【 使用环境 】生产环境
【 OB or 其他组件 】
ob的版本为4.2.1.3
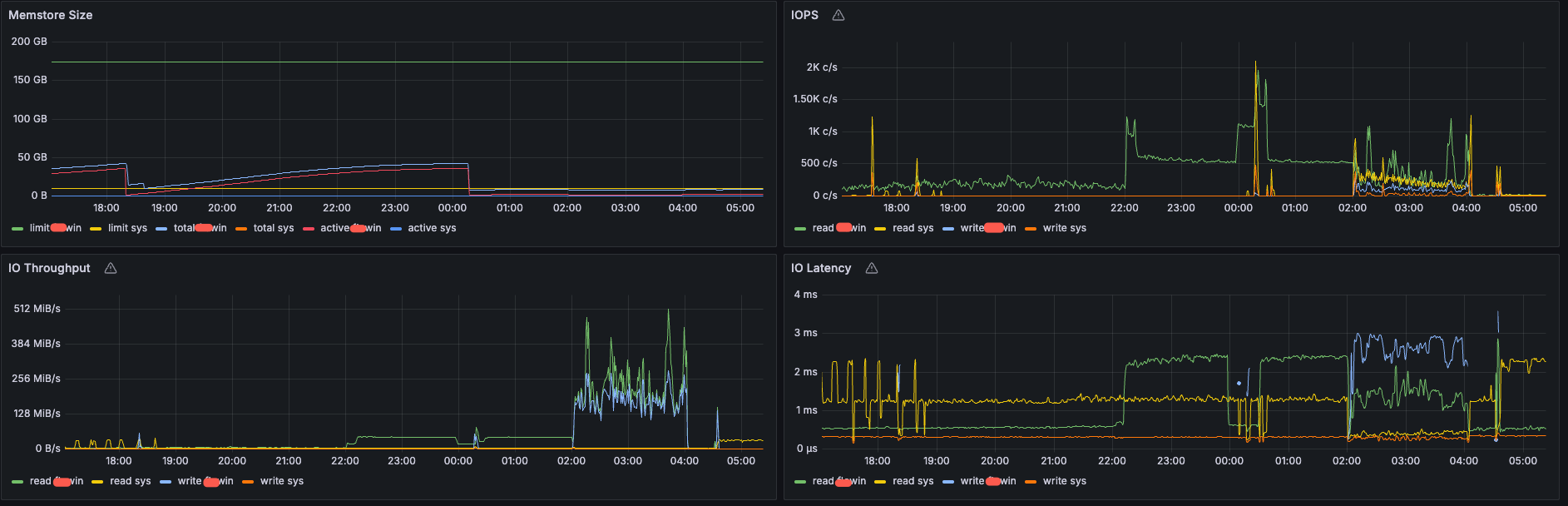
【问题描述】磁盘io特别高
每晚从22点开始磁盘io就变高了,会一直持续到凌晨4点,其中2点开始会有合并到4点会结束合并,目前研发侧也没有定时任务,sql请求量晚上是低峰,数据备份是从4点半开始的
【附件及日志】

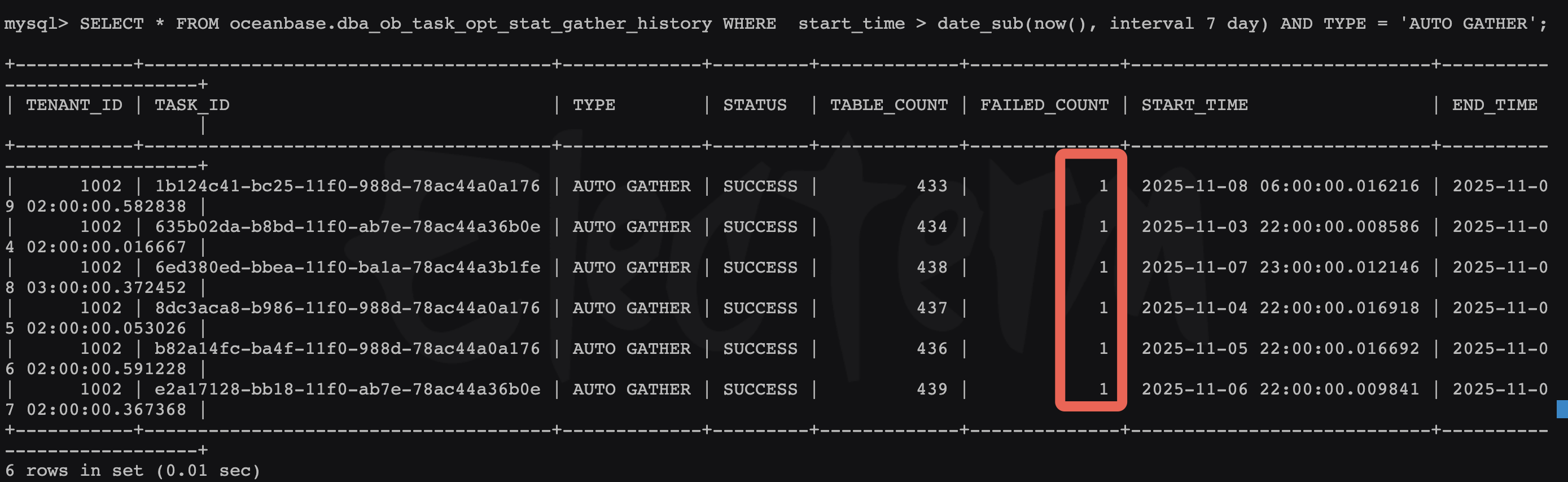
查看了凌晨1点到1点30分的sql 慢日志,也没有奇怪的地方
查看了凌晨1点到1点30分top sql也没有看出特别慢
【 使用环境 】生产环境
【 OB or 其他组件 】
ob的版本为4.2.1.3
【问题描述】磁盘io特别高
每晚从22点开始磁盘io就变高了,会一直持续到凌晨4点,其中2点开始会有合并到4点会结束合并,目前研发侧也没有定时任务,sql请求量晚上是低峰,数据备份是从4点半开始的
【附件及日志】
2-4时间段磁盘io高正常,合并需要数据落盘,minor sstable 合并为major sstalbe。22-02时间段部分节点io高需要看一下相关日志记录信息了。
麻烦筛选下相关节点时间段的grep “IO STATUS” 查看IO配置、实时iops
有些工作都是半夜开始干活啊
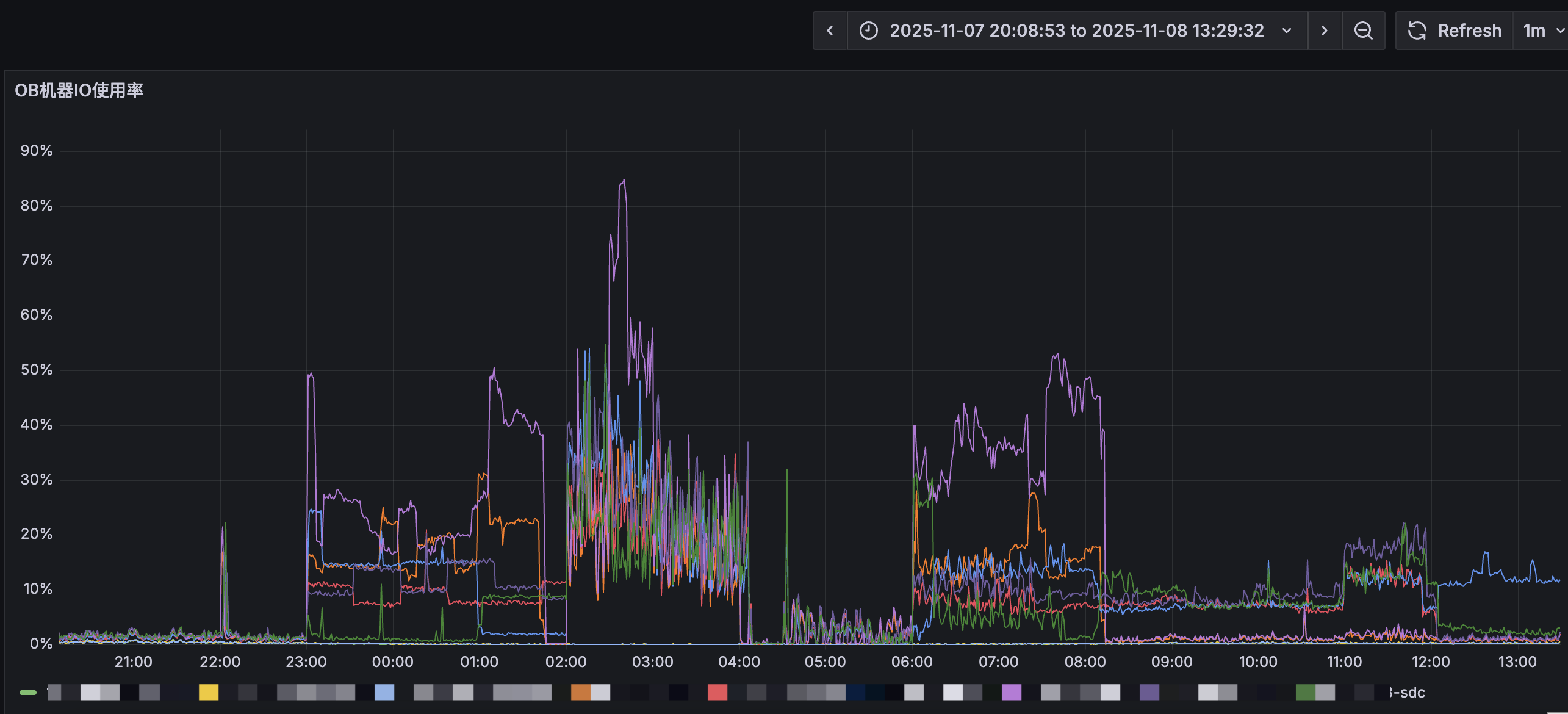
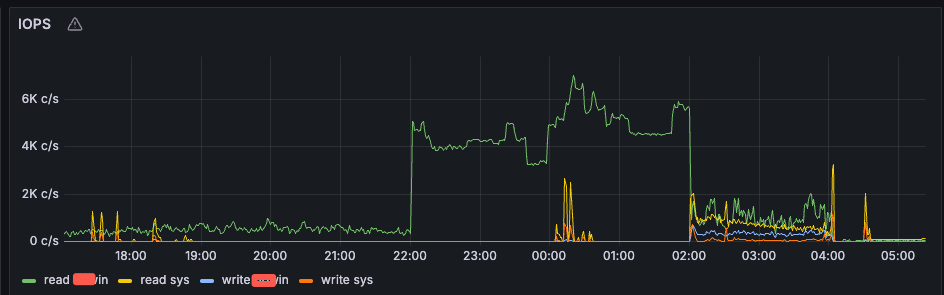
