我是文档工程师,我搞了个AI写文档的工具
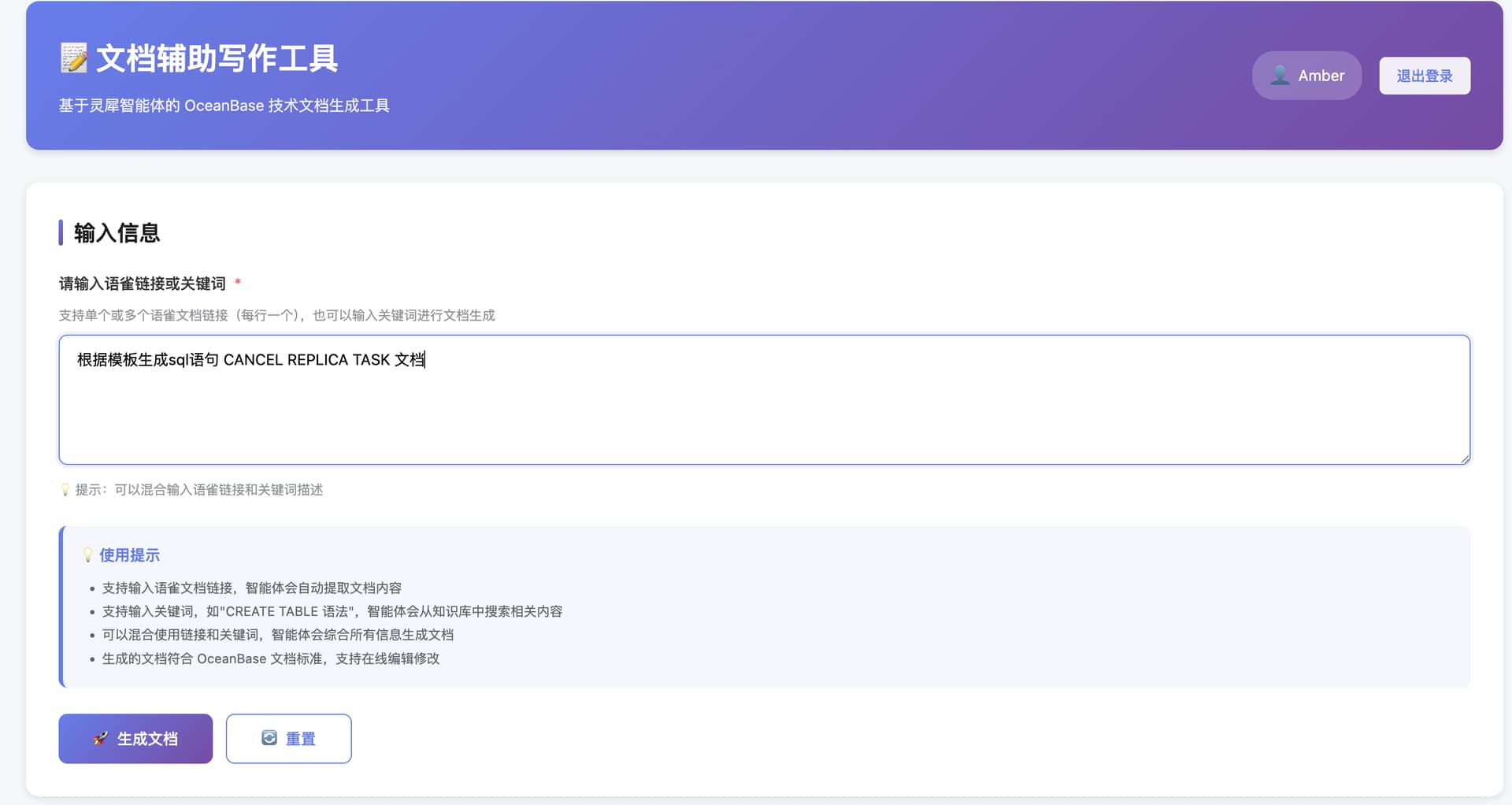
最近在研究怎么用 AI 写 OceanBase 数据库的文档。目标是开发一个文档辅助写作工具,使用 AI 将开发人员的原始文档(如实现文档、提测文档等)转换为可用的用户文档。这个工具主要针对"黑屏"文档(内核文档、命令类文档),因为这类文档对控制台依赖度不高,更容易实现。
工具要具备信息检索和初稿生成两大功能模块。信息检索功能需支持从多个语雀知识库中检索主题相关素材、支持用户勾选素材、自动关键词提取与扩展、同义词识别及关键词权重分析;初稿生成功能需支持多种文档模板(如SQL语法、PL、视图文档、FAQ等),并基于检索素材结合OceanBase文档规范生成符合要求的文档初稿。
我总共搞了3个方案。第一个最蠢,也最重最耗时。第二个主要用 Jupyter + Ollama 是做验证。第三个方案最简单,也是最终的方案,就是用 FastAPI + 灵犀Agent。
第一个方案:语雀集成方案
这个方案最蠢,也最重最耗时。就是用 Java Spring Boot 写一个 Web 应用,然后通过语雀 API 获取文档内容。太重了,办公室网还不好,搞个环境搞到崩溃。当时是用阿里的 AI 助手 oneagent 还是 agentone 搞的,记不清了。还有其他安全和权限各种问题,就不说了。
技术架构
前端: React + TypeScript + Vite
后端: Java Spring Boot
数据源: 语雀知识库API
部署: 单机部署,8080端口
我为啥要用这么蠢的技术栈啊,真是吃了没有经验的亏。Java 真是太难用了,从来没有喜欢过。后端也搞太重了,真是要命。
核心功能
-
语雀知识库聚合
- 支持通过链接获取文档内容
- 支持关键词跨库搜索
- 提供知识库和文档列表查询接口
-
降级与调试机制
