【 使用环境 】生产环境
【 OB or 其他组件 】obd
【 使用版本 】4.0.0
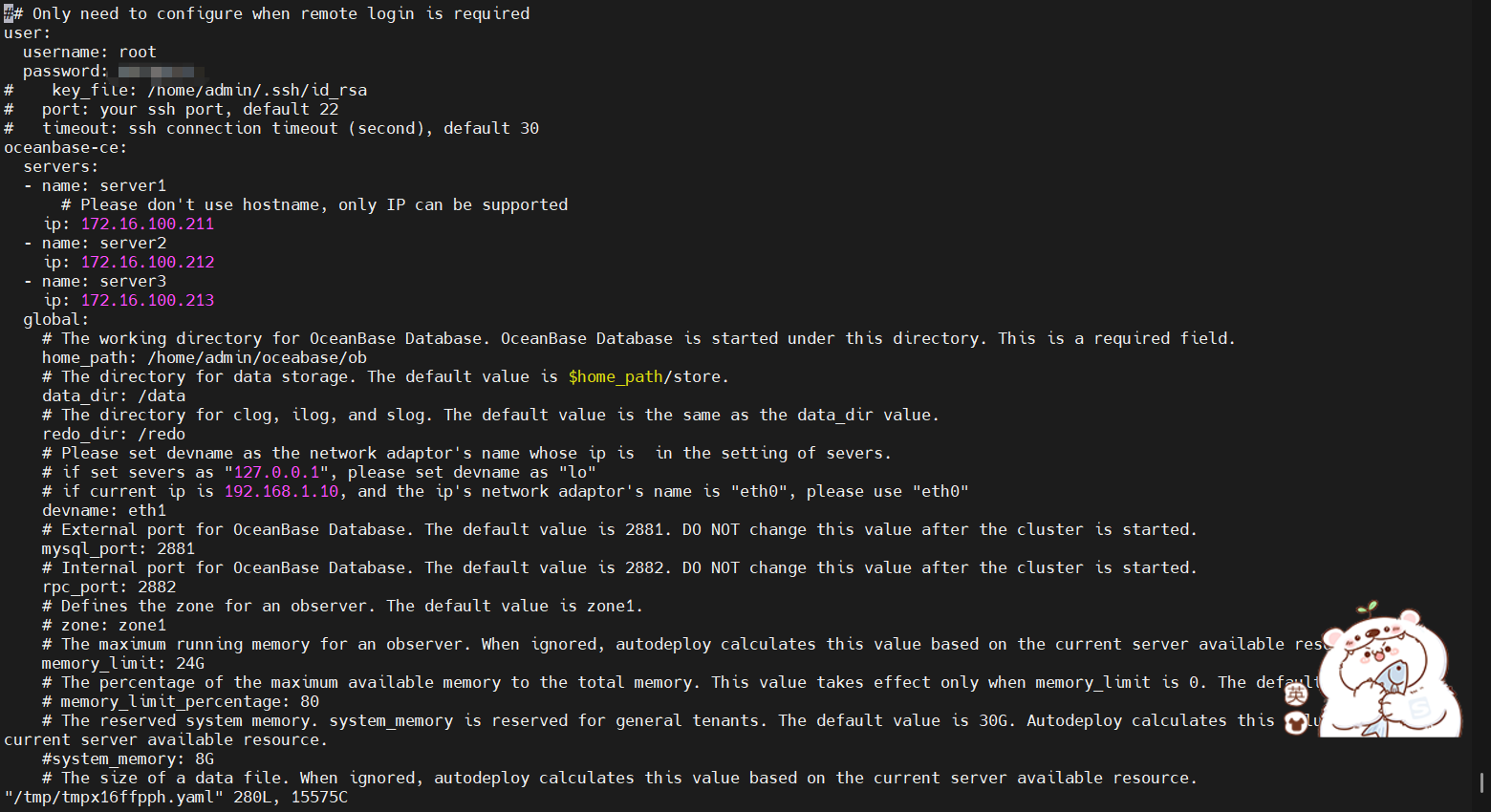
【问题描述】使用obd cluster edit-config obtest修改配
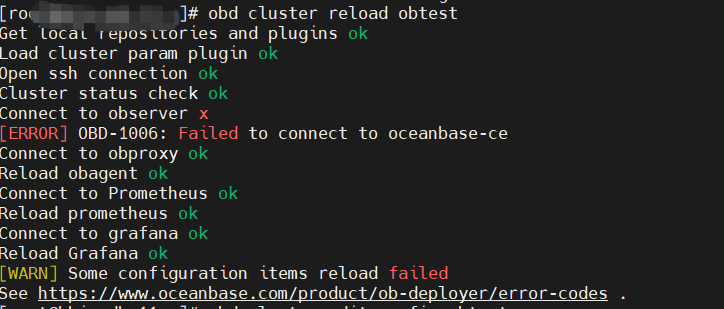
置后,执行obd cluster reload obtest报错,但是ps进程发现observer是启动的,也能连上,不知道为啥这里报错
【 使用环境 】生产环境
【 OB or 其他组件 】obd
【 使用版本 】4.0.0
