

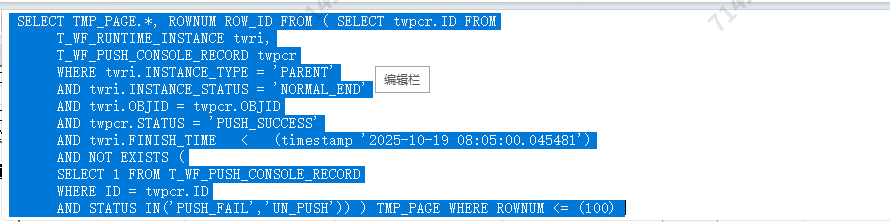
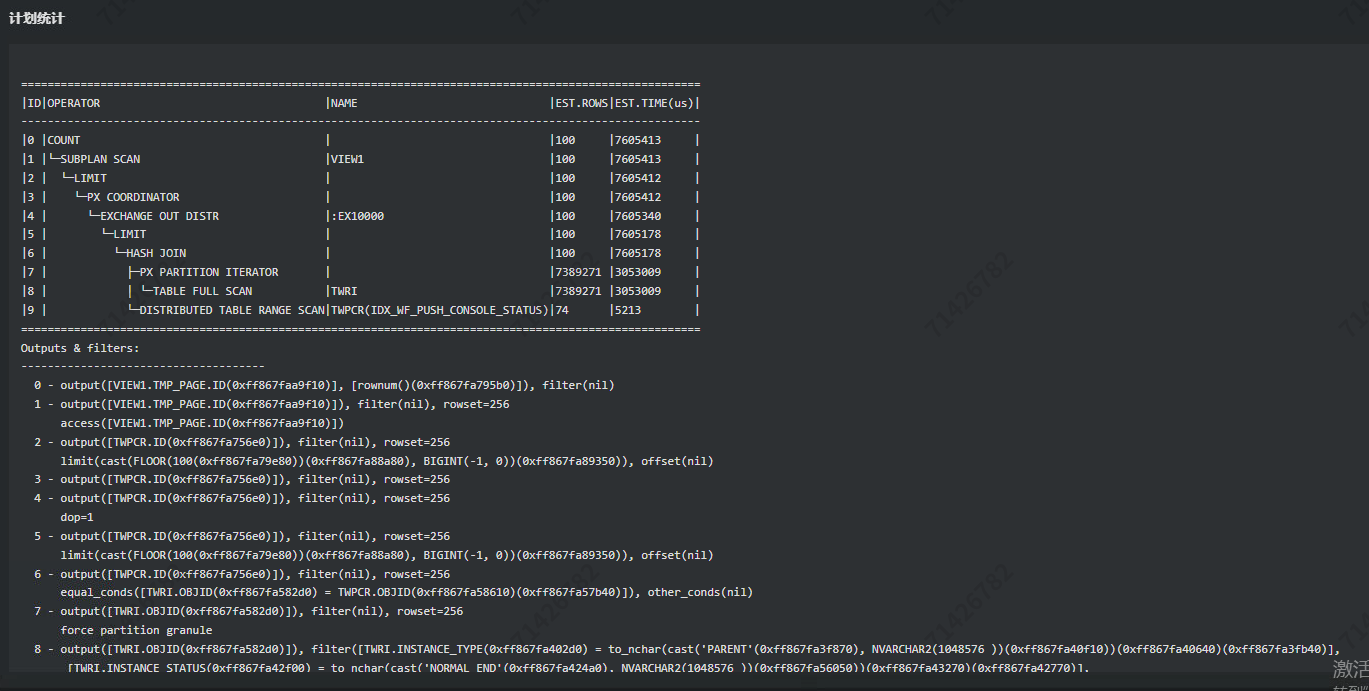
各位老师。sql如上 ,两张表数据量均为千万级别 , sql执行计划我看两个表的连接方式是hash join(大表连接),但是目前执行效率相对较慢 , 请问是否可以优化最优连接方式进行优化 , 没有选择性相对高的条件
两张表均为分区表 , 但是特殊场景逻辑上限制不能根据分区键做查询条件 , 所以目前通过连接方式是否有最优解
SHOW VARIABLES like ‘version_comment’;查一下ob的版本号
使用obdiag收集一下plan_monitor
obdiag gather plan_monitor --trace_id YB420BA2D99B-0005EBBFC45D5A00-0-0 --env “{db_connect=’-hxx -Pxx -uxx -pxx -Dxx’}”
https://www.oceanbase.com/docs/common-obdiag-cn-1000000004222802
老师 目前没有安装obdialog。可以通过系统表查询么?
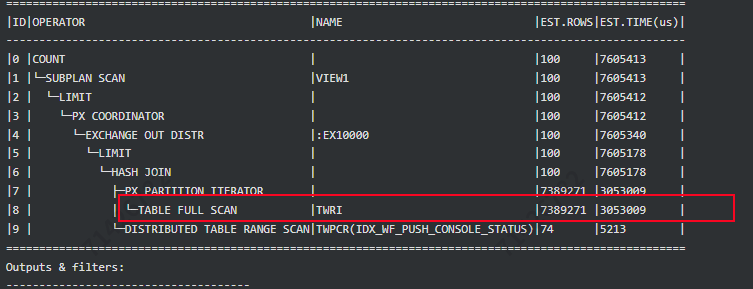
还有个问题 , 根据这个执行计划 , 这两张表走hash join是否是最优解 , 一张表找出5条数据。另一张表找出几十万条 , 这种不属于小表驱动大表。 走nlj是否更好呢?
版本是4.2.5.5
两个表的表结构发下呗
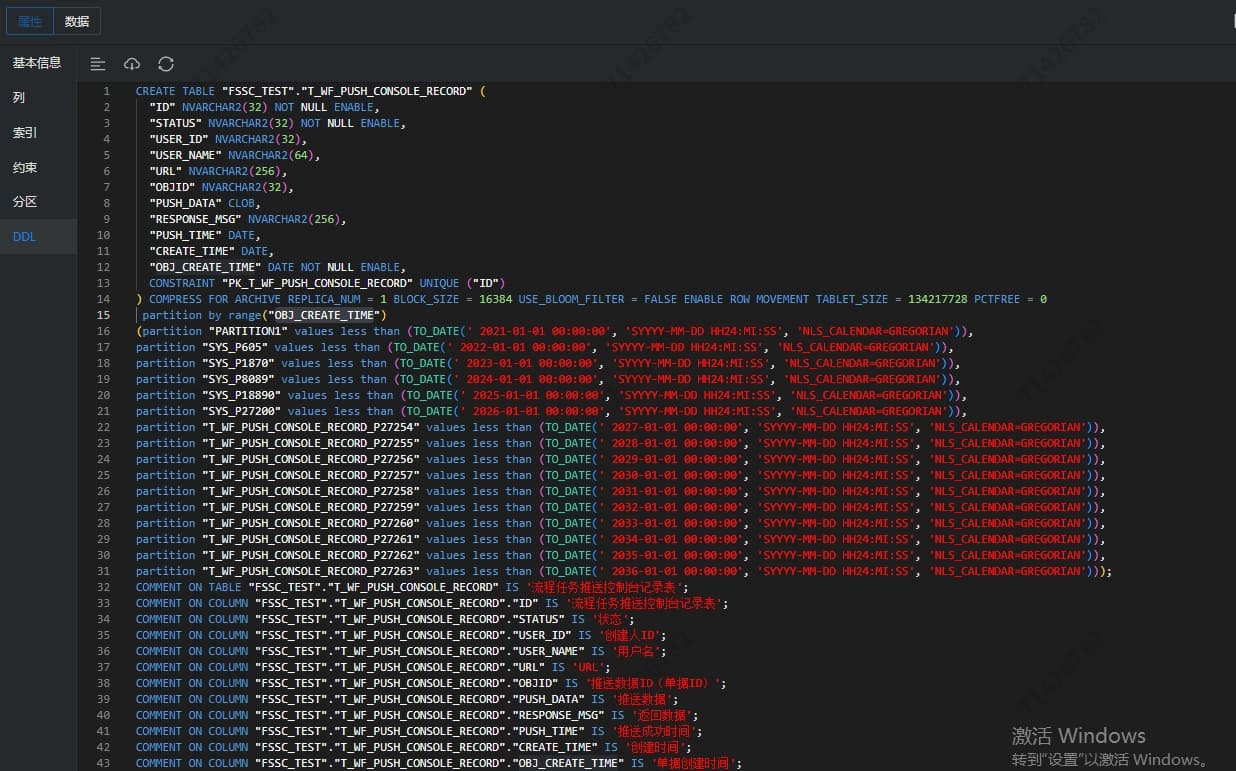