- Token缺失或权限异常时自动降级为Mock数据
- 通过响应头
X-Yuque-Debug返回调试信息 - 前端展示调试信息,便于快速定位配置问题
-
文档生成
- 基于模板系统生成Markdown文档
- 支持多种文档类型(SQL、PL、FAQ等)
- 集成AI服务进行内容生成
技术实现要点
-
降级策略
- 服务层(YuqueServiceImpl)维护
lastDebugInfo状态 - 控制器统一附加
X-Yuque-Debug响应头 - 前端控制台和页面Alert展示调试信息
- 服务层(YuqueServiceImpl)维护
-
数据流
- 前端输入语雀链接/关键词 → 后端搜索/内容接口
- 后端请求语雀API(携带X-Auth-Token)→ 失败时降级为Mock
- 后端通过响应头返回调试信息 → 前端展示
- 用户选择素材后发起生成 → 返回Markdown
未完成功能
- 缓存策略(Caffeine/Redis)未实现
- 前端在线编辑和自动保存未实现
- 文档深加工(Word/PDF转换)未实现
不搞了,搞不了。时间太长了,我怎么能这么蠢呢。太难了,太难了。代码也不开源了,怕被骂。也怕大家高血压。
第二个方案:Jupyter + Ollama
这个方案主要用 Jupyter + Ollama 是做验证。就是用 Jupyter 写一个 Notebook,然后通过 Ollama 本地模型生成文档。主要还是我太懒了,不想写代码。而且 Python 可比 Java 轻太多了,Jupyter 直接跑就行了。用的是个我本地的小模型,质量还行。不过我测试的数据集很少,我也没搞向量存储,就是直接用的文本。
技术架构
技术栈: Python + Jupyter + Ollama
数据源: 本地文档目录(docs/sql、docs/faq等)
AI服务: Ollama本地LLM(deepseek-r1:latest)
