这个系统中也只能有3个负载不均衡分片。
要知道大客户就是大客户而B是潜在客户,A和相对大的B,增长数据的数据量是CDEFGHIJ不能比的。
所以A节点只能垂直方向扩展,其他节点帮不上他。因为如果A把数据分散到其他上或者说新增加分片XYZ点来平衡A节点。
无论怎么操作数据都会均衡或者不均衡的在A/XYZ上。
如果以订单ID维度分,我就以时间范围查询 select * from t where 时间条件 3个月 order by 其他字段limit 1000,雨露均沾的访问4个分片的数据。
你要是以时间维度分,我就以状态字段,雨露均沾的访问4个分片的数据。一个订单中有10个货物,有付款的有没付款的。有发货的有没发货的。主打一个随心所欲。
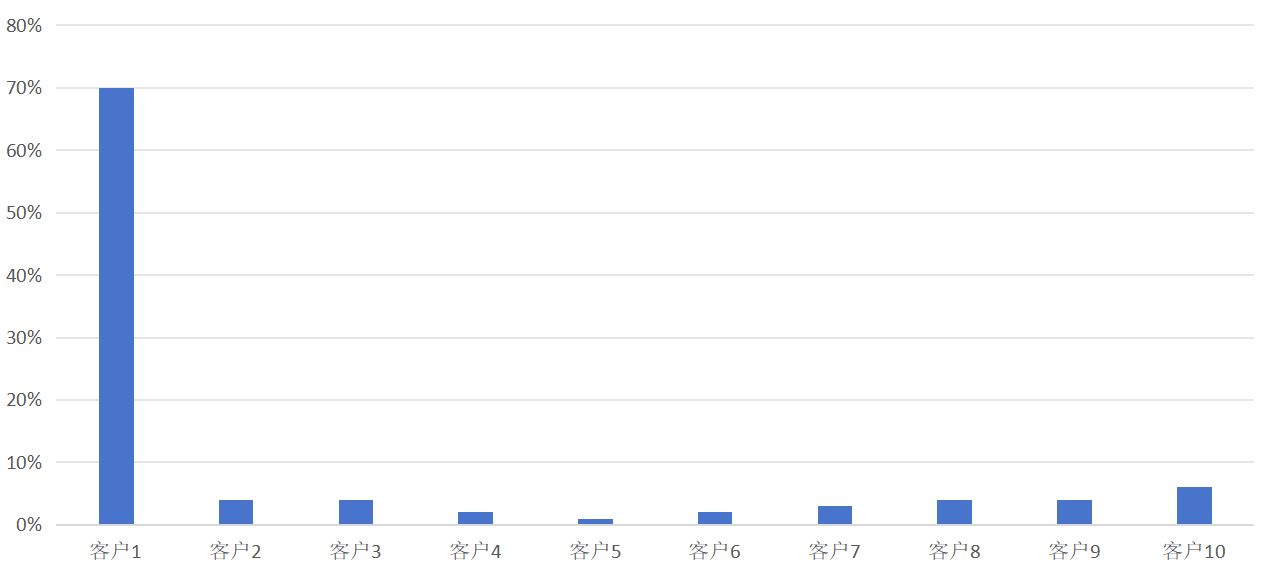
我的方案
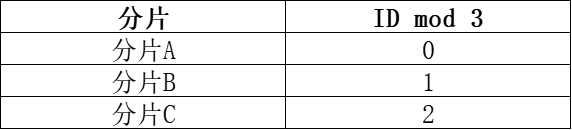
针对该场景,我提出的解决方案是:基于最高级别的订单ID进行分片——订单ID关联的数据范围有限,通过制定合理的ID分片规则,可确保各分片的数据量趋于均衡。
比如以三分片为例,使用起始值大于100的自增序列作为订单ID,将订单ID mod 3后按照余数的值进行分片:
关于和这个最高级别订单ID相关联的其他级别的ID,则可通过数据库本身的数据归集策略让关联数据存放于同一分片中,杜绝和最高级别订单ID相关的数据获取产生跨分片传输。
对此可能存在的疑问是:若需查询某一客户的订单数据(该数据跨分片存储),是否会引发数据节点间的交互?对此可结合复制表优化:客户信息的数据体量小且更新频率极低,可将其配置为复制表。如此一来,各数据节点可在本地完成分片表(订单数据)与复制表(客户信息)的关联查询,仅需将查询结果汇总至访问节点做最终处理,既规避了数据节点间的交互,又能充分利用数据节点内存计算优势完成数据过滤,减少向访问节点传输的数据量。
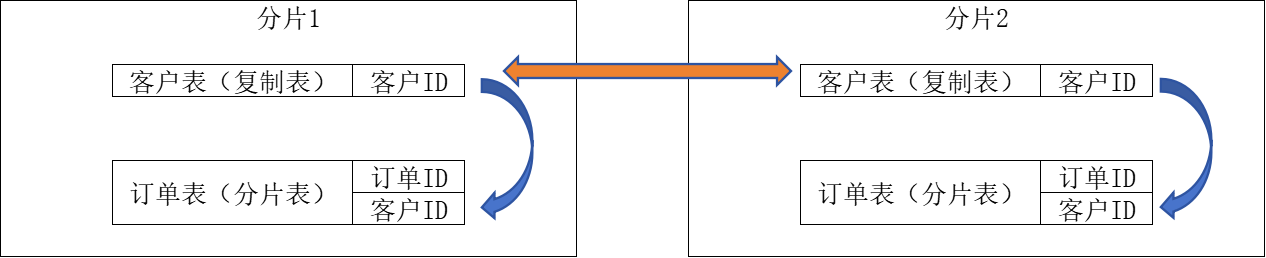
如果需要按照其他维度,比如以订单涉及区域为条件,则也需要设计对应合理的字典表来实现。
潜在问题
