小哲豆腐花
2025 年11 月 4 日 11:54
#1
【 使用环境 】生产环境
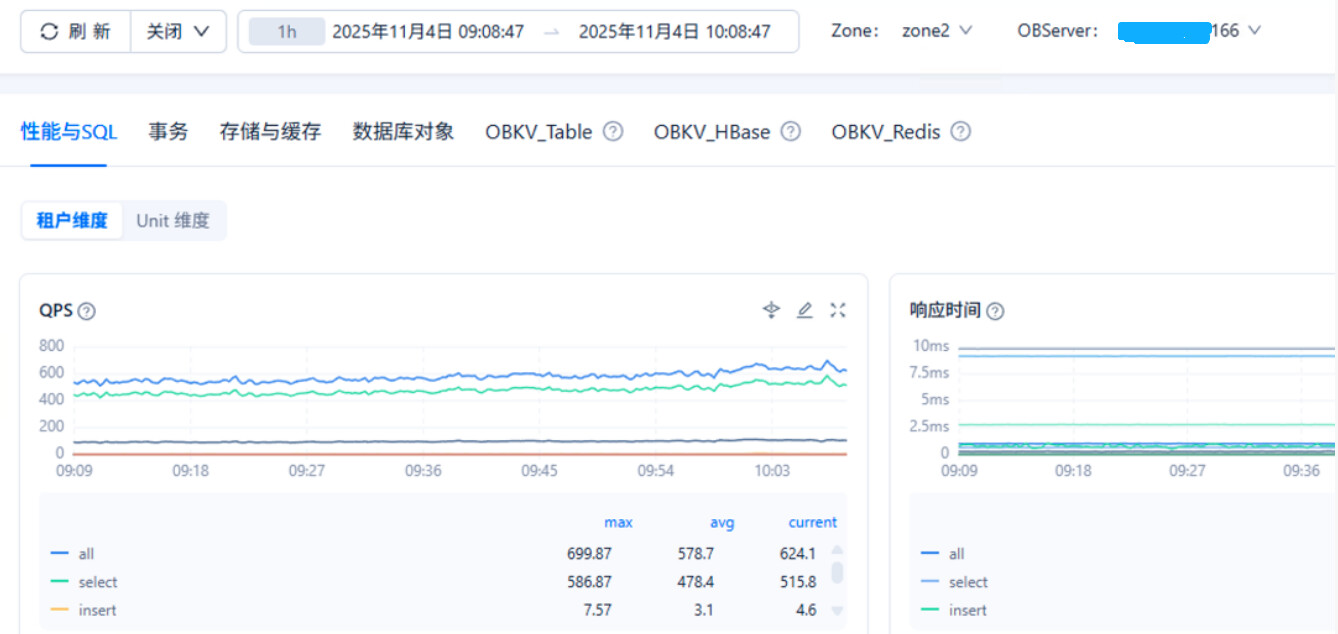
zone2 observer2.xxx.xxx.xxx.166
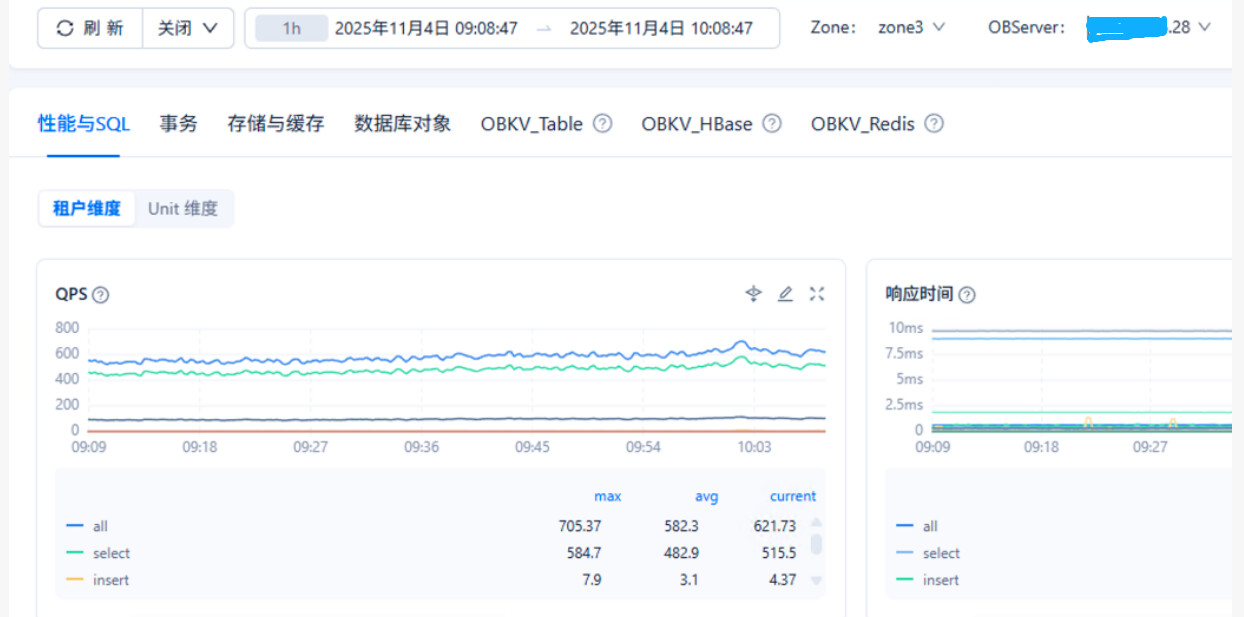
zone3 observer3.xxx.xxx.xxx.28
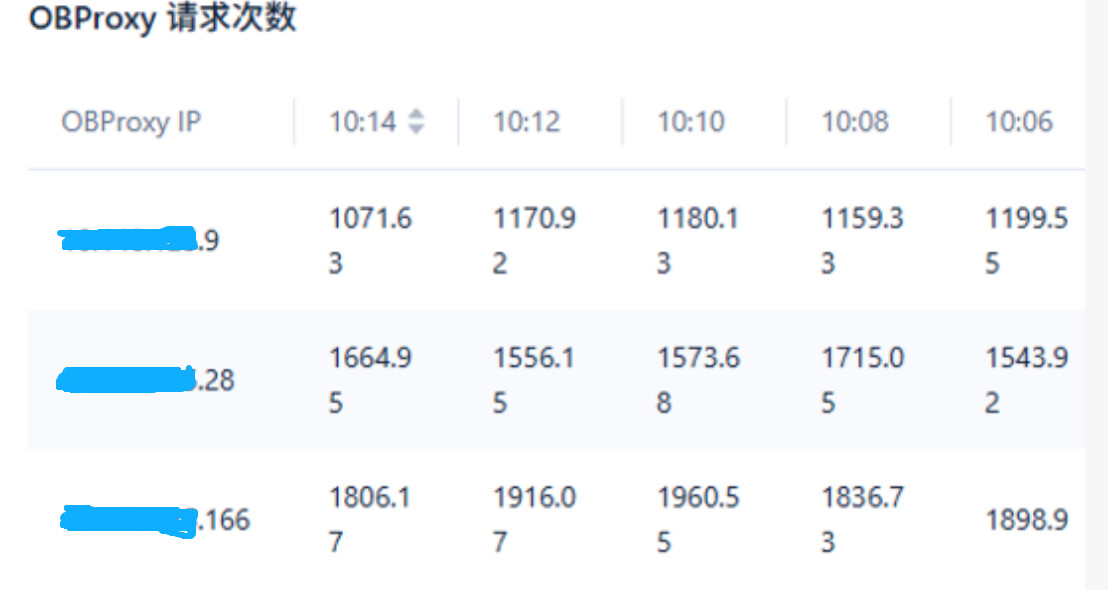
2、查看obproxy分发情况
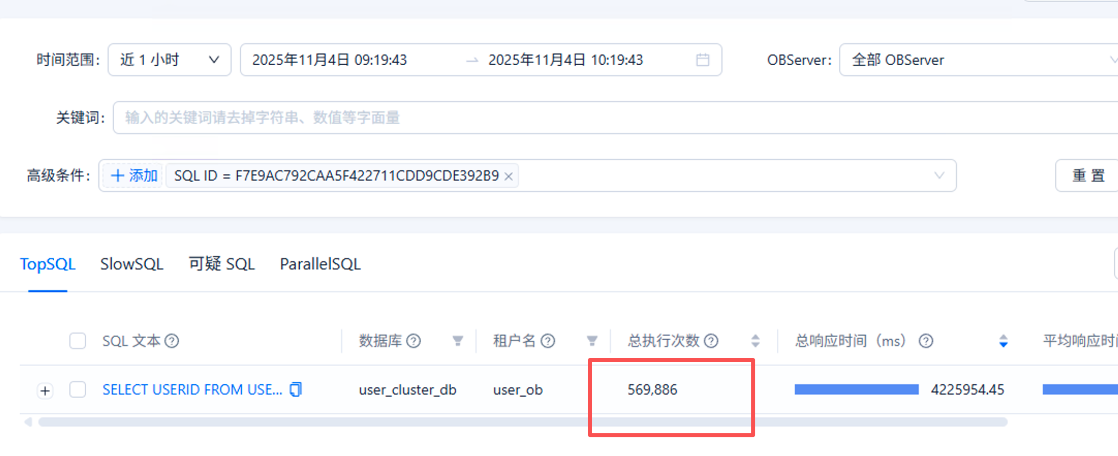
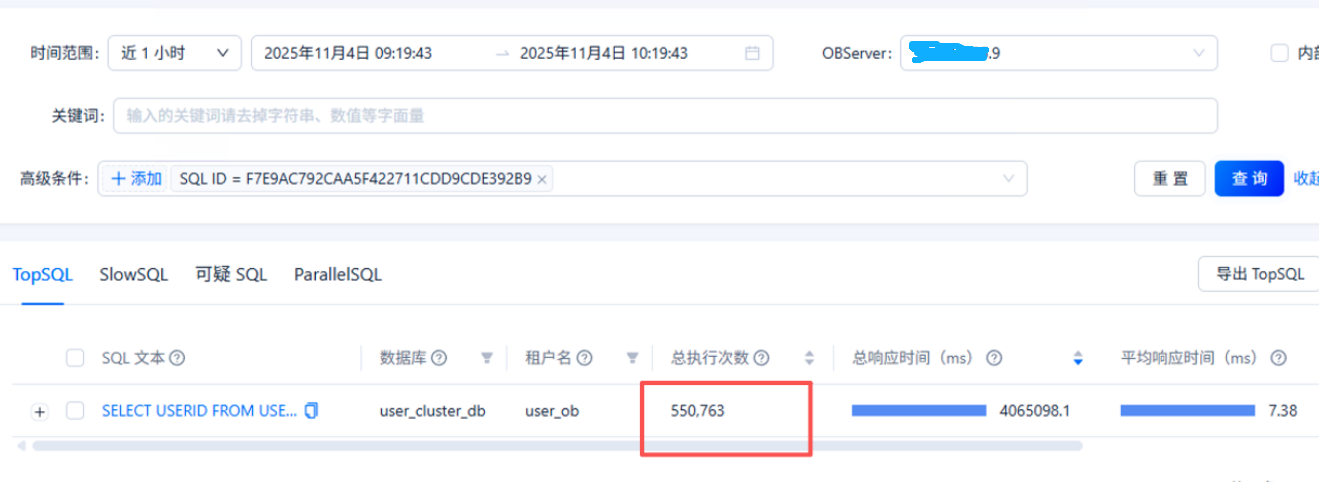
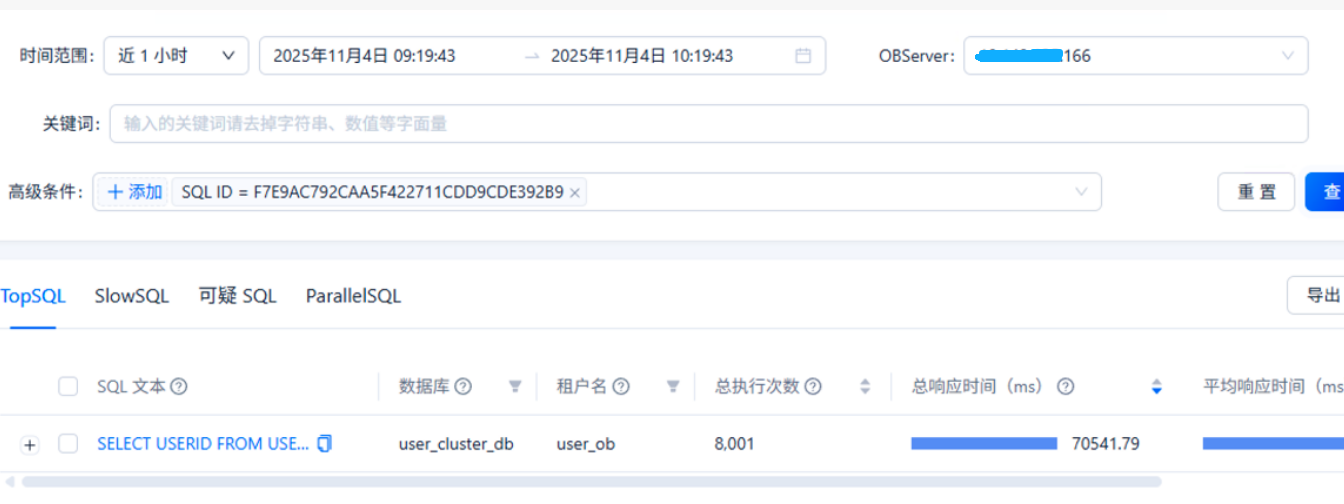