部署: 本地运行,无需服务器
核心功能
-
文档检索(retrieval.py)
- 基于关键词匹配的简单检索
- 支持短语匹配(用引号包围)和单词匹配
- 多层级评分:标题匹配权重最高(+3),文件名次之(+2),内容最低(+1)
- 短语匹配额外加分:标题中短语+10,内容中短语+5
- 智能片段提取,返回最相关的内容片段
-
文档生成(generator.py)
- 基于模板系统生成Markdown文档
- 支持多种文档类型(SQL、PL、FAQ、视图等)
- 调用Ollama API生成内容
- 自动清理思考过程标签(
<think>)
-
文档优化(llm_optimizer.py)
- 多轮优化机制
- 第一轮:基础生成(使用模板)
- 第二轮:优化中英文空格和标点符号(带质量检查)
- 第三轮:结构优化(带质量检查)
- 质量评分系统,自动判断是否需要优化
实现细节我就不说了,目前看就是个玩具。这个方案验证了Python + Jupyter + Ollama的可行性。虽然功能简单,但证明了本地LLM可以生成可用的文档。主要问题在于检索算法太简单,没有向量存储,检索效果一般。不过对于验证阶段来说,够用了。主要是 Jupyter 我太爱了,太方便了。解决了很多环境问题。
第三个方案:FastAPI + 灵矽Agent
这个方案最简单,也是最终的方案,就是用 FastAPI + 灵矽Agent。灵矽Agent 是蚂蚁集团的一个 AI 助手,支持流式输出和思考过程展示。灵矽就是蚂蚁的 Dify 吧。主要是能白嫖人家的 AI 功能。但是满血模型只有 DeepSeek-R1,不过我觉得也够用了。
灵矽Agent 的 API 接口很方便,直接调用就行了。
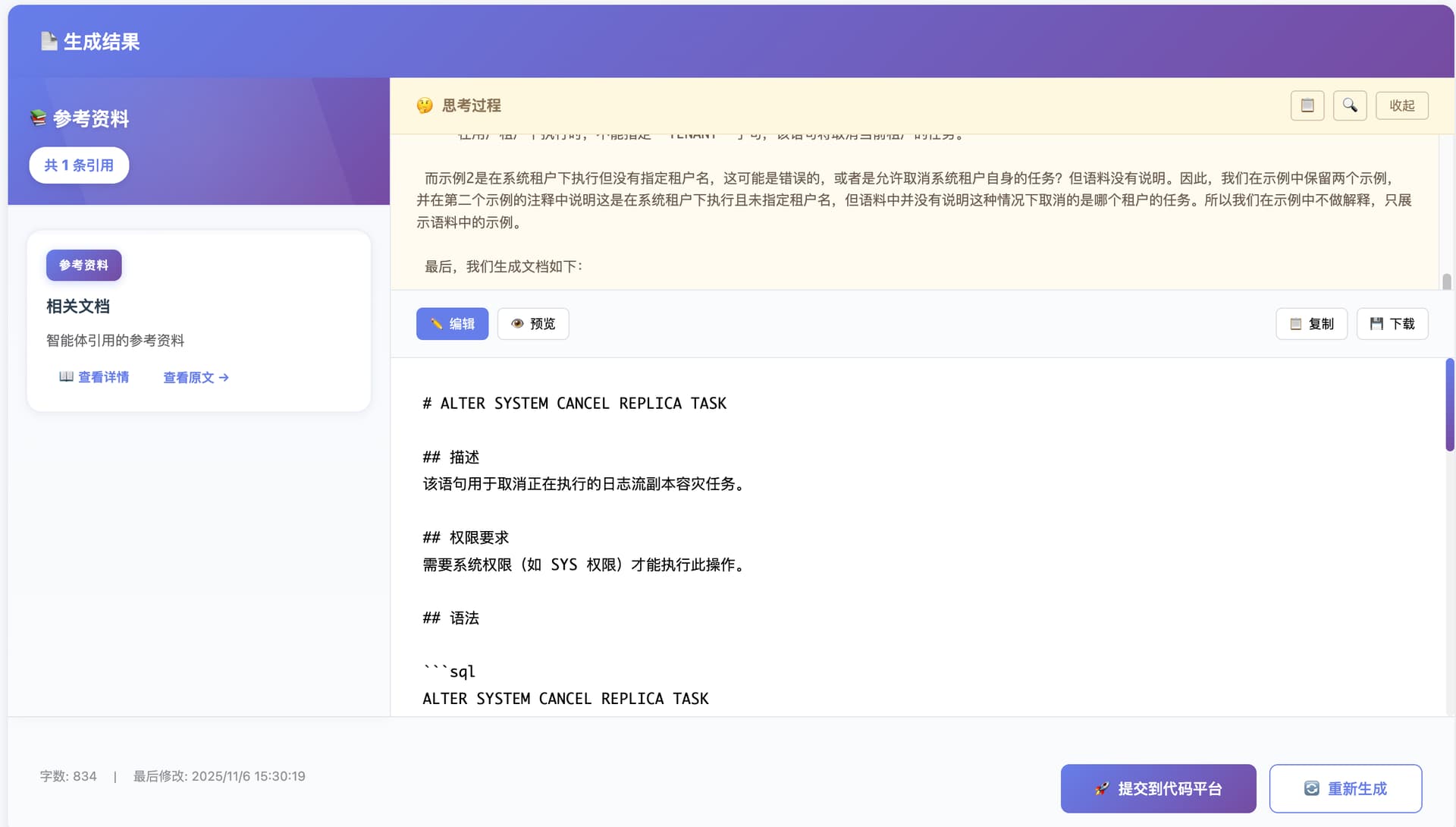
流式输出处理,实时更新文档内容,思考过程独立展示,文档引用自动标注。