合并是2点开始的,备份是4点半开始的,但是这个io高从晚上10点就开始了,而且其他集群都没有这个问题,是个异常的风险点
没有什么异常,最高的1002租户期间iops才500多
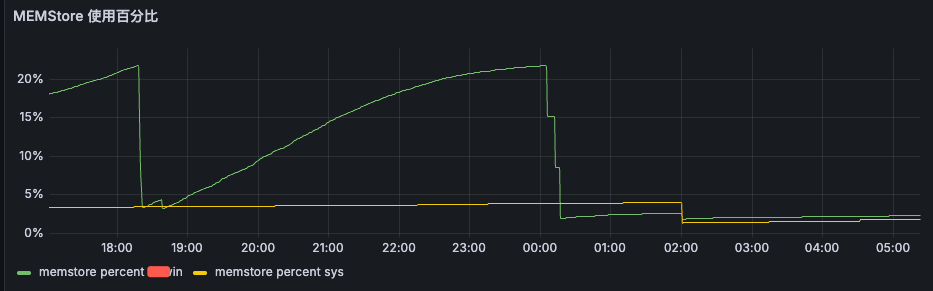
这个io占用率才20%,有的节点从晚上10点开始甚至达到了40%,虽然说不影响业务,但是目前主要的疑问是为何从22点开始就会有那么高的io,可能是个潜在的风险点,需要优化掉
22点开始IOPS明显打高,需要确认下22点打高的业务是正常的吗。
推荐使用obdiag的ash采集分析下这个时间段业务,可以帮你确认下。
https://www.oceanbase.com/docs/common-obdiag-cn-1000000004222807
ob 默认每天 22点 会做统计信息收集,可以看下。
https://www.oceanbase.com/knowledge-base/oceanbase-database-1000000004154958?back=kb
合并的原因吧
合并
估计应该是合并的原因
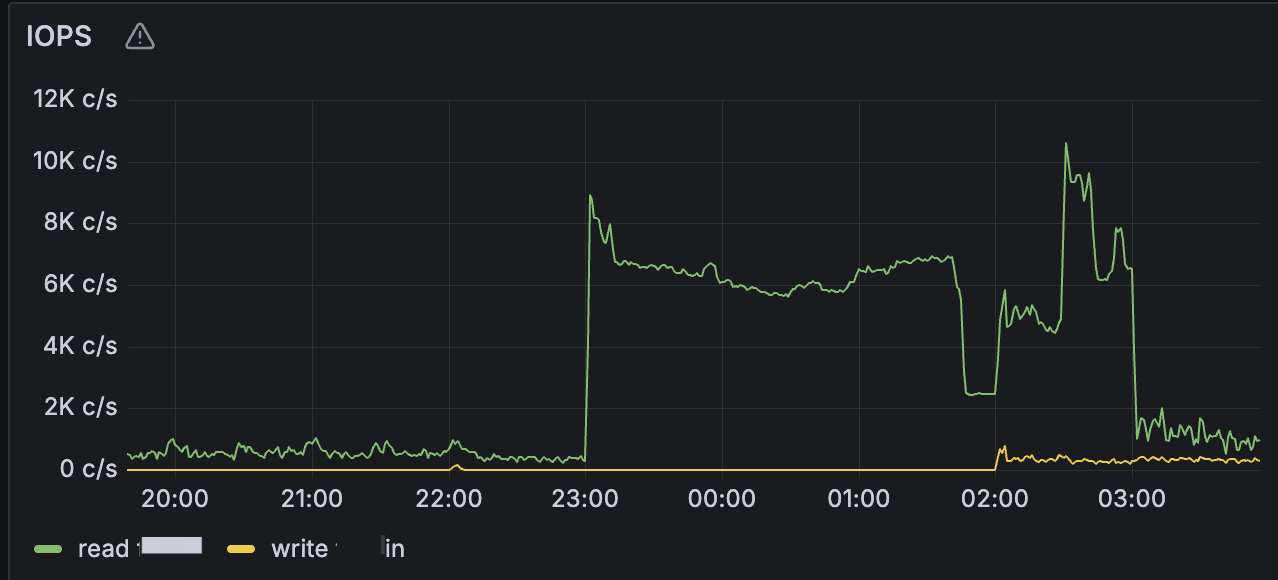
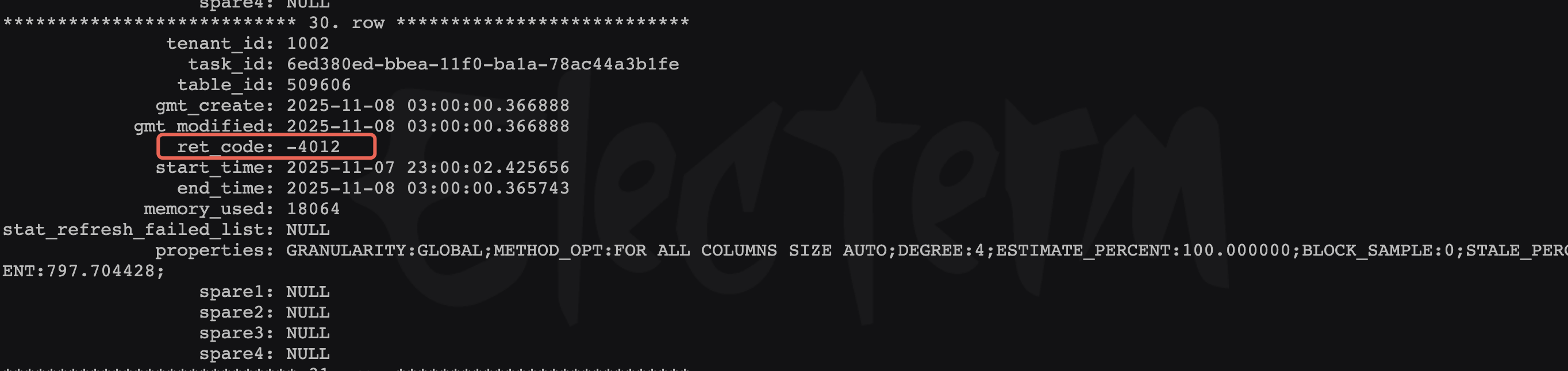
通过修改11月7日统计时间为23:00,发现io变高的开始时间也变成了23:00,所以确定确实是由于自动统计信息导致的,监控如下:
