

通过动手实验体会vibe coding
-
在实验前需要具备的前提条件是:
-
1要安装好vscode
-
2 要安装好Python环境
-
3 需要seekdb
-
4 需要powermem
-
5 Jupyter插件(非必须,但是实际用过以后还是装吧)
-
这里的1和2做开发的人都知道。
-
3和4其实知道的人很少。
名词解释
-
PowerMem : 这是⼀款由 OceanBase 公司出品的专为 AI 应⽤打造的智能记忆 SDK,通过 LLM ⾃
动从对话中提取关键事实,实现记忆的去重、更新与合并,并基于艾宾浩斯遗忘曲线引⼊时间/频次
的强化学习机制,让 AI 能像⼈类⼀样⾃然“遗忘”过时噪声信息。⽀持多智能体记忆共享和隔离、多
模态数据(⽂本、图像、语⾳)记忆,并深度适配 OceanBase 混搜能⼒,结合多路召回与⼦表⾃
动路由的策略,显著提升⼤规模记忆的存储与查询效率。轻量级设计,易于集成,助⼒开发者快速
构建具备⻓期记忆能⼒的 AI 应⽤系统。github地址:GitHub - oceanbase/powermem: PowerMem: Your AI-Powered Long-Term Memory — Accurate, Agile, Affordable. -
seekdb: 这是 OceanBase 打造的⼀款开发者友好的 AI 原⽣数据库产品,专注于为 AI 应⽤提
供⾼效的混合搜索能⼒,⽀持向量、⽂本、结构化与半结构化数据的统⼀存储与检索,并通过
内置 AI Functions ⽀持数据嵌⼊、重排与库内实时推理。 seekdb 在继承 OceanBase 原核