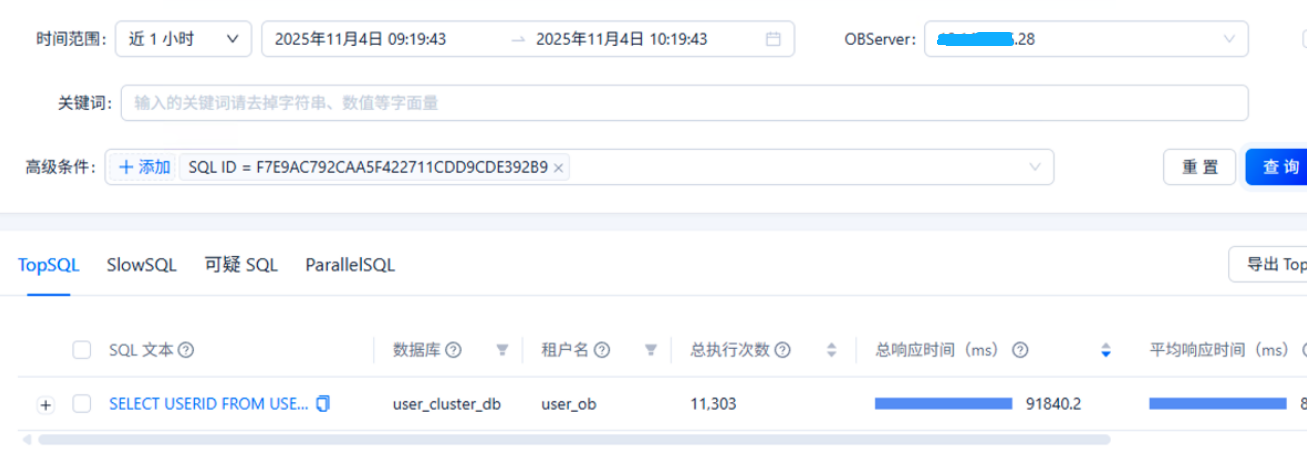
3、查看指定sql id的执行情况
全部observer
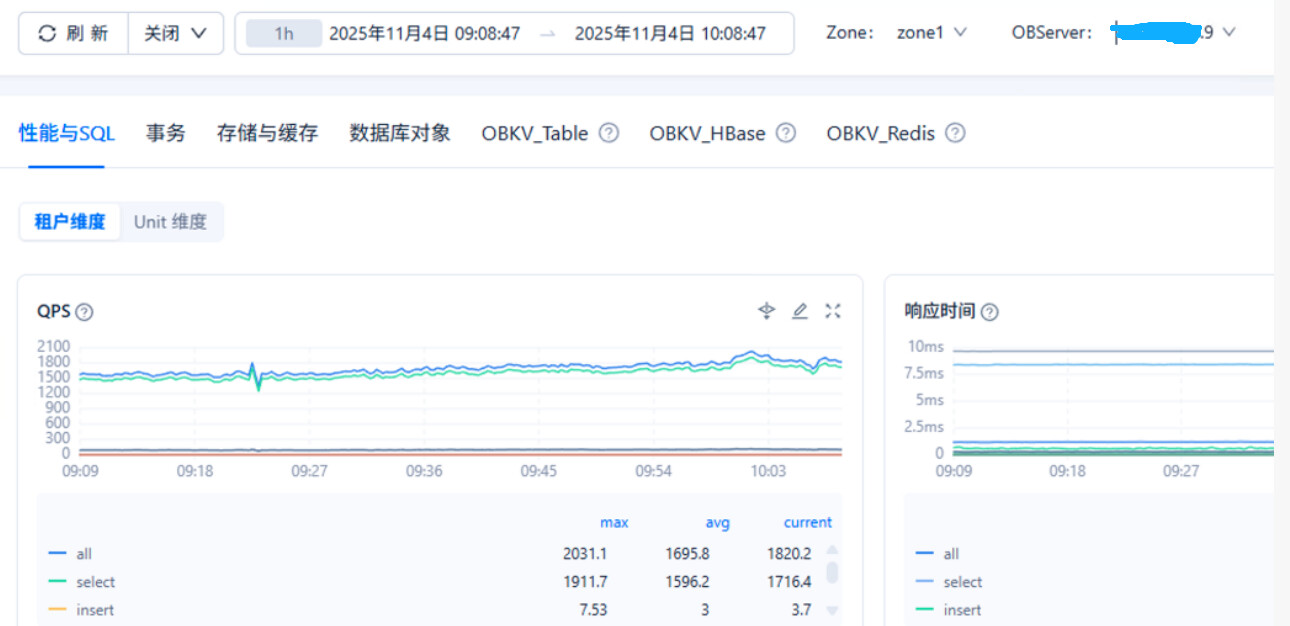
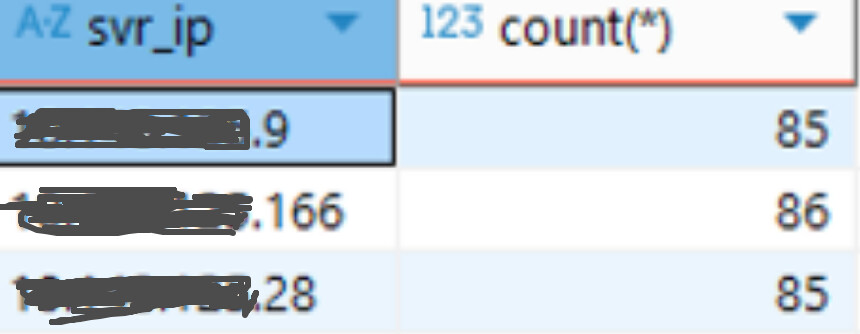
observer1-xxx.xxx.xxx.9
observer2-xxx.xxx.xxx.166
observer2-xxx.xxx.xxx.28
4、primary zone配置为random
5、查看表分区leader分布情况
select zone,svr_ip,role,count(*) from oceanbase.dba_ob_table_locations where database_name=‘test’ and table_name=‘user_info’ and role=‘LEADER’ group by zone;
