

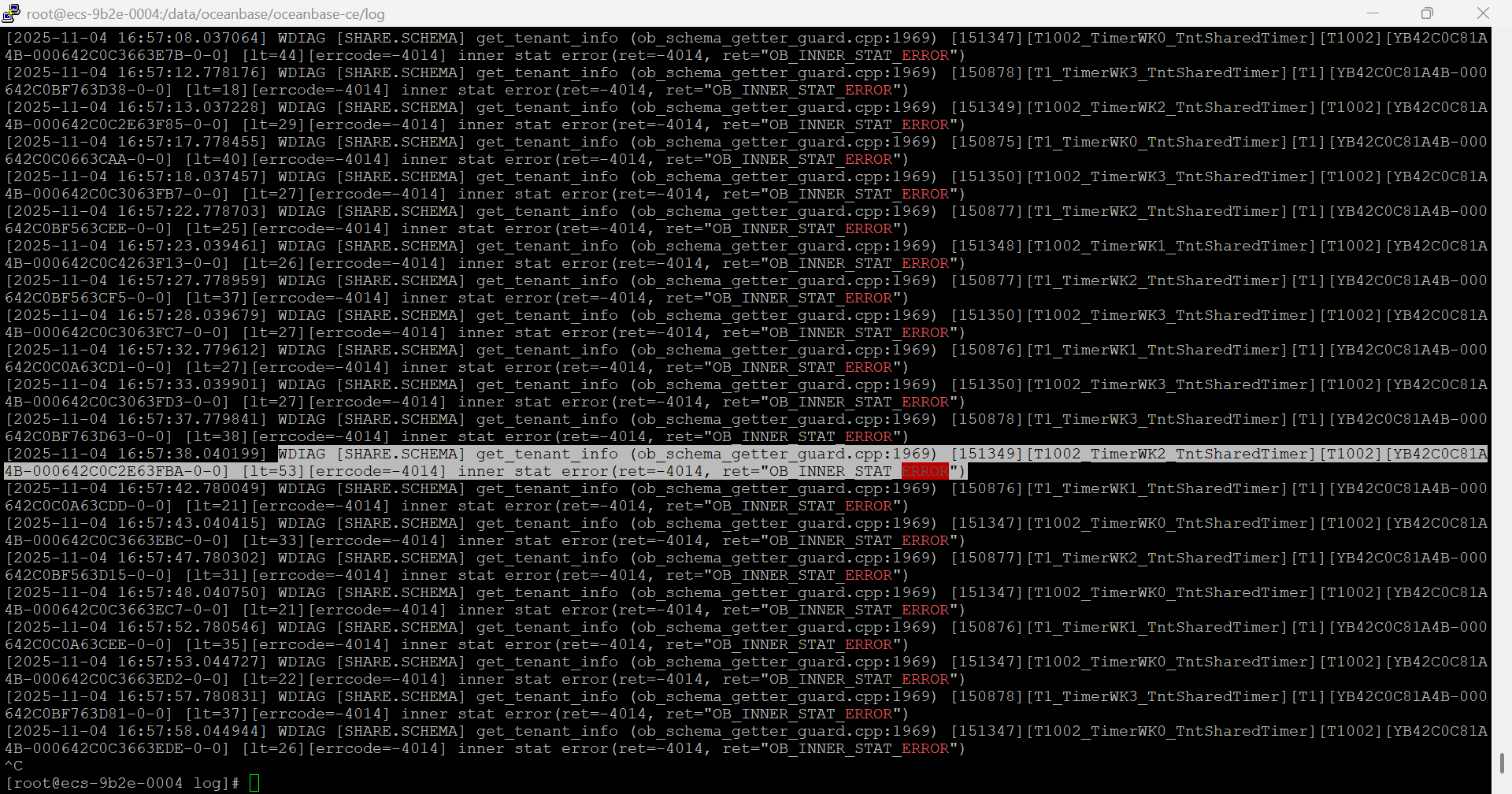
部署的一个集群,重启后一直报错WDIAG [SHARE.SCHEMA] get_tenant_info (ob_schema_getter_guard.cpp:1969) [151349][T1002_TimerWK2_TntSharedTimer][T1002][YB42C0C81A4B-000642C0C2E63FBA-0-0] [lt=53][errcode=-4014] inner stat error(ret=-4014, ret=“OB_INNER_STAT_ERROR”),请问是什么原因呢?需要怎么解决?
