【 使用环境 】生产环境
【 使用版本 】OceanBase 版本号 4.3.5.0
【问题描述】
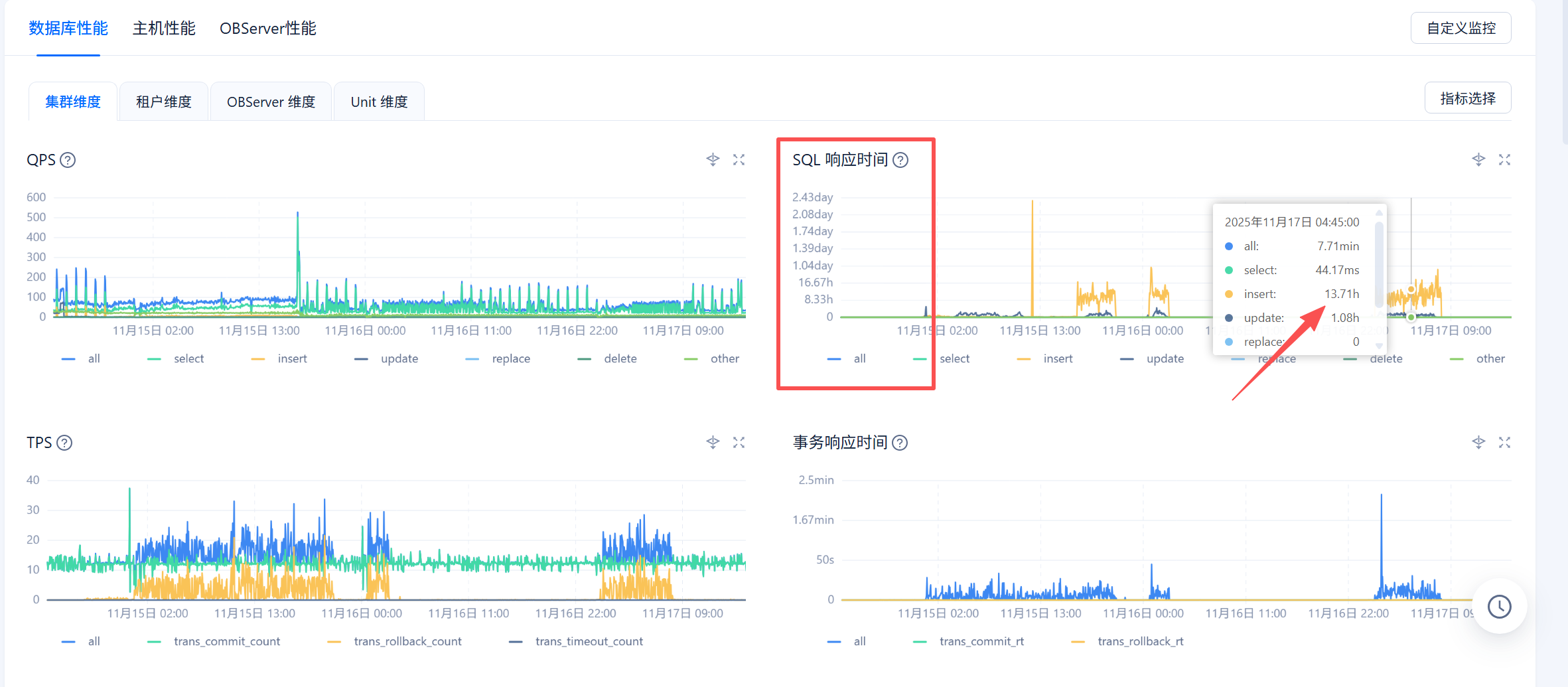
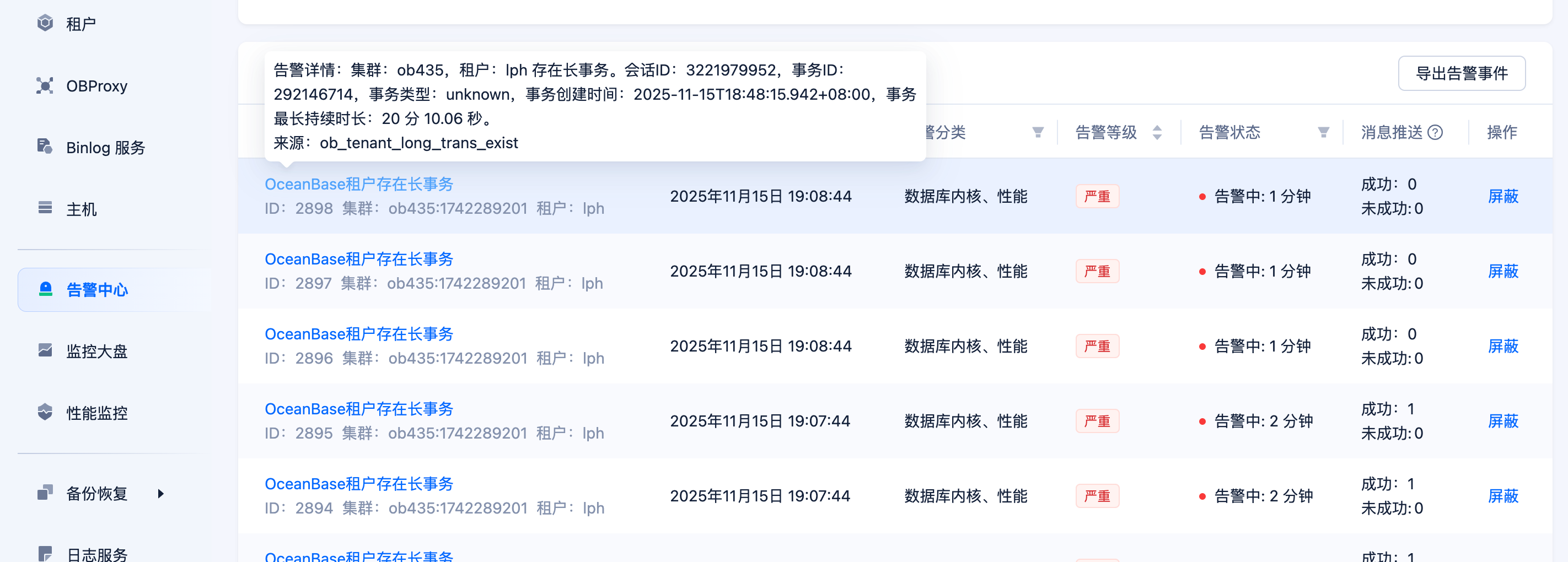
下午发现 ob集群 SQL 写入特别慢 ,从ocp看 有慢查询的警告,相关写服务已经停止,服务器高负载没有下降,通过工具查看SQL 语句发现是卡在RPC ,如图:
服务器监控:
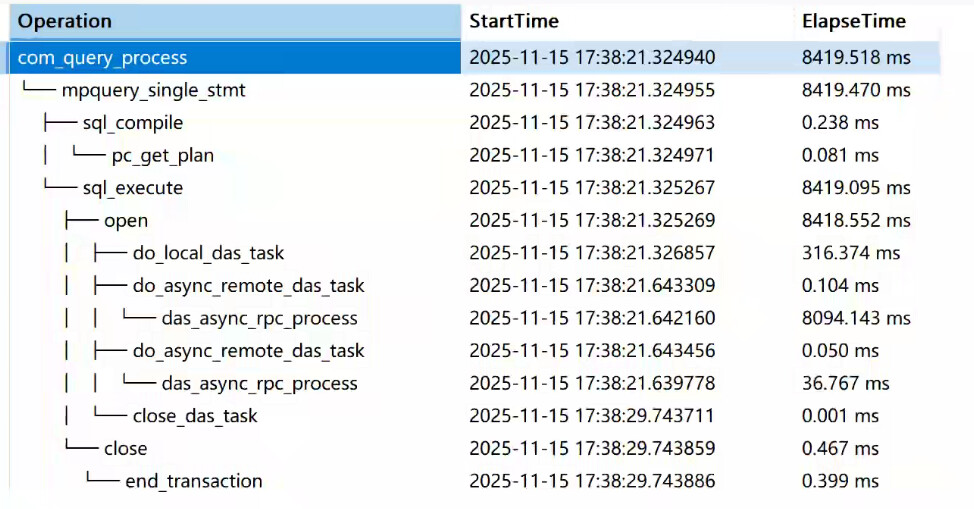
OCP 警告如下
服务器监控如下:
【 使用环境 】生产环境
【 使用版本 】OceanBase 版本号 4.3.5.0
【问题描述】
下午发现 ob集群 SQL 写入特别慢 ,从ocp看 有慢查询的警告,相关写服务已经停止,服务器高负载没有下降,通过工具查看SQL 语句发现是卡在RPC ,如图:
服务器监控:
OCP 警告如下
服务器监控如下:
看着可能是网络波动导致的。麻烦提供一份observer日志看下
性能日志看看
麻烦直接上传到帖子上,这边无法下载
是所有的sql都慢么?还是个别的语句慢
附件是集群observer.log 的日志
ob01-observer.log.zip (2.7 MB)
ob02-observer.log.zip (14.7 MB)
ob03-observer.log.zip (27.6 MB)
ob05-observer.log.zip (29.2 MB)
ob06-observer.log.zip (29.4 MB)
查询 不慢 , 写 删除都慢
磁盘是ssd盘还是机械盘 数据盘和clog分盘了么?
