

【 使用环境 】测试环境
【 OB or 其他组件 】
【 使用版本 】 OceanBase 版本号 4.3.5.3、版本号: 4.3.6-20250709105610
【问题描述】OCP重启ob集群巨慢,等十几分钟卡着不动,原因是什么,怎么解决
【附件及日志】
subtask_17000585.log (38.7 KB)
根据您的描述,OCP 在测试环境中重启 OceanBase 集群时速度非常慢,这可能是由于多种因素导致的,包括但不限于集群配置不当、资源限制、数据量过大等。推荐使用 obdiag 工具进行日志采集,以便进一步分析具体原因。
日志采集场景: observer无故重启
日志采集命令: obdiag gather scene run --scene=observer.restart
请执行上述命令并收集日志,之后将日志提供给我们以便确认问题所在。为了更好地帮助您解决问题,请您回答以下问题:
- 重启前是否有任何异常操作或错误日志?
- 重启期间,系统资源(如CPU、内存、磁盘I/O)使用情况如何?
- 集群中数据量有多大?是否存在大量未提交的事务?
- 集群配置参数是否有所调整?如果有,具体调整了哪些参数?
- OCP 中是否有任何报警信息或提示?
- 在 OCP 的操作记录中,是否有关于重启过程中的详细日志信息?
感谢您的配合!
附上敏捷诊断工具 obdiag 使用帮助链接
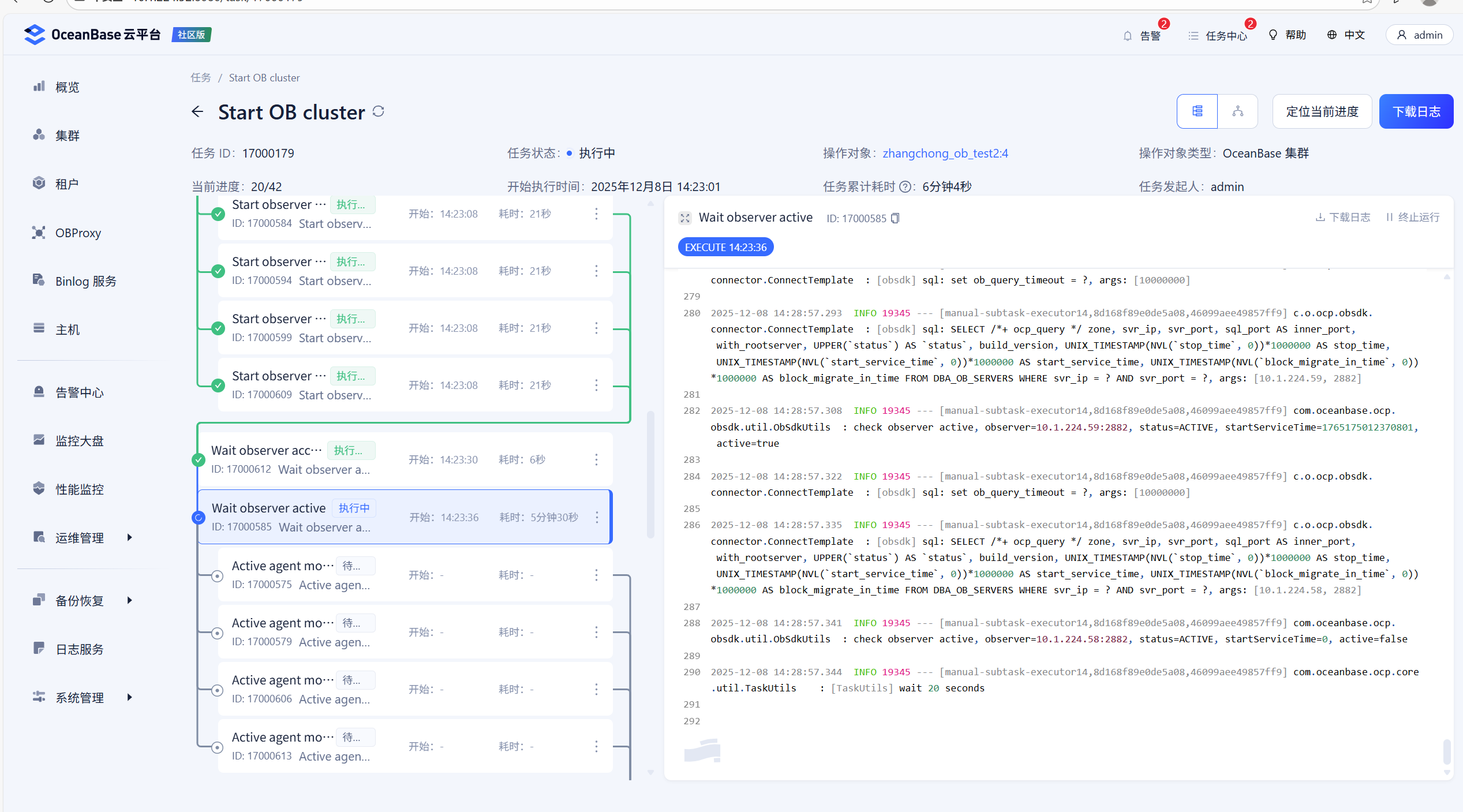
看起来是一直在等待224.58这个节点启动成功,可以取下这个节点 从启动开始时间的 3个observer.log 发下看下
2025-12-08 14:27:57.135 INFO 19345 — [manual-subtask-executor14,8d168f89e0de5a08,46099aee49857ff9] c.o.ocp.obsdk.connector.ConnectTemplate : [obsdk] sql: SELECT /*+ ocp_query */ zone, svr_ip, svr_port, sql_port AS inner_port, with_rootserver, UPPER(status) AS status, build_version, UNIX_TIMESTAMP(NVL(stop_time, 0))*1000000 AS stop_time, UNIX_TIMESTAMP(NVL(start_service_time, 0))*1000000 AS start_service_time, UNIX_TIMESTAMP(NVL(block_migrate_in_time, 0))*1000000 AS block_migrate_in_time FROM DBA_OB_SERVERS WHERE svr_ip = ? AND svr_port = ?, args: [10.1.224.58, 2882]
2025-12-08 14:27:57.141 INFO 19345 — [manual-subtask-executor14,8d168f89e0de5a08,46099aee49857ff9] com.oceanbase.ocp.obsdk.util.ObSdkUtils : check observer active, observer=10.1.224.58:2882, status=ACTIVE, startServiceTime=0, active=false
等了半个小时,最后成功了
节点配置怎样 cpu 内存? 租户几个?正常不会启动这么慢