前文讨论的场景多聚焦于点查询或范围限定的精准查询,若涉及汇聚排序操作(例如按用户订单总价汇总排序),在分布式数据库中会面临更复杂的挑战——核心原因在于,各分片独立计算的局部排序结果(如分片内TOP N)无法直接等同于全局排序结果,极易出现数据偏差。
以用户订单总价排序为例,假设数据分布如下表所示(数值为单分片内用户订单总价):
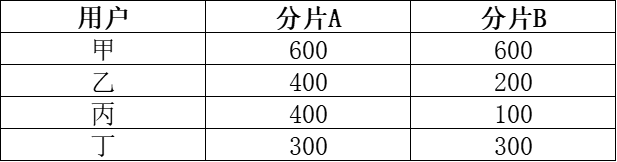
若简单将 “查询全局TOP3” 的SQL直接分发至各分片独立执行:分片A会返回甲 (600)、乙 (400)、丙 (400),分片B会返回甲 (600)、丁 (300)、乙 (200);将两片结果直接汇总后,会得到甲 (1200)、乙 (600)、丙 (400) 的错误TOP3结果。但结合全量数据计算(甲 600+600=1200、乙 400+200=600、丁 300+300=600、丙 400+100=500),真实的全局TOP3应为甲 (1200)、乙 (600)、丁 (600)。
由此可见,分布式数据库的汇聚排序操作,往往需要通过全量数据拉通汇总,或先对各分片的目标列数据集中排序,再结合全局维度补齐计算,才能确保结果的准确性——这也意味着此类操作会比在集中式数据库中的查询消耗更多的网络带宽与计算资源。
再一个问题就是,如果当业务发展,3个分片的性能或存储容量无法满足需求时,即需要增加分片时,需要将分片表的所有数据重新按照新的分片键规则(比如mod 4甚至是5)重新进行打散,在这个过程中所有分片的本地CPU和内存资源以及节点、分片间的网络资源都会被极大的占用,期间数据库的分片表和元数据也会被锁定,数据库集群甚至会达到不可用的情况。而且数据库横向扩展往往不止涉及一张分片表,多张分片表的分片调整会对数据库集群带来极大的挑战。所对应的应用逻辑变更也会带来相同的问题。
总结
其实最终看来,更换数据库适的适配改造,不仅是应用开发做改造,窥探其实质又何尝不是业务逻辑的改造呢?无论是DBA还是开发人员都需要去深入了解业务逻辑,才能做好新数据库的适配改造。
由于本文涉及部分共创,没有老规矩。