技术架构
前端: Vanilla JavaScript(无框架)
后端: FastAPI + Python 3.12
AI服务: 蚂蚁集团灵矽Agent API
数据库: SQLite(可升级PostgreSQL)
部署: Docker + Nginx
核心功能
-
用户认证系统
- JWT Token认证(30天有效期)
- 用户注册/登录
- 密码bcrypt加密
- Token验证接口
-
文档生成(流式)
- 支持语雀链接输入
- 支持关键词描述
- Server-Sent Events流式输出
- 思考过程独立展示(CHAT_CoT)
- 文档引用自动提取和标注
-
前端功能
- Markdown实时渲染(Marked.js)
- 代码高亮(Highlight.js)
- XSS防护(DOMPurify)
- 密码可见性切换
- 注册时密码二次确认
-
代码平台集成
- 点几个就能提文档 PR 了
这个方案的关键是灵矽的工作流设计。我改了很多次,也测试了很多次。这个方案最省事,反正用也是几个人用,SQLite 也够了。虽然没有缓存,但是重复请求消耗资源也不大。我的使用场景对响应时间要求也不高。
这个工具除了文档工程师能用,SA 后面也能用。把内部不适合透出的信息过滤掉整出个用户版,美滋滋。
目前在测试中,因为工作流需要反复测试修改。慢慢测试,测完一个上线一个。只能本地用,部署还没搞。后面还要慢慢优化。比如知识库怎么能做成自动的。调用语雀的api轮询文档变化。需要在外围做一些开发。
最后的最后,感谢开发哥哥们帮忙设计工作流,帮忙写项目代码。开发哥哥们除了帮助实现我的想法,还要给我科普为啥要这么实现,毕竟我是那么的好学。通过这个项目积累点工程经验,也是不错的。我即是这个项目的 PD 也是 PM,也算是全新的体验了。
这是蚂蚁版的解决方案,外部想使用的话,把灵矽换成 Dify 就行了。最后再贴几张图吧