SHOW VARIABLES like ‘version_comment’; 查一下版本信息
show parameters where name in (‘memory_limit’,‘memory_limit_percentage’,‘system_memory’,‘log_disk_size’,‘log_disk_percentage’,‘datafile_size’,‘datafile_disk_percentage’);
select zone,concat(SVR_IP,’:’,SVR_PORT) observer,
cpu_capacity_max cpu_total,cpu_assigned_max cpu_assigned,
cpu_capacity-cpu_assigned_max as cpu_free,
round(memory_limit/1024/1024/1024,2) as memory_total,
round((memory_limit-mem_capacity)/1024/1024/1024,2) as system_memory,
round(mem_assigned/1024/1024/1024,2) as mem_assigned,
round((mem_capacity-mem_assigned)/1024/1024/1024,2) as memory_free,
round(log_disk_capacity/1024/1024/1024,2) as log_disk_capacity,
round(log_disk_assigned/1024/1024/1024,2) as log_disk_assigned,
round((log_disk_capacity-log_disk_assigned)/1024/1024/1024,2) as log_disk_free,
round((data_disk_capacity/1024/1024/1024),2) as data_disk,
round((data_disk_in_use/1024/1024/1024),2) as data_disk_used,
round((data_disk_capacity-data_disk_in_use)/1024/1024/1024,2) as data_disk_free
from oceanbase.gv$ob_servers;
select a.zone,a.svr_ip,b.tenant_name,b.tenant_type, a.max_cpu, a.min_cpu,
round(a.memory_size/1024/1024/1024,2) memory_size_gb,
round(a.log_disk_size/1024/1024/1024,2) log_disk_size,
round(a.log_disk_in_use/1024/1024/1024,2) log_disk_in_use,
round(a.data_disk_in_use/1024/1024/1024,2) data_disk_in_use
from oceanbase.gv$ob_units a join oceanbase.dba_ob_tenants b on a.tenant_id=b.tenant_id order by b.tenant_name;