1 个赞
内部错误需要看一下详细日志,麻烦提供一份附件。
1 个赞
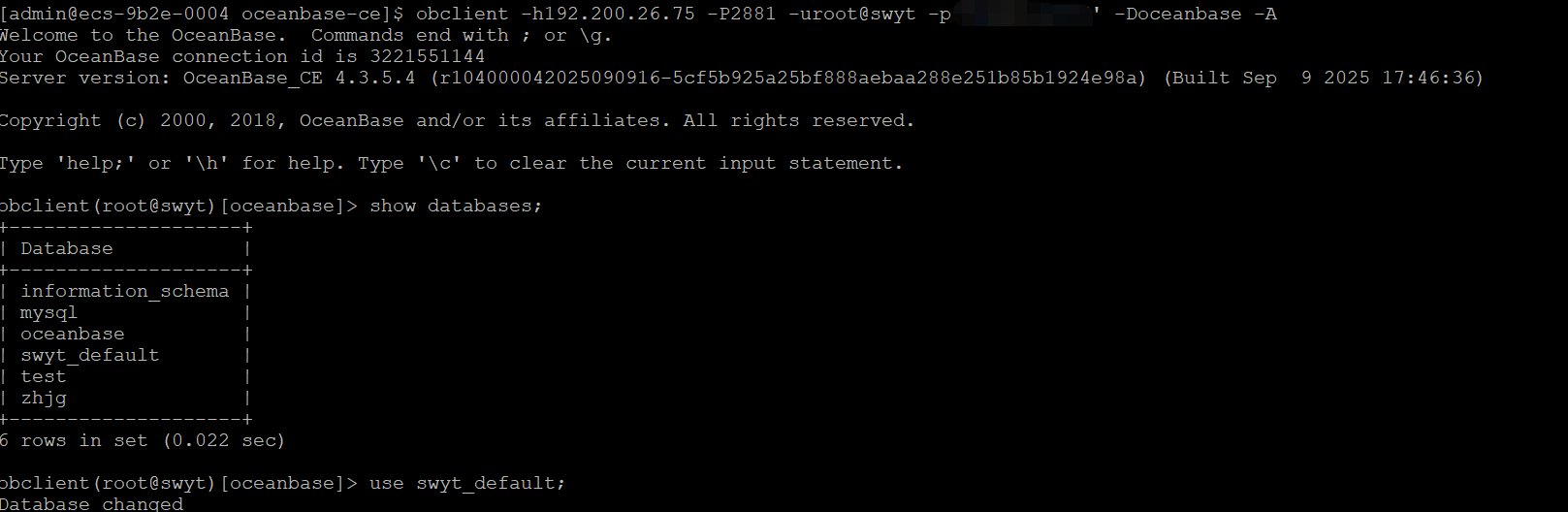
SHOW VARIABLES like ‘version_comment’; 查一下ob的版本信息
1 个赞

目前这个报错 ob现在什么状态 看着执行什么都在报错 集群目前是可用状态么
1 个赞
尽量提供详细信息
麻烦重启一下,提供一份覆盖重启时间的日志。上面那份没有覆盖到。
由于要急用,能登录就先把数据导出然后重装了 ![]()
之前重装的集群,最近重启后又出现上面的报错问题了,更奇怪的是,这个集群是用obd单独部署的,部署后用ocp进行了接管,现在在ocp上能操作集群重启,但是用obd cluster start、restart的话,就会像上面一样一直卡在connect to observer的阶段,偶然问了一下AI,回答大概是ocp接管集群后可能会修改元数据之类的东西,导致再使用obd操作的时候就会有问题?想问下确实是会有这样的情况的吗?如果有的话这是不是正常的,是否需要优化?假设被ocp接管后的所有集群都只能用ocp运维,如果有一天ocp崩了的话风险是不是很大? ![]()
以下是AI的回答:
根据文档库中的信息,使用 OBD 部署的 OceanBase 集群无法通过 obd cluster restart 重启,但可以通过 OCP 正常重启,可能的原因和背景如下:
可能原因分析
- OBD 与 OCP 管理权限或状态不同步
- 如果 OCP 已经接管了由 OBD 部署的 OceanBase 集群,但未正确同步集群状态或配置,可能导致 OBD 认为集群处于异常状态而拒绝执行重启操作。
- 根据文档 使用 OCP 接管 obd 部署的集群 和 OceanBase 安装部署工具 V1.3.0,从 OBD V1.3.0 版本开始支持使用 OCP 接管 OBD 部署的集群。一旦被 OCP 接管,部分运维操作(如重启)可能会受到限制或需要在 OCP 中统一管理。
- OBD 缓存或本地元数据不一致
- OBD 在本地维护了部署配置(位于
~/.obd/cluster/<deploy_name>),如果该配置与实际集群状态不一致(例如手动修改过参数、节点下线等),可能导致obd cluster restart失败。 - 而 OCP 是通过实时监控 Agent 获取集群状态,因此可以更准确地发起重启流程。
- 资源检查失败导致 OBD 拒绝重启
- OBD 在执行重启前会进行预检(pre-check),包括内存、磁盘、端口占用等。若检测到资源不足或冲突,即使集群当前运行正常,也可能阻止重启。
- 相比之下,OCP 的重启逻辑可能更加灵活,允许强制操作。
- 版本兼容性问题
- 某些旧版本的 OBD 存在对 OCP 集群管理的支持缺陷。例如:
