

【 使用环境 】生产环境
【 OB 】社区版OceanBase_CE-v4.3.5.2
【问题描述】分区表查询很慢,空表select要6s左右
SQL 详情收集
obdiag gather plan_monitor --trace_id YB420BA2D99B-0005EBBFC45D5A00-0-0 --env"{db_connect=’-hxx -Pxx -uxx -pxx -Dxx’}"
https://www.oceanbase.com/docs/common-obdiag-cn-1000000004222802
2 个赞
看着收集的有问题呀 trace_id替换成 你执行语句的trace_id
–根据时间和执行语句查询trace_id
select query_sql,svr_ip,TRACE_ID,client_ip,TENANT_NAME,user_name,DB_NAME,ELAPSED_TIME,RET_CODE,FROM_UNIXTIME(ROUND(REQUEST_TIME/1000/1000),’%Y-%m-%d %H:%i:%S’) from GV$OB_SQL_AUDIT
WHERE REQUEST_TIME>=‘2024-04-05 14:34:00’ and lower(query_sql) like ‘%select%’;
收集的信息 应该在这个目录下吧 他这个整个发过来 你这个发的全没有办法看
obdiag_gather_pack_20251104183144
又了解了个新案例
这个很奇怪 之前是没问题的 有很多数据 后面清空数据之后 读表就非常慢 重建表 收集统计信息 各种都试过 读表就是很慢
问题应该在分区上 但是不清楚为什么读空表这么慢
获取执行计划的耗时有点异常 耗时几百毫秒 执行的时间很短

ob_plan_cache_percentage 这个是不是设置过小了 这个参数查一下
这个也查一下
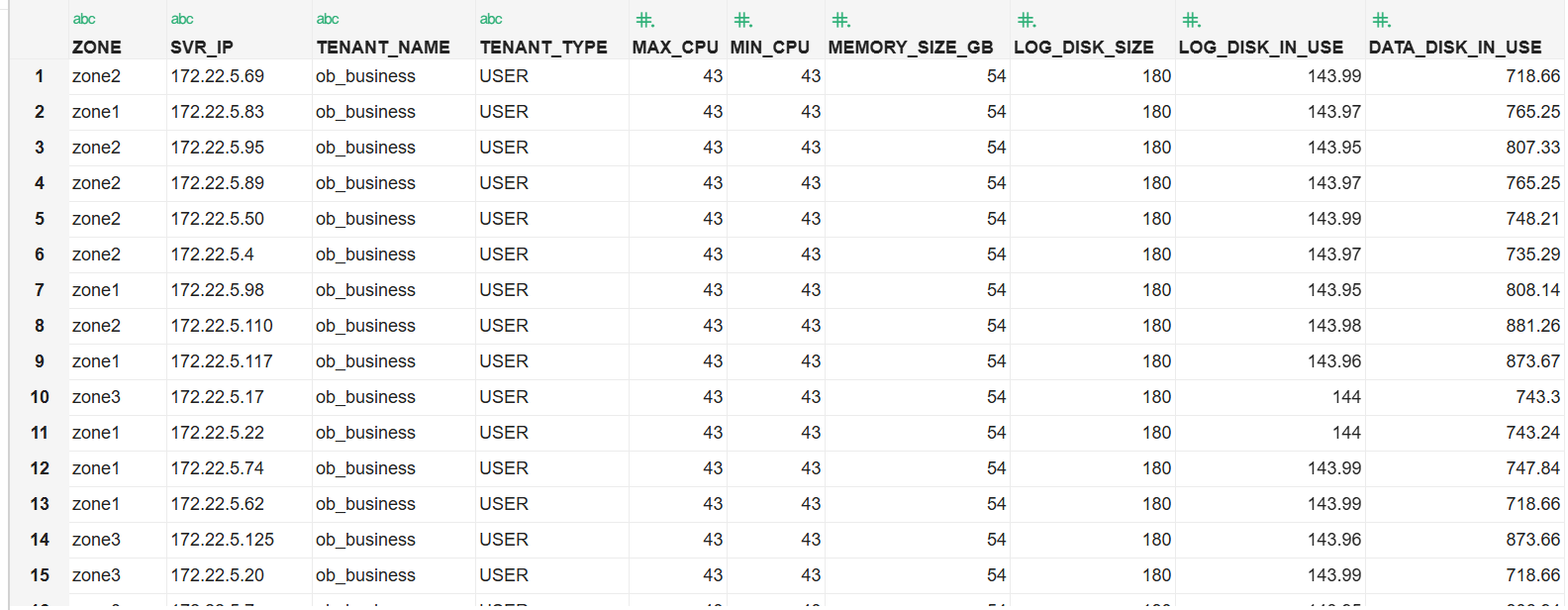
select a.zone,a.svr_ip,b.tenant_name,b.tenant_type, a.max_cpu, a.min_cpu,
round(a.memory_size/1024/1024/1024,2) memory_size_gb,
round(a.log_disk_size/1024/1024/1024,2) log_disk_size,
round(a.log_disk_in_use/1024/1024/1024,2) log_disk_in_use,
round(a.data_disk_in_use/1024/1024/1024,2) data_disk_in_use
from oceanbase.gv$ob_units a join oceanbase.dba_ob_tenants b on a.tenant_id=b.tenant_id order by b.tenant_name;

