李努力
#1
环境描述:
OMS版本4.2.10_CE
OB版本4.3.5.2
OB架构:2-2-2
同步前,都提前在ob创建好了表结构了,每个表4个hash分区
问题描述:
使用OMS从mysql同步到ob集群(其中分了多个任务,每次基本都是2个任务同时跑,按库均分任务的,每个任务大概50-100个库):
首次同步了85467张表,大概400多个库,数据量大概几十亿条,效率还可以;
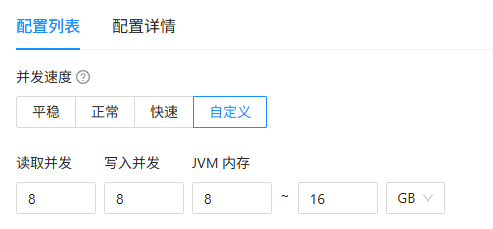
第二次需要同步16477张表,大概10多亿的数据,前50个表数据量小,同步较快,后面的表特别特别慢,任务配置参数:
在ob端通过show processlist查看,都是查询系统表:information_schema.STATISTICS、information_schema.COLUMNS的sql比较慢,这些系统表是每同步一张表都会查一次吗?
日志如下:
metrics.log (5.4 MB)
各位老师帮忙分析下慢在了哪里,以后还有不少类似的同步任务。
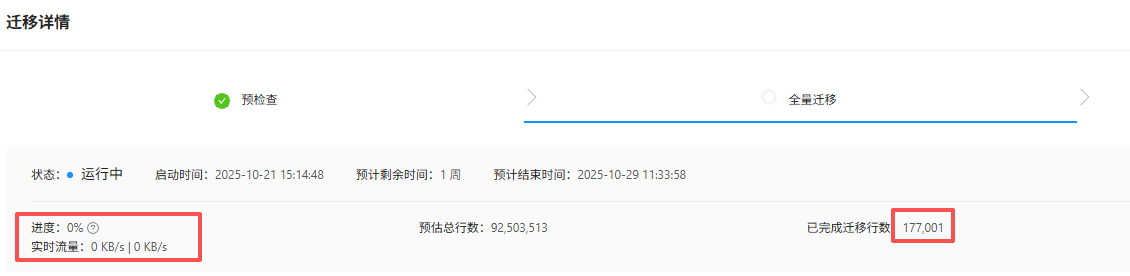
下面是与metrics.log日志对应的任务的截图,是同步了三天的结果:
1 个赞
淇铭
#4
确实是需要查询information_schema.STATISTICS、information_schema.COLUMNS 如果这个表的信息非常大的会 查询会慢的
1 个赞
李努力
#5
那通过metrics.log能看出,需要哪里优化吗?还是说没有什么好的办法,表太多了就会这样
淇铭
#7
“dataflow”:{“slice_queue”:0} 从这里看这个值 是0 可以修改一下这个值
- slice_queue > 0 瓶颈不在这里,slice_queue=0 分片慢,增加source.sliceBatchSize每个分片的记录数,多表场景也可以增加source.sliceWorkerNum分片工作线程source.sliceBatchSize对于大表一般10000基本就可以满足了,太大会消耗内存很多
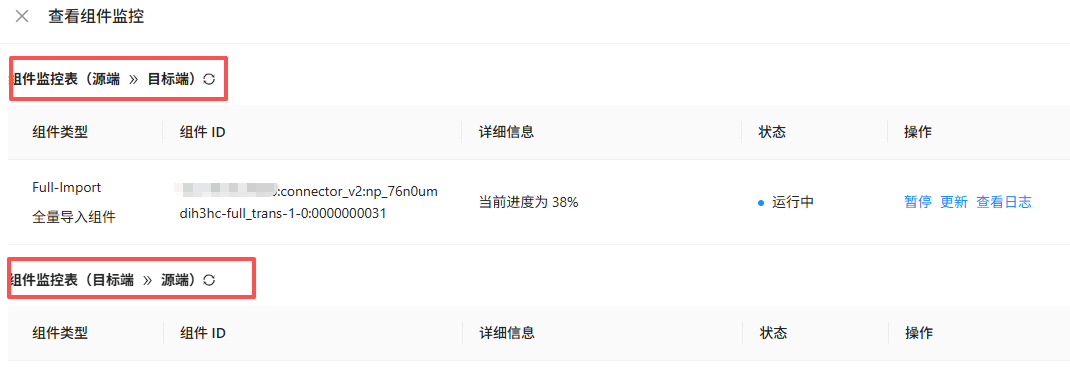
你组件监控截图看一下
源端和目标端是在同一个机房么?
2 个赞
淇铭
#8
对于这两个表 没有优化的手段了 表多的情况下 就是会慢
李努力
#9
增加了source.sliceWorkerNum这个了 ,改为10000了,目前还没看到效果
是在同一机房
组件监控,没东西,这咋回事呢
李努力
#10
sliceWorkerNum这个也增加了,增加到了16,source.sliceBatchSize这个改为了10000,但是没啥效果,基本上不同步了太慢了
周雄
#12
发一下组件的日志看看,/home/ds/run/组件id/logs/connector.log、error.log
源端是不是有很多分区表
李努力
#13
周雄
#14
当前步骤是全量迁移吧,组件监控怎么是 目标端->源端,这个任务没搞错吧。
现在全量组件状态是运行中还是异常,oms容器内部 ps -ef | grep 组件id 看一下
李努力
#16
任务没错,只进行了全量同步没有增量,但是组件监控是空的。全量组件运行正常
周雄
#19
这个是正常的,正向组件在 源端->目标端;反向组件在目标端->源端。
全量组件运行中,rps有没有在走。sink.enablePartitionBucket=false 改一下这个配置试一下
1 个赞
李努力
#21
刚刚手动收集了下,oceanbase系统库下的系统表的统计信息,主要集中在:
oceanbase.__all_database
oceanbase.__all_table
oceanbase.__all_column
这三个表,效果较明显
未收集前,rps基本不动,三天同步了3000条数据,很慢很慢,应该跟统计信息有关。
收集后,有明显效果
1 个赞