信息查一下
查一下出问题的时间段的信息
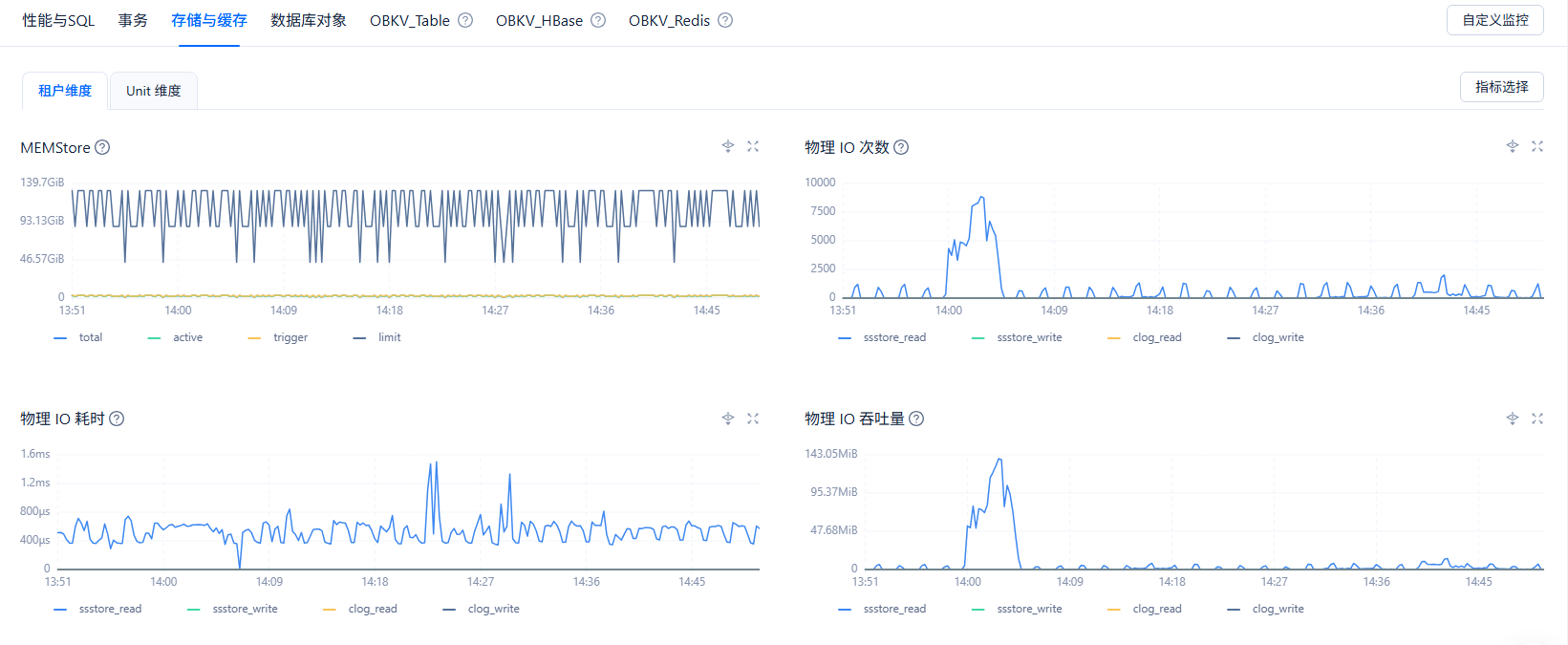
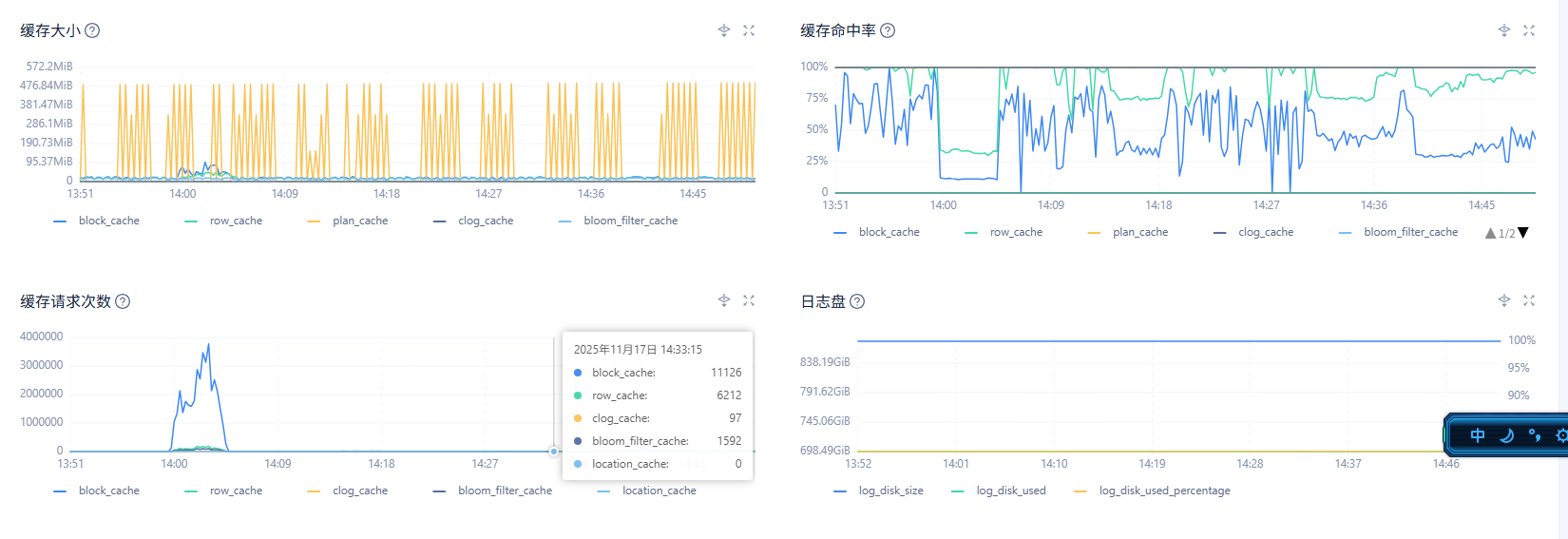
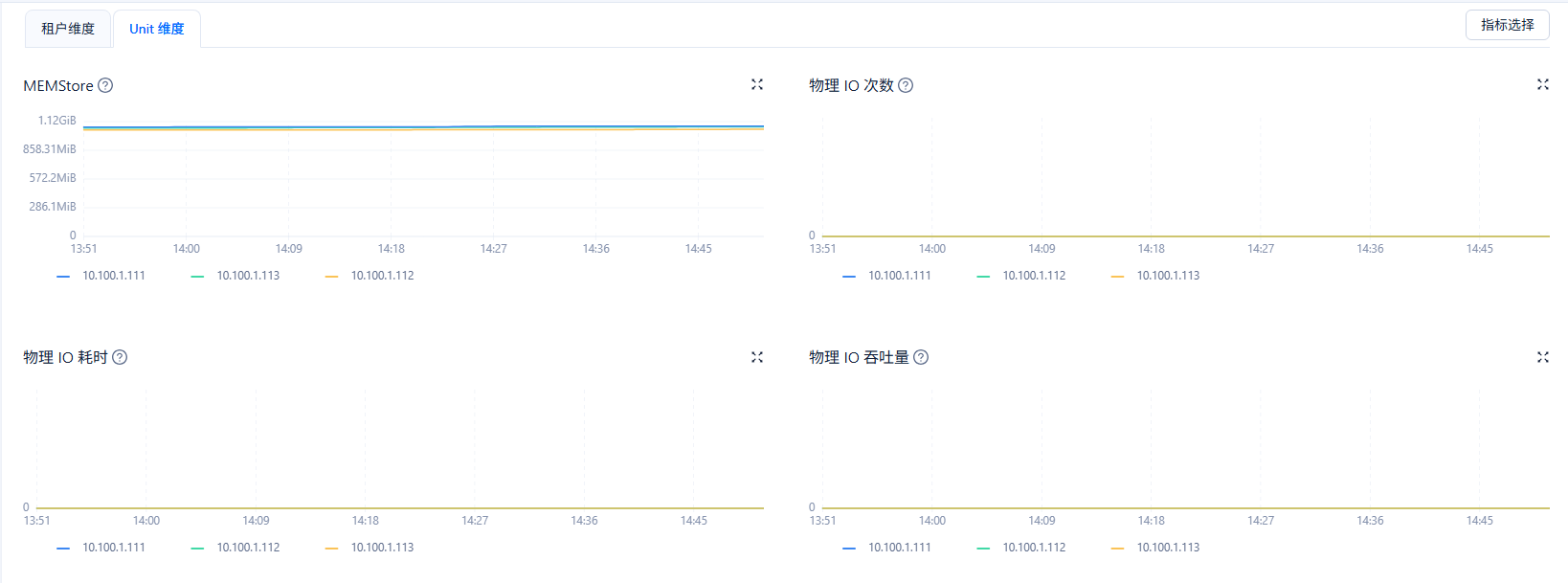
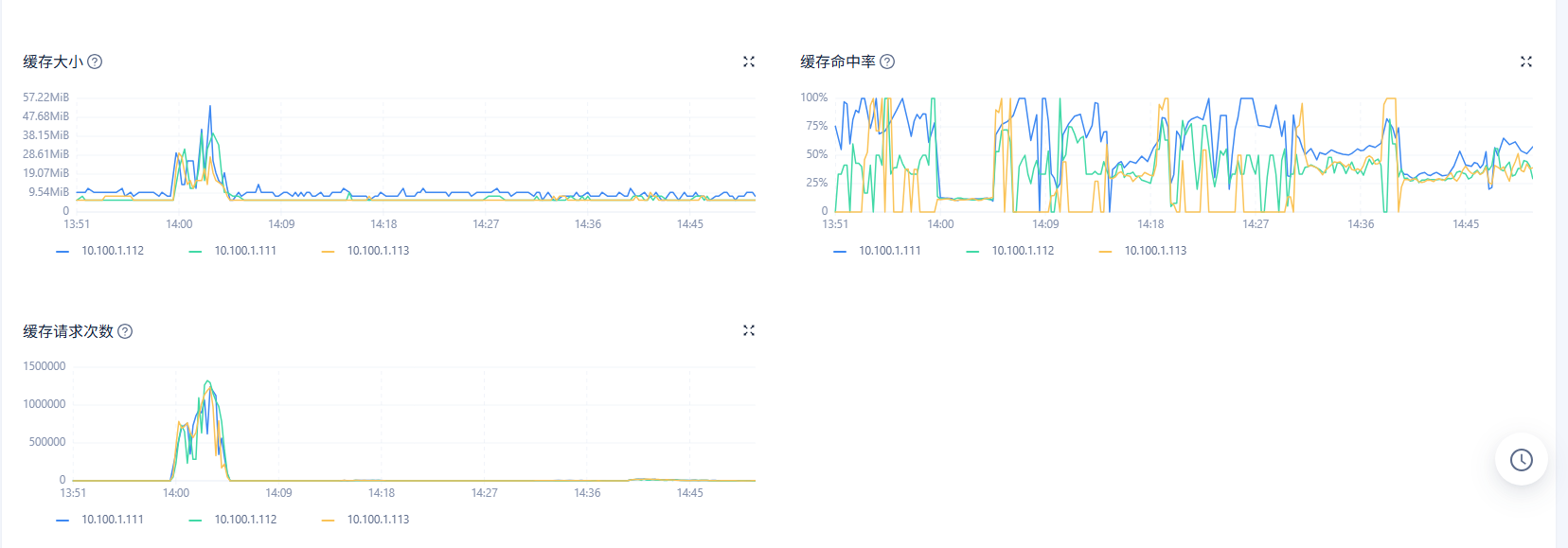
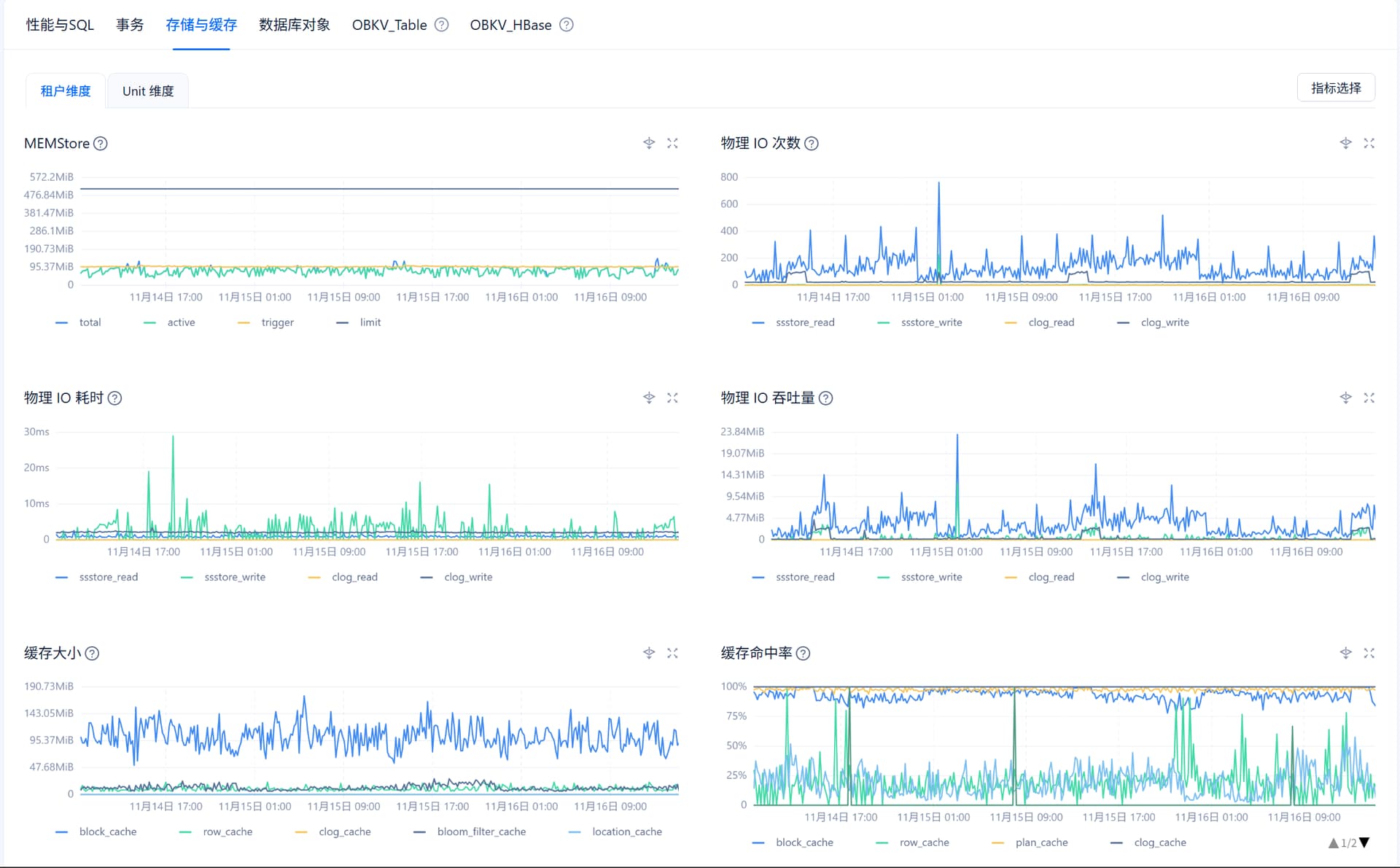
1、在ocp 租户–> 性能监控–>存储与缓存 物理 IO 次数,物理IO吞吐量,物理IO耗时
2、在ocp 租户–> 性能监控–>性能与SQL 看下 租户 CPU 消耗,内存使用率
附件是执行了 这三个的日志
obdiag check run
obdiag check run --cases=sysbench_run
obdiag check run --cases=sysbench_free
nohup.out.log (46.6 KB)
建议把巡检的包 整个发过来 看着是执行报错了么?