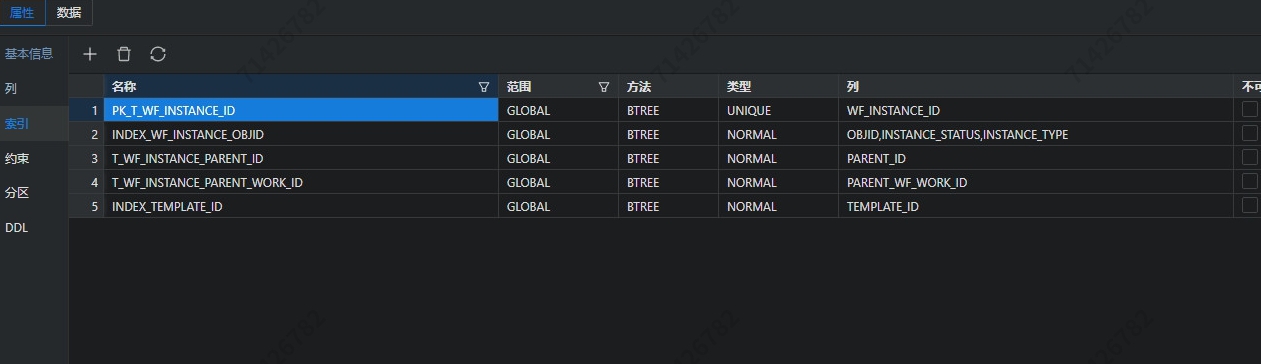

你这个表只有千万级别为什么要做分区表呢,而且这个SQL为什么不能使用分区键呢
select count() from t_wf_push_console_record where status=‘PUSH_SUCCESS’ ;
select count() from t_wf_runtime_instance where instance_type=‘PARENT’ and instance_status=‘NORMAL_END’ and finish_time<(timestamp ‘2025-10-19 08:50:00.045481’);
这个数据量有多少呢
777
业务上没有根据分区键操作的场景
建议安装一下obdiag 使用obdiag收集一下信息 要不然信息不全