【问题描述】使用obd cluster edit-config obtest修改配
ob的版本是哪个 看着是连接数据库失败了 yaml发一下 obd.log日志发一下
一般需要执行reload时 为参数被修改了。麻烦反馈一下修改了哪些参数
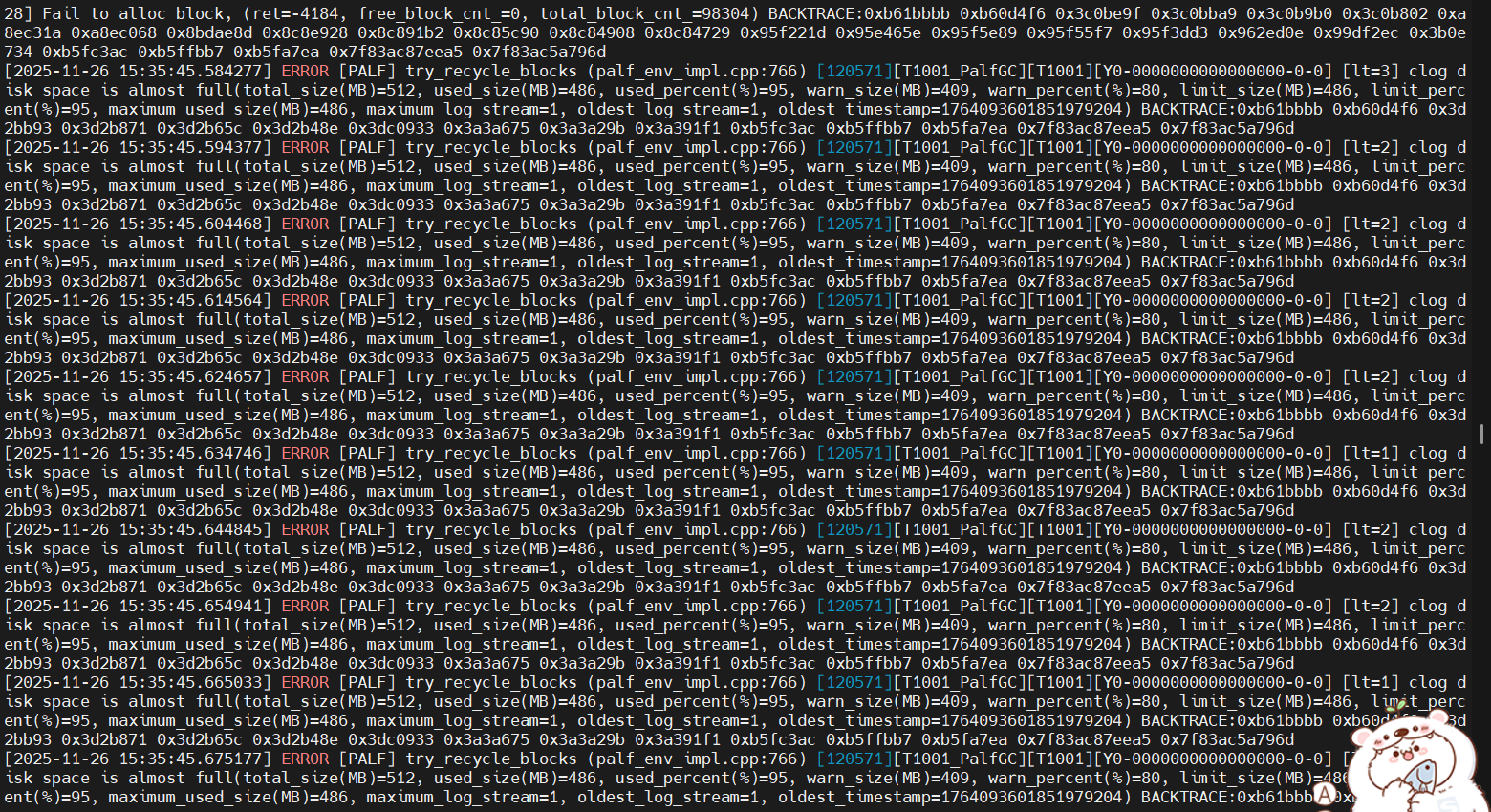
启动报错,可能为超时,或者ob启动长期处于初始化状态,可以登陆无法查询。
麻烦提供一份observer日志
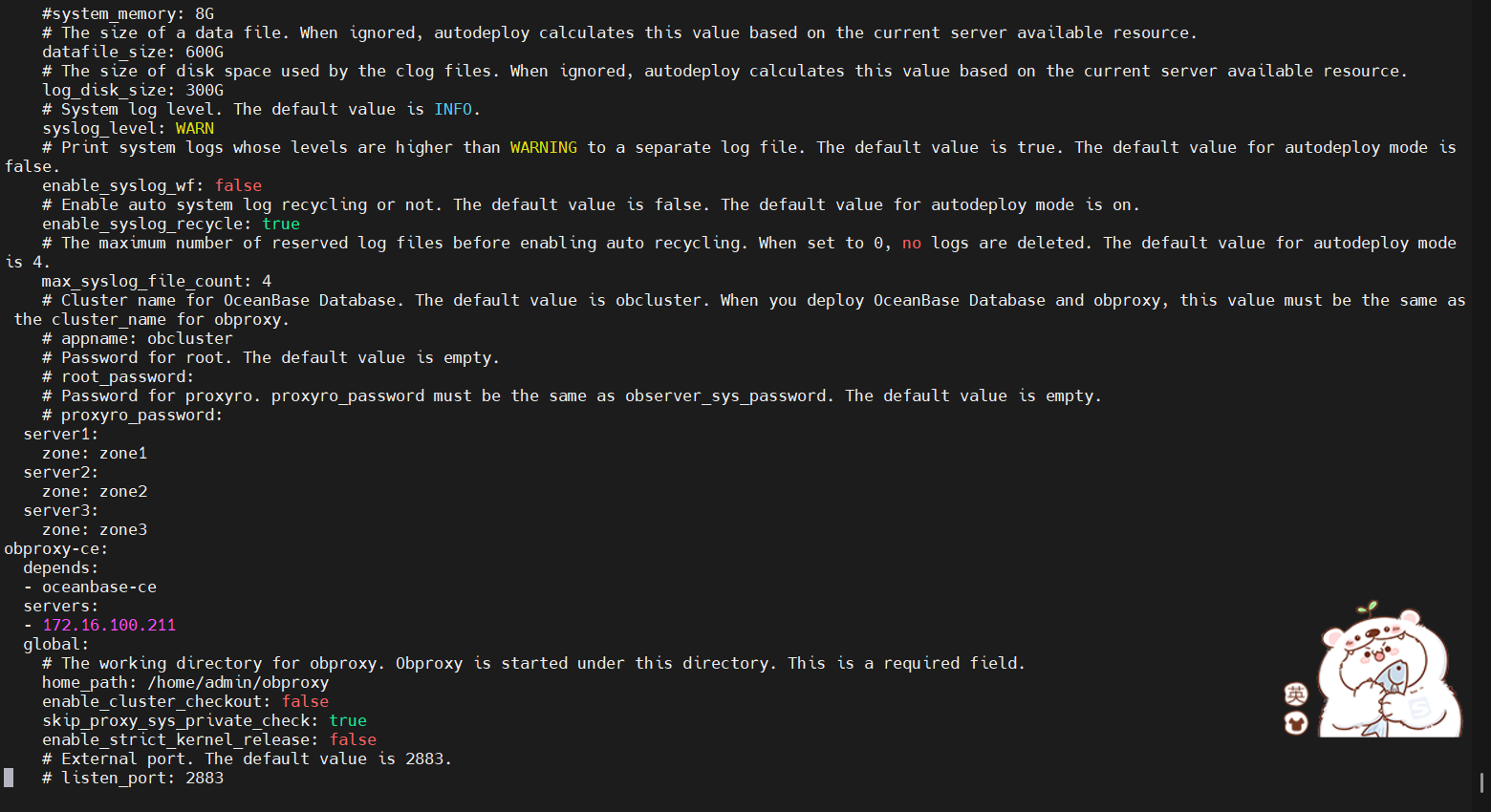
修改了datafile_size从192g改到600g了 log_disk_size从192改到300g了 observe.log太长了 没定位到哪里出错