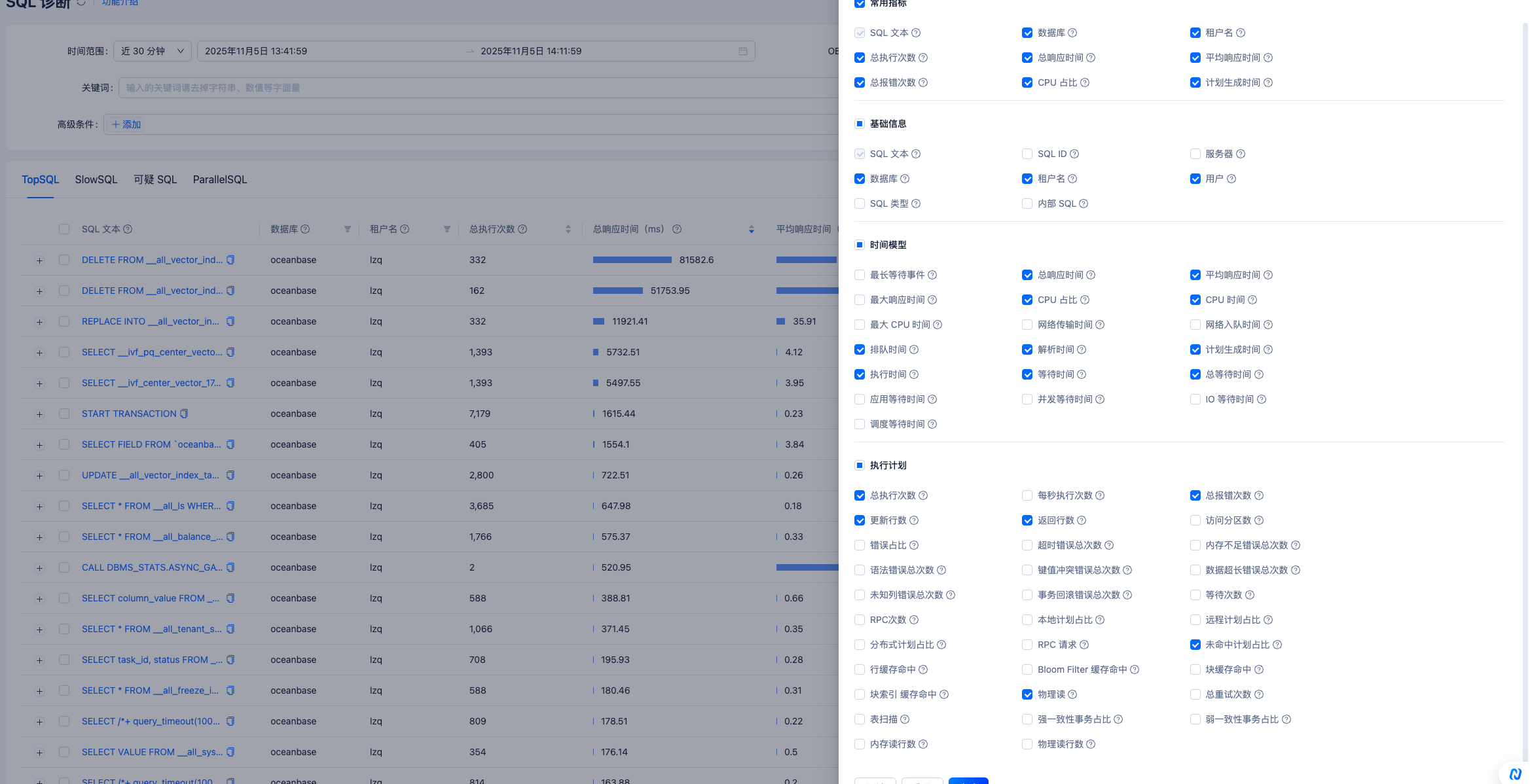
ocp上按照这样查一下 top sql 按照你之前执行的语句时间来查看
ob_plan_cache_percentage 建议把这个值调整到10吧 应该是设置的过小 导致的执行计划的缓存的比较频繁又重新生成执行计划
不用 ODC 、 NAVICAT 这种平台类工具,用 mysql 、obclient 这种命令行客户端工具查下SQL试试呢,先排查平台类工具查询原因。
ob_plan_cache_percentage 建议把这个值调整到10 再观察看看
好像没什么提升,insert也慢,几十条就要2min,之前很快,除了truncate也没做什么操作
把insert插入慢的使用obdiag收集一下 truncate操作是同一个表么?这个操作频繁么?
insert优化了分区,现在还好。主要是空分区表的select很慢,感觉还是执行计划的生成有问题,节点数多会影响执行计划的生成时间吗?
这些分区会经常删除么?你在用obdiag收集一下,分布式计划可能会生成计划树的长度会长写 应该也不会问题的,建议还是收集一下信息