⼼引擎⾼性能优势与 MySQL 全⾯兼容特性的基础上,通过深度优化数据搜索架构,为开发者
提供更符合 AI 应⽤数据处理需求的解决⽅案。
环境
-
在OceanBase的发布会上得到了官方给的环境。
-
ECS的机器

-
这个机器上已经安装好了seekdb和powermem。seekdb是用docker启动的。里面的database和表都已经初始化好了。
-
这样我们就可以直接用vscode去操作。先说这种通俗易懂的。(自己本地化安装最后说)
-
在vscode中安装remote ssh 插件。输入对的IP地址用户名密码,登录到远程服务器。请看总体目录
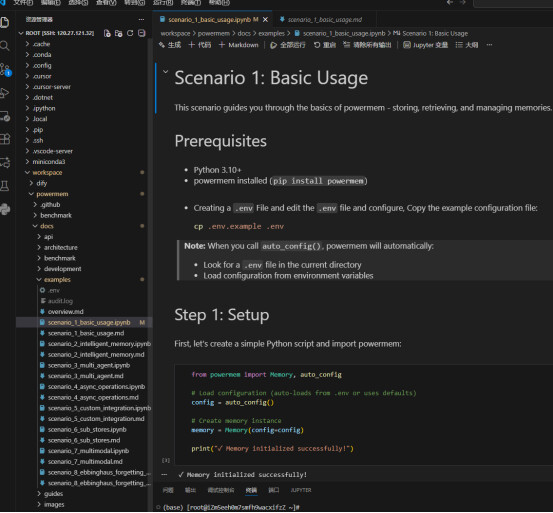
-
准备好的环境就是贴心,已经有了powermem。
-
注意这里:
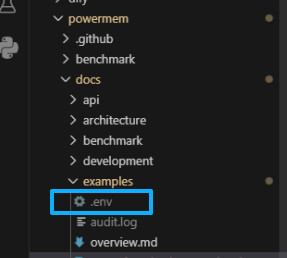
-
如果本地安装这个环境变量文件是没有的。需要手工建立。因为下载的powermem是在github上,不推荐说把链接数据库的信息放在里面。具体里面是这样的:
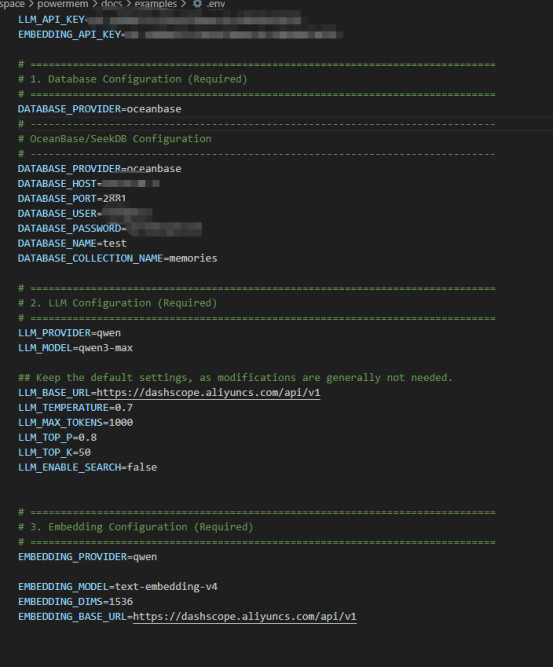
-
可以看到里面还涉及到了API的key。
-
按照我左边的路径进入到workspace/powermem/docs/examples/
-
可以看到有8对文件。每个md文件是实验说明。每个ipynb是Jupyter Notebook的专属文件。也就是说这个文件中的代码在安装了Jupyter插件后是可以直接运行的。所以还是老实在vscode中安装吧。
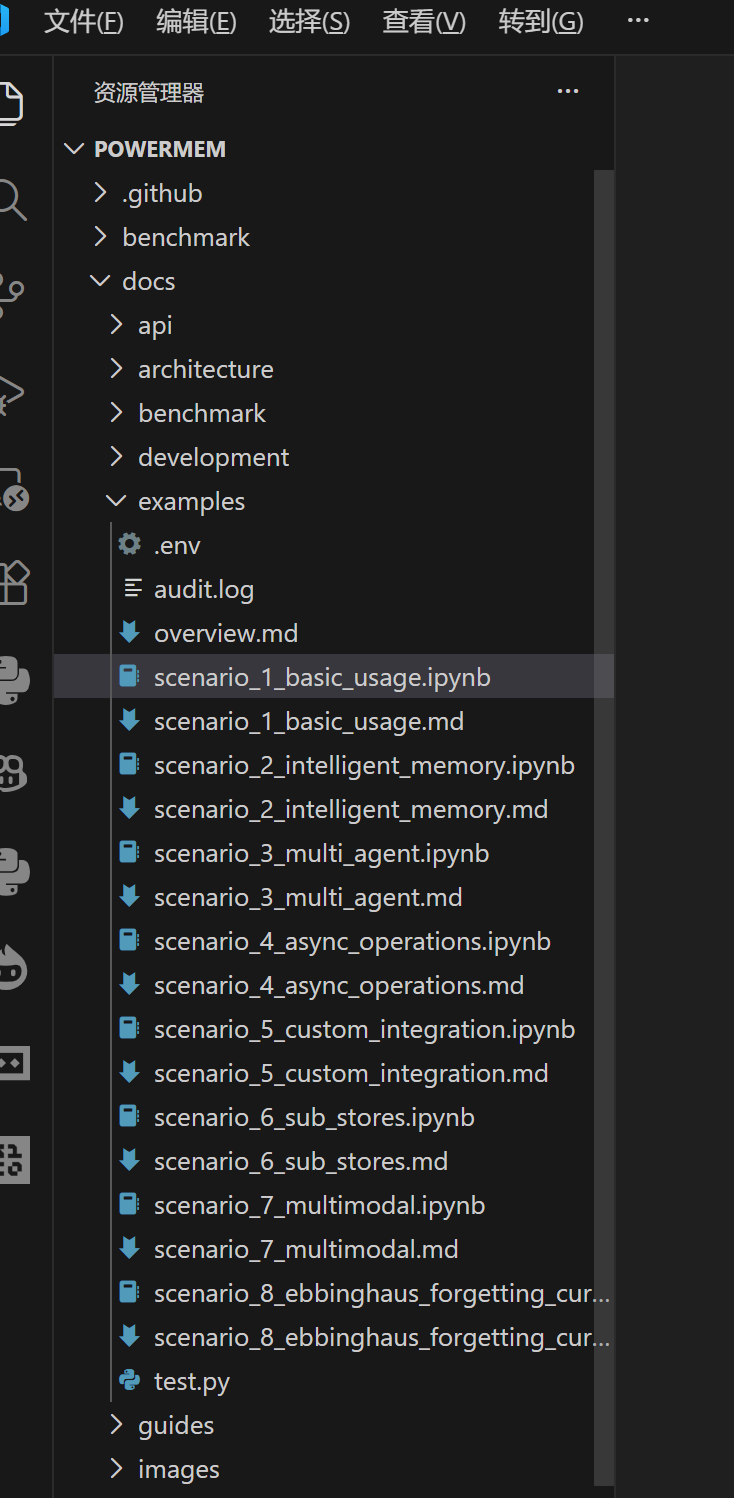