6、表是分区表,但where条件没有分区键,只有普通索引
【附件及日志】推荐使用OceanBase敏捷诊断工具obdiag收集诊断信息,详情参见链接(右键跳转查看):
【SOP系列 22 】——故障诊断第一步(自助诊断和诊断信息收集)
【备注】基于 LLM 和开源文档 RAG 的论坛小助手已开放测试,在发帖时输入 [@论坛小助手 ] 即可召唤小助手,欢迎试用!
论坛小助手
2025 年11 月 4 日 11:54
#3
根据您的描述,您遇到的问题是在OceanBase 4.3.5.4版本中,同一SQL_ID的SQL语句在不同Observer上的执行次数存在较大差异,同时观察到某observer CPU使用率高,业务反馈相关SQL耗时增加。考虑到您已经检查了QPS、obproxy分发情况、指定SQL ID的执行情况、primary zone配置和表分区leader分布情况,但仍未找到确切的原因。在这种情况下,我们可以使用obdiag工具来进一步收集和分析相关信息。
事务执行超时报错(尽管这里不一定是事务超时,但是针对执行时间长的SQL可以使用这个场景来进行更深层次的分析)
obdiag rca run --scene=transaction_execute_timeout
SQL性能问题
obdiag gather scene run --scene=observer.perf_sql --env "{db_connect='-h127.0.0.1 -P2881 -utest@test -p****** -Dtest', trace_id='[您的SQL的trace_id]'}"
请替换上述命令中的-h127.0.0.1 -P2881 -utest@test -p****** -Dtest为实际的数据库连接信息,并提供具体的SQL的trace_id(可以通过OBProxy查询SQL执行计划获得)。运行以上命令后,将收集到的相关日志压缩包提供给我们,以便于进一步分析问题所在。
另外,为了更准确地定位问题,请您提供以下信息:
可否提供SQL的具体内容?
该SQL在不同Observer上执行时的响应时间和执行计划是否有明显差异?
能否确认该SQL在查询时是否正确使用了索引?
高CPU使用的Observer节点的配置与其它节点相比是否有特殊之处(例如硬件资源、网络环境等)?
是否可以提供关于高CPU使用率的时间点信息,以便于我们能够更好地与收集到的数据进行对比分析?
以上信息将有助于我们更准确地了解并解决您遇到的问题。感谢您的配合!
附上敏捷诊断工具 obdiag 使用帮助链接