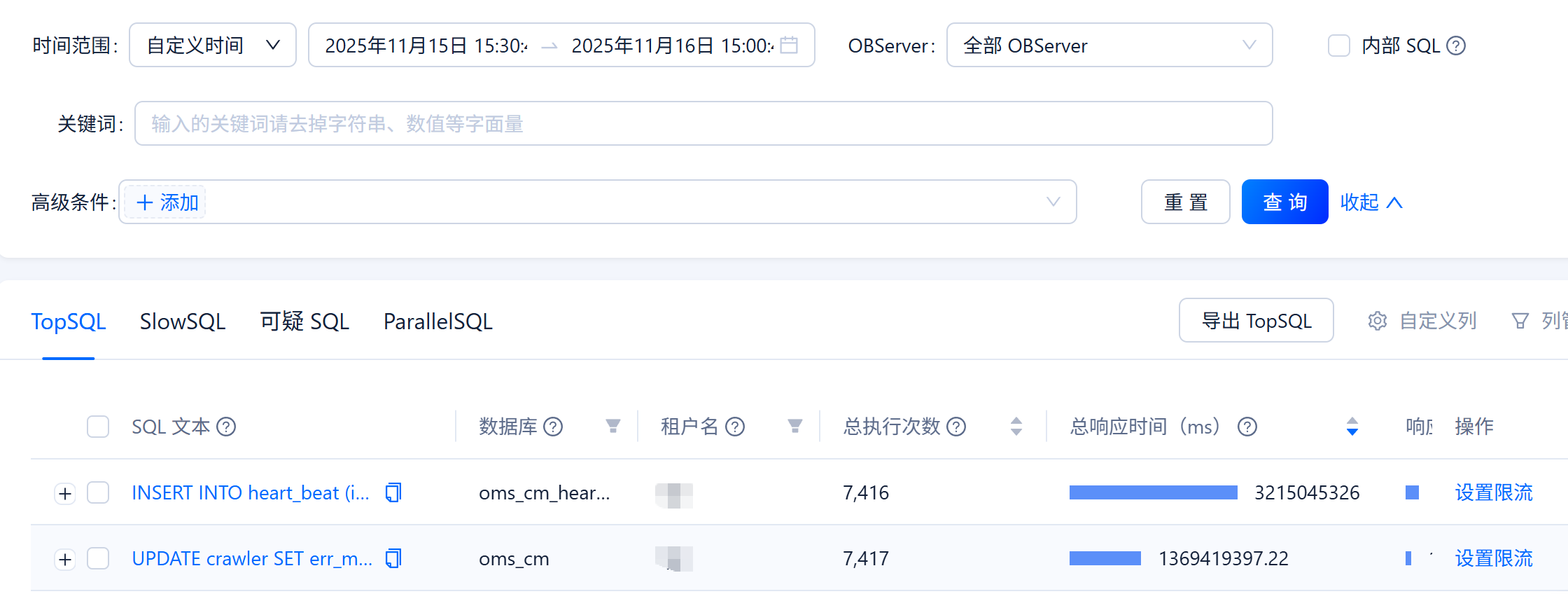
看着物理的io耗时很高呀 在ocp上查看一下top sql 按照最大的响应的时间 排序看看 那些语句时间比较慢
UPDATE crawler SET err_msg = ?, gmt_modified = ?, name = ?, gmt_modified = now() WHERE name = ?;
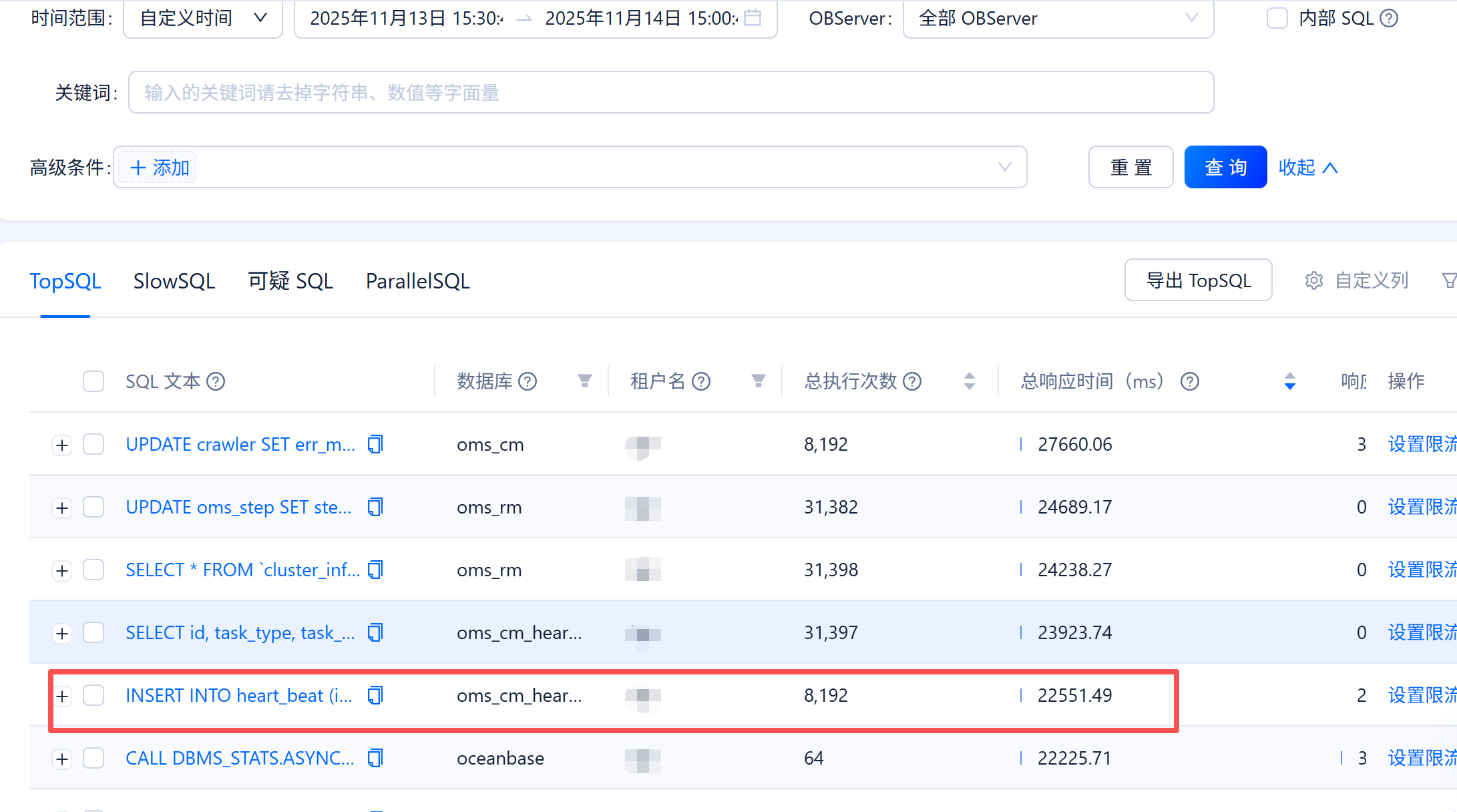
之前正常时间的时候:
能按照最大的响应时间截图么?
看着是往oms的心跳表插入数据呀 除了这两个 还有其他的么? 把这个时间的ocp信息 截图
1、在ocp 租户–> 性能监控–>存储与缓存 物理 IO 次数,物理IO吞吐量,物理IO耗时
2、在ocp 租户–> 性能监控–>性能与SQL 看下 租户 CPU 消耗,内存使用率
使用obdiag收集一下这两个的信息
obdiag gather plan_monitor --trace_id YB420BA2D99B-0005EBBFC45D5A00-0-0 --env “{db_connect=’-hxx -Pxx -uxx -pxx -Dxx’}”
https://www.oceanbase.com/docs/common-obdiag-cn-1000000004222802