

1 个赞
麻烦提供一下原sql文本和涉及的表结构
1 个赞
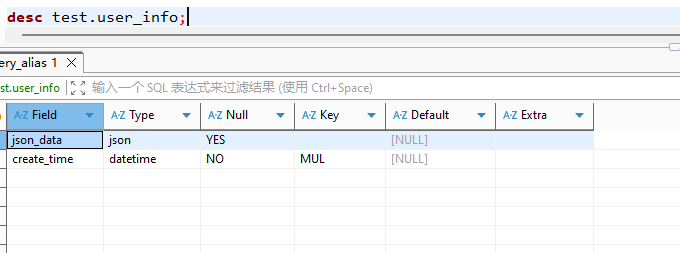
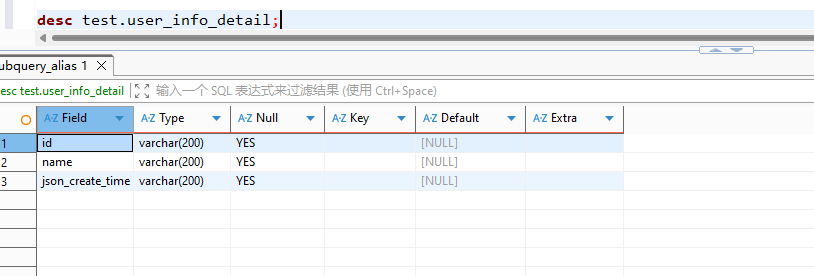
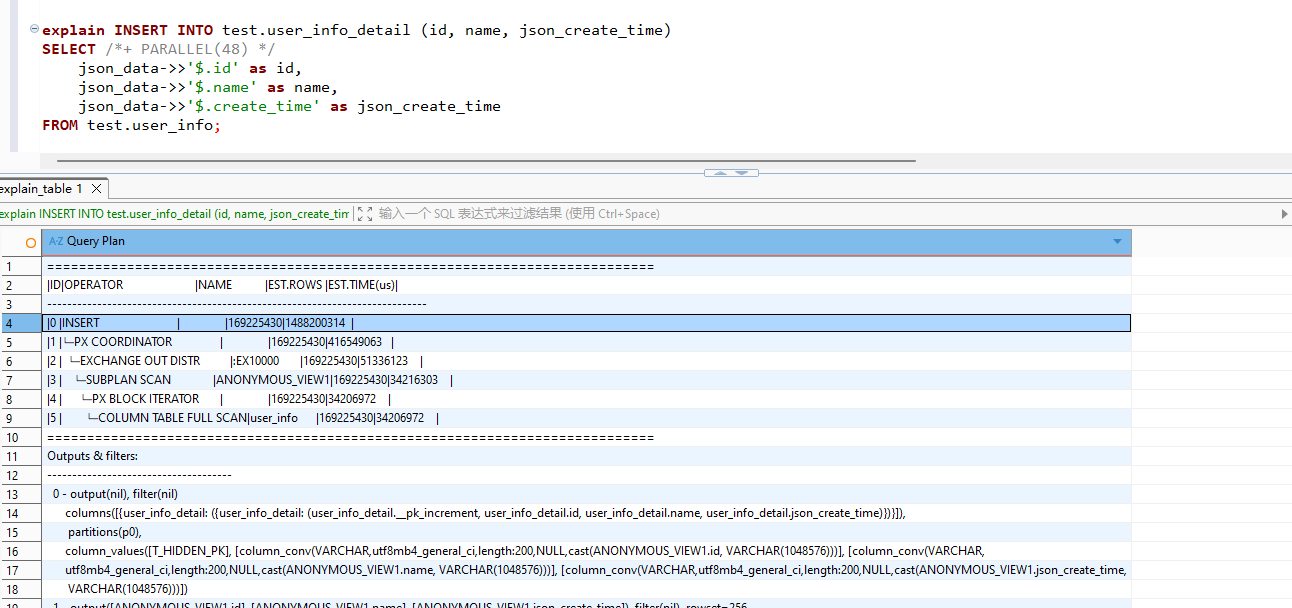
explain INSERT INTO test.user_info_detail (id, name, json_create_time)
SELECT /*+ PARALLEL(64) */
json_data->>’$.id’ as id,
json_data->>’$.name’ as name,
json_data->>’$.create_time’ as json_create_time
FROM test.user_info;
2 个赞
试试分批循环执行
1 个赞
如何实现用的obclient
1 个赞
写个循环存储过程,这需要根据你们的表和业务逻辑自行修改,比如一次跑1000w行
2 个赞
一亿六千万条数据 24分钟插入,相当于每秒十万多条,这个性能在oceanbase算性能好吗,修改配置还能提高吗
1 个赞
可以提供一下不转json格式单独查询的执行计划。看表结构是相当于1.6E全表扫查询的。
1 个赞
这个和全表扫描没什么关系吧,我现在是测试实际可能数据量比一亿六千条还要多,我现在只想怎么能够优化这个插入的效率
1 个赞
insert into selelct 。。。。语句最好的方法还是优化查询sql,insert并不会存在异常慢的问题。
2 个赞
可以试试旁路导入语法
https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000003977057
INSERT /*+ DIRECT(true, 0, 'full') enable_parallel_dml parallel(16) */ INTO tbl1 SELECT t2.col1,t2.col3 FROM tbl2 t2;
Query OK, 3 rows affected
Records: 3 Duplicates: 0 Warnings: 0
2 个赞
看看去掉事务日志能不能快一点
单纯的事务一个个插,或者批量插入,在集群没有其他过分负载的情况下,一般也快不到哪里去。像楼上所说,建议使用旁路导入试试。
如何去掉事务日志