【 使用环境 】测试环境
【 OB or 其他组件 】
【 使用版本 】
【问题描述】 OCP报 租户:ocp_monitor,告警:OceanBase租户长时间未合并,请问怎么排查跟解决
【复现路径】问题出现前后相关操作
【附件及日志】推荐使用OceanBase敏捷诊断工具obdiag收集诊断信息,详情参见链接(右键跳转查看):
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手] 即可召唤小助手,欢迎试用!
【 使用环境 】测试环境
【 OB or 其他组件 】
【 使用版本 】
【问题描述】 OCP报 租户:ocp_monitor,告警:OceanBase租户长时间未合并,请问怎么排查跟解决
【复现路径】问题出现前后相关操作
【附件及日志】推荐使用OceanBase敏捷诊断工具obdiag收集诊断信息,详情参见链接(右键跳转查看):
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手] 即可召唤小助手,欢迎试用!
针对您提到的 OCP 报告租户 ocp_monitor 出现 OceanBase 租户长时间未合并的告警问题,我们可以使用 obdiag 工具进行日志采集和根因分析,以帮助确定并解决问题。
请您使用上述命令进行日志采集,并将采集到的日志压缩包提供给我们,以便进一步分析和确认问题所在。
另外,为了确定具体的问题,在此需要您提供一些信息:
感谢您的配合!
附上敏捷诊断工具 obdiag 使用帮助链接
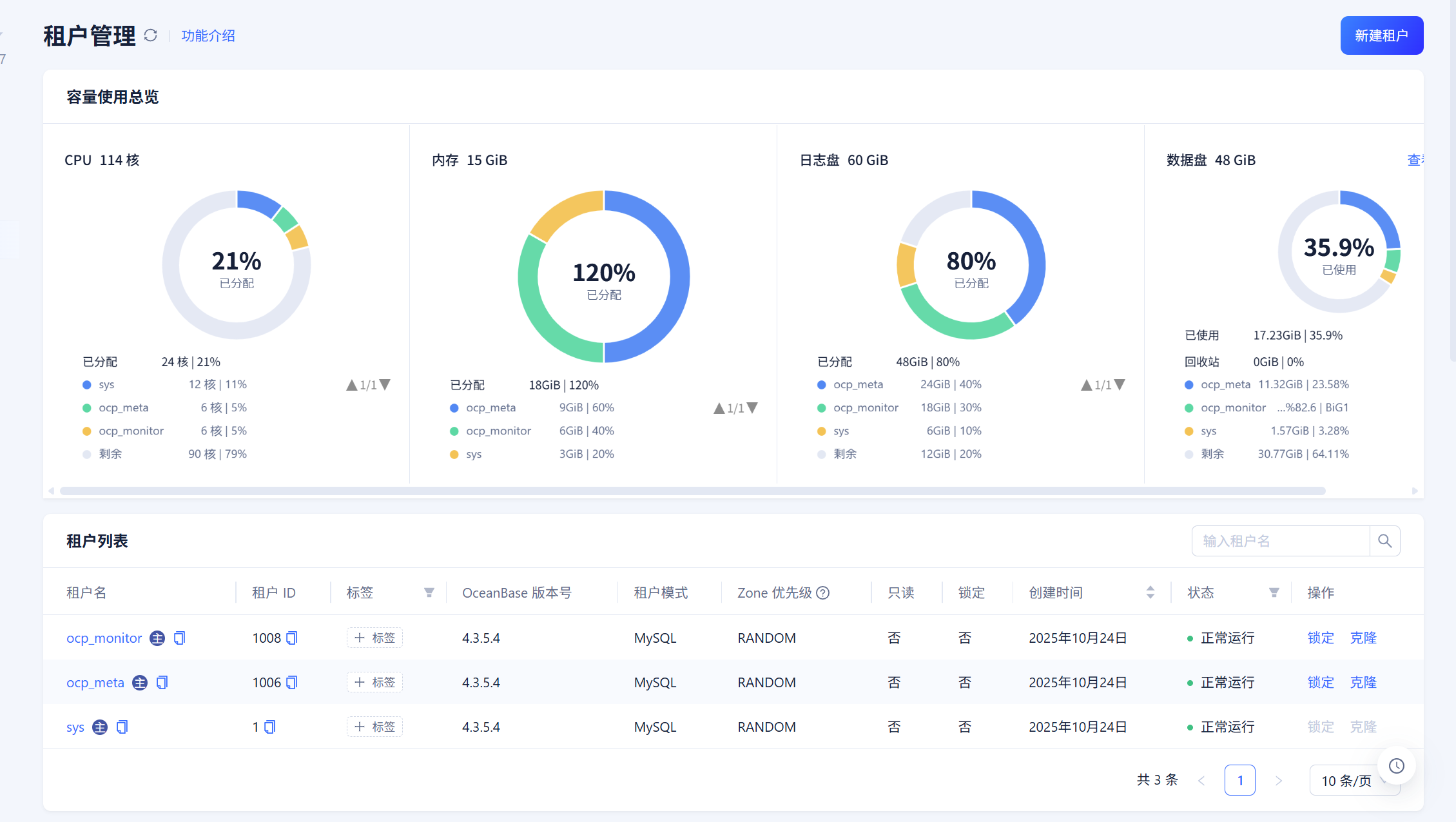
meta集群的log盘和所有租户内存设置多大?
尝试扩容一下log盘或者扩容一下monitor租户的log盘大小,这边看日志存在log盘不足问题。
OCP我就接入了2套测试环境,平时都是空闲状态。 为什么 log 消耗那么大? redo log 循环写入的条件是什么?
老师具体是从哪个输出看出log盘不足的问题的。 是 log_task life cost too much time(palf_id=1, self=“10.1.224.55:2882”, log_id=15608082, log_task={header:{begin_lsn:{lsn:3344076504}, end_lsn:{lsn:3344077052}, log_id:15608082, min_scn:{val:1762846068076625000, v:0}, max_scn:{val:1762846068076625000, v:0}, data_len:492, proposal_id:51, prev_lsn:{lsn:3344076382}, prev_proposal_id:51, committed_end_lsn:{lsn:3344076504}, data_checksum:199791252, accum_checksum:1717112953, is_padding_log:false, is_raw_write:false}, state_map:{val:58}, ref_cnt:0, gen_ts:1762846068075502, freeze_ts:1762846068075502, submit_ts:1762846068075506, flushed_ts:1762846068119485, gen_to_freeze cost time:0, gen_to_submit cost time:4, submit_to_flush cost time:43979}, fs_cb_begin_ts=1762846068191119, log_life_time=115617) 吗? observer.log 输出内容好多,有格式/内容解释吗
log大小最好设置为内存的4倍。meta集群本身自己是会执行ocp的自动任务的。
OceanBase 的日志不采用传统数据库的“循环写入”模式(如 Oracle 的 redo log 循环覆写)。而是采用 追加写(append-only)方式,并通过检查点(checkpoint)机制清理已不再需要的日志,保留满足副本同步和恢复需求的日志数据。
当日志完成多数派持久化并被确认不再需要时,系统会自动清理过期日志以释放空间。
Redo 日志-V4.4.1-OceanBase 数据库文档-分布式数据库使用文档
为什么 oceanbase 租户已分配了14G日志盘,还出现 日志盘不够用。如果是 检查点没有推进,什么原因造成的。
meta集群正在做什么任务么麻烦查询下ocp任务中心看下。
报错显示修改log为14G失败,要求不能小于16G
谢谢老师的解答。 出现问题的时候,OCP已经登录不上去了,已经扩大日志盘了,下次复现的时候再细看。 另外,咱们有SQL可以查历史时间点数据库发生的严重/致命问题吗?
没有统一的sql去查询这种问题触发。一般运维根据ocp告警是哪个模块出问题再通过相关模块的视图进行查询
学习一下
感谢分享