当前集群正常么
启动集群的时候没报错 然后telnet ip和2881 2882 2883端口都能通 用连接工具也能正常连上数据库
暂时忽略掉这个问题吧。应该是超时导致的
那我还有其他方法修改上面的两个参数吗
你不是已经改掉了么。obd运维的集群建议还是使用 obd edit-config 修改
改掉了 但是reload不成功 我重启集群是–wop启动的 配置应该没生效
select * from gv$ob_servers查询看一下生效没
过来学习一下
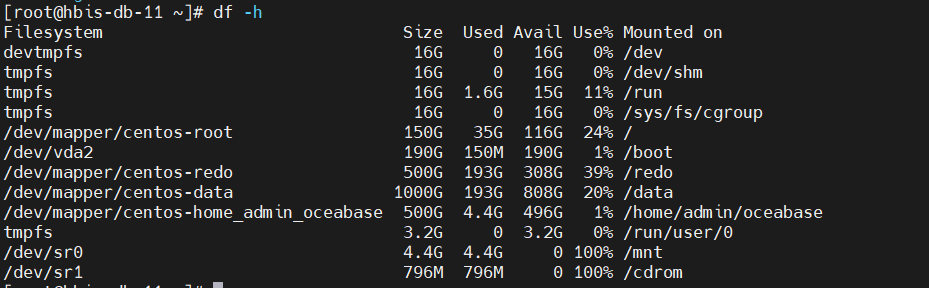
看着data盘快满了。reload不成功是否有足够的磁盘空间呢
麻烦提供一份yaml文件。df -h也看下
你这个yaml参数是修改过但没生效吧?
手动设置过1002租户的log disk大小么
解决方法:
黑屏化启动ob:
cd ~/xxx/oceanbase/
./bin/observer -o " log_disk_utilization_limit_threshold=97"
alter system set log_disk_size=‘xxxxG’;
对 是修改过 执行obd cluster reload obtest报的上面那个错误 就是1006那个错误代码