运行
- 可以看到我在安装了。如果没有这个,就要复制这些代码到一个新建的python环境去安装。
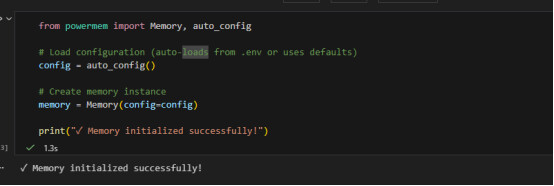
- 安装好的效果就是这样:在这里直接运行。(这种是第一次用到,以前都不知道Jupyter这种东西)。
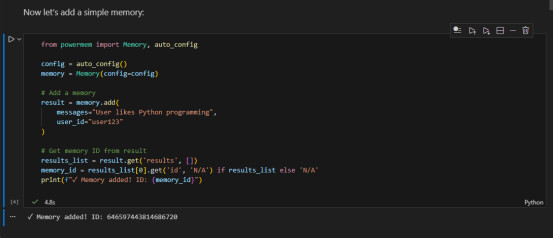
-
因为刚才的env中有数据库的连接字符串这就把这些数据写入到这个seekdb的嵌入式数据库了。
-
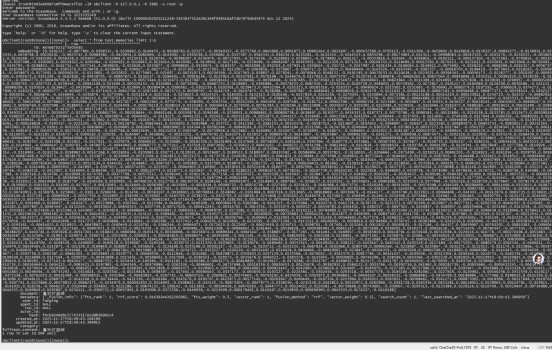
进到数据库验证一下:obclient -h 127.0.0.1 -P 2881 -u root -p
-
select * from test.memories limit 1\G
- 整个步骤有好几个,我列举一下:

-
分别是增加一条记忆,增加多条记忆,后面还有修改一条记忆和删除记忆等步骤。
大家可以看到这里我提到每个都是记忆,那这样做的意义是什么?
其实作用就是在我们使用AI对话时候,一个token数量是有限的。当放不下的时候,不得不开一个新的会话。那么这里AI只能从0开始对话,之前的信息并不能掌握。有时候可能就要费时费力的去概括一下之前的内容。而有了这个以后,AI把一些重要的信息记录到数据库中,这样即使是新开的会话(只要匹配到对应的同一个用户ID)就能把历史上有过的会话信息快速找到。 -
以上感谢OB的靖顺(花名)老师帮我解惑,协助我遇到的一些问题。
-
其实seekdb 主要是嵌入式+轻量混搜,这就是 seekdb 的价值。