Giant
#1
【 使用环境 】生产环境 or 测试环境
【 OB or 其他组件 】
【 使用版本 】
【问题描述】清晰明确描述问题
【复现路径】问题出现前后相关操作
【附件及日志】推荐使用OceanBase敏捷诊断工具obdiag收集诊断信息,详情参见链接(右键跳转查看):
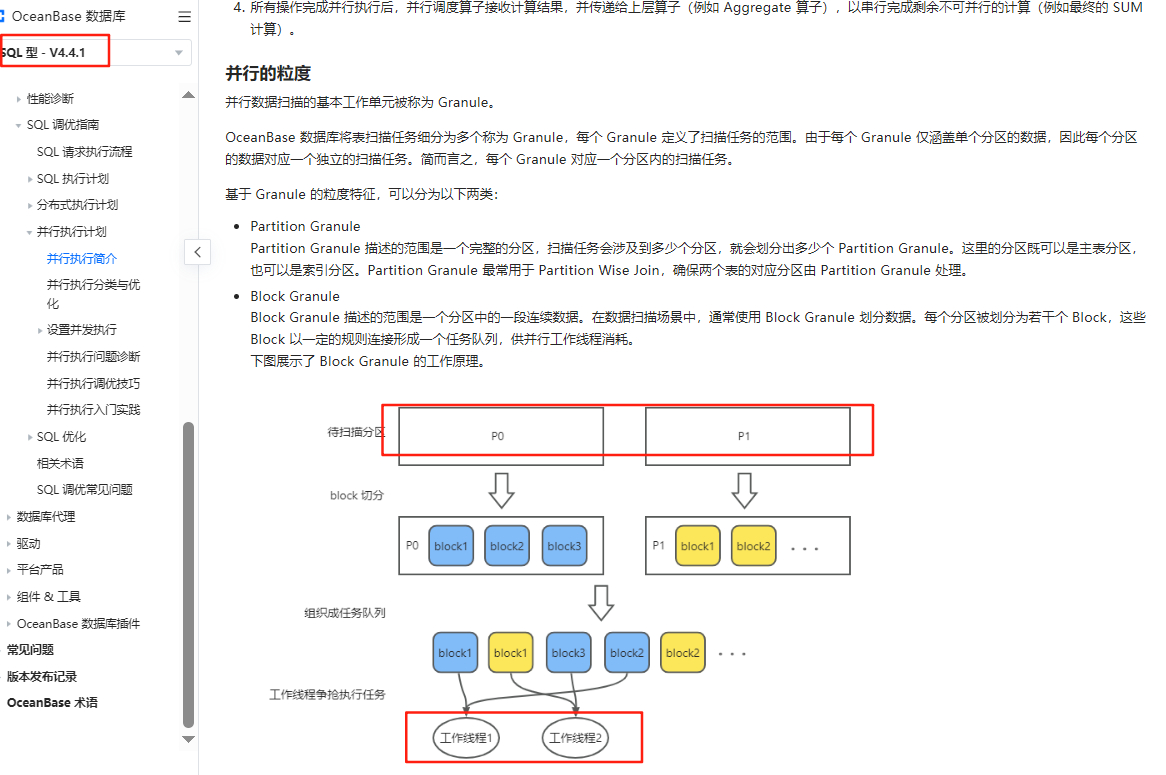
疑问1: P0 p1分区 是分布在两个 observer上的一个分区表 dop=2的情况下 。 这个任务队列 是在各个observer上创建呢 ? 还是在 怎么创建 这个任务队列 ?
疑问2: 线程应该是每个observer实例独享的吧。 能否跨 observer处理队列的数据呢 ??
2 个赞
Giant
#4
dop =3 3个observer,每个observer 1个线程的话, 任务队列是多少个 呢 ??

一个任务队列仅仅存在一个observer上吗 ??
1 个赞
淇铭
#5
Giant
#6
看了文档我的理解。
每次并行线程都会想 每个Observer的 并行线程池申请线程。如果Observer没有足够的线程就会排队。
也就是每个线程都是隶属于自己的observer或observer线程池。
每个observer上的worker线程只能处理 自己归属的observer上的分区数据?? 对不对呢。
从而确定根据block形成的队列 每个observer 都有1个??? 对不对
1 个赞
Giant
#8
dop=3 3个 observer, 表分区数 6个 。 有几个任务队列?? 是不是每个observer上 一个任务队列?
淇铭
#10
为了达到最优性能,所有工作线程分到的工作任务应该尽量相等。
SQL 使用 Block Granule 划分任务的时候,工作任务会动态地分配到工作线程之间。这样可以最小化工作负载不均衡问题,即一些工作线程的工作量不会明显超过其它工作线程。
SQL 使用 Partition Granule 划分任务时,可以通过让任务数是工作线程数的整数倍来优化性能。这适用于 Partition Wise Join 和并行 DML 场景。
举个例子,假设一个表有 16 个分区,每个分区的数据量差不多。你可以使用 16 工作线程(DOP 等于 16)以大约十六分之一的时间完成工作,你也可以使用五个工作线程以五分之一的时间完成工作,或使用两个线程以一半的时间完成工作。
但是,如果你使用 15 个线程来处理 16 个分区,则第一个线程完成一个分区的工作后,就开始处理第 16 个分区。而其他线程完成工作后,它们变为空闲状态。当每个分区的数据量差不多时,这种配置会导致性能不优;当每个分区的数据量有所差异时,实际性能则会因情况而异。
类似地,假设你使用 6 个线程来处理 16 个分区,每个分区的数据量差不多。在这种情况下,每个线程在完成其第一个分区后,会处理第二个分区,但只有四个线程会处理第三个分区,而其他两个线程会保持空闲。
一般来说,你不能假设在给定数量的分区(N)和给定数量的工作线程(P)上执行并行操作所花费的时间等于 N 除以 P。这个公式没有考虑到一些线程可能需要等待其他线程完成最后的分区。但是,通过选择适当的 DOP,你可以最小化工作负载不均衡问题并优化性能。