- 文档提到:“修复升级非 OBD 部署的 OCP 集群时出现的异常问题” —— OceanBase 安装部署工具 V3.1.2
- 这说明 OBD 对非原生管理对象的行为可能存在不确定性。
- 启动方式差异:systemd vs 手动脚本
- OCP 使用 OBAgent 或 systemd 管理进程生命周期,能够更可靠地拉起
observer进程。 - 而 OBD 重启依赖于其自身的部署上下文环境(如用户权限、环境变量、路径设置等),若环境发生变化(如临时目录清理、文件权限变更),可能导致失败。
建议解决方法
- 确认是否已被 OCP 接管
- 若集群已由 OCP 接管,请优先使用 OCP 进行运维操作。
- 如需继续使用 OBD 管理,可参考文档将元数据同步回去:
cp -rf ~/.ocp-installer/cluster/<metadb_cluster_name> ~/.obd/cluster/
参见文档:常见问题
2. 检查 OBD 日志定位具体错误
- 查看 OBD 执行
restart时的输出日志(通常位于~/.obd/log/),查找具体的失败原因,如:
obd cluster display <deploy_name>
obd cluster edit-config <deploy_name>
- 尝试重建配置或重新导入部署信息
- 若怀疑配置损坏,可尝试导出当前集群配置并重新加载。
- 升级 OBD 至最新版本
- 确保使用的是最新版 OBD,以避免已知 bug 影响操作。
总结
根据文档库中的信息,当 OBD 部署的 OceanBase 集群被 OCP 接管后,OBD 可能因状态不同步或权限受限而无法完成重启操作,而 OCP 凭借其集中式管理能力仍可正常控制集群重启。
建议统一使用一个管理工具(OBD 或 OCP)进行运维,避免交叉管理带来的状态混乱。
AI分析的没问题。
ocp接管后就在ocp进行集群运维操作即可。ocp崩了这种情况使用obd也会存在obd节点宕机问题
如果ocp崩了的话,我这被接管的集群就不能通过obd进行启停等运维操作了吧。
关于AI给出的第一个解决办法,我好想没找到这个.ocp-installer的路径在哪,这种方式是可行的吗?
cp -rf ~/.ocp-installer/cluster/<metadb_cluster_name> ~/.obd/cluster/
不可行的,文件格式不一样。如果担心ocp异常可以给ocp搭建高可用架构
好的,不过我看了ocp高可用好像是企业版才有的功能哈哈
社区也有的
但是还有一种情况,就是通过obd部署的ocp,在接管了自己的元数据observer后,会导致ocp也没法用obd进行启停等运维,一旦ocp出现问题挂掉的话,通过obd启动都启动不了 ![]()
不对的,正常情况下ocp就是用obd来进行启停的,obd启动不了应该是参数文件与ocp的参数不一致可能是该过密码或者其他参数导致