在11月7日下午7点多更改了统计并发,但是在11月7日的23点统计依然超时失败了,更改命令如下:
call dbms_scheduler.set_attribute(‘FRIDAY_WINDOW’, ‘NEXT_DATE’, ‘2025-11-07 23:00:00’);
call dbms_stats.set_table_prefs(‘eo_conewbee’, ‘node_markdown’, ‘degree’, ‘8’);
call dbms_stats.set_table_prefs(‘eo_conewbee’, ‘node_markdown’, ‘granularity’, ‘GLOBAL’);
标记配置跳过大对象:第四个参数配置收集哪些列的统计信息,需要把除大对象外的所有列都加上
call dbms_stats.set_table_prefs(
‘databse_name’,
‘table_name’,
‘method_opt’,
‘for columns col1,col2,col3,… size auto’);
如果为分区表不想过多消耗资源也可以采用下面这种方法:配置不收集全局统计信息
– 一级分区表
call dbms_stats.set_table_prefs(
‘databse_name’,
‘table_name’,
‘granularity’,
‘PARTITION’);
– 二级分区表
call dbms_stats.set_table_prefs(
‘databse_name’,
‘table_name’,
‘granularity’,
‘SUBPARTITION’);
好的,我加上在观察下
目前配置了一下参数:
call dbms_stats.set_table_prefs(‘xxxxx’, ‘node_markdown’, ‘degree’, ‘8’);
call dbms_stats.set_table_prefs(‘xxxxx’, ‘node_markdown’, ‘granularity’, ‘PARTITION’);
call dbms_stats.set_table_prefs(‘xxxxx’, ‘node_markdown’, ‘method_opt’, ‘for columns size auto nm_collection_id,nm_node_id,nm_collection_version,nm_engine_version,nm_status,nm_duration,nm_update_at’);
手动并发20执行了下,花费了1分30秒执行完毕,但是io特别高,都接近100%了,目前自动统计配置为8并发,在进一步观察
call dbms_stats.gather_table_stats(‘xxxxxx’, ‘node_markdown’, degree=>20, granularity=>‘PARTITION’ ,method_opt=>‘for columns size auto nm_collection_id,nm_node_id,nm_collection_version,nm_engine_version,nm_status,nm_duration,nm_update_at’);
还有3个问题辛苦解答一下,多谢老师:
有没有什么定时任务
GV$OB_SQL_AUDIT 查询含 GATHER_% 的 SQL– MySQL 模式下查看调度任务
SELECT JOB_NAME, LAST_START_DATE, NEXT_RUN_DATE, ENABLED
FROM oceanbase.DBA_SCHEDULER_JOBS
WHERE JOB_NAME LIKE ‘GATHER_STATS%’;
-- 停止指定 Job(以实际 Job 名称为准)
CALL DBMS_SCHEDULER.STOP_JOB('GATHER_STATS_AUTO');
3.可以考虑下面方法
– 锁定大表统计信息(防止自动收集)
CALL DBMS_STATS.LOCK_TABLE_STATS(‘test’, ‘big_table_1’);
CALL DBMS_STATS.LOCK_TABLE_STATS(‘test’, ‘big_table_2’);
– 后续手动选择低峰期单独收集
CALL DBMS_STATS.GATHER_TABLE_STATS(‘test’, ‘big_table_1’, degree => 32, estimate_percent => 5);