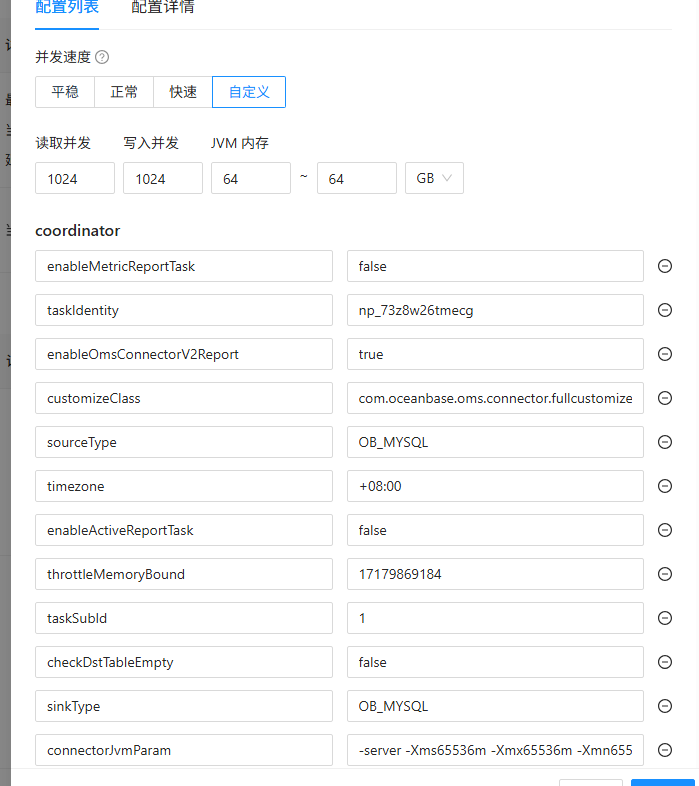
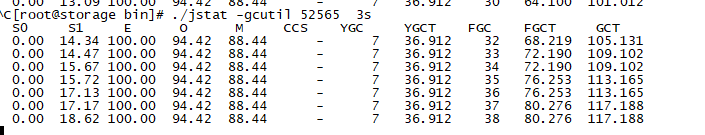rocH
#1
【 使用环境 】生产环境
【 OB or 其他组件 】OB、OMS、obProxy
【 使用版本 】OB: 4.3.4.1. OMS: 4.2.10 obProxy: 4.3.4.0-1
【问题描述】
业务背景:
生产环境需要在其他机房同步一个备库。并且这个备库需要开放给数据分析部门使用,需要在备库中写入数据分析表。由于备租户只能读无法写。
因此我们需要通过oms迁移一个全能租户。
机器配置介绍:
原集群: 1-1-1。 机器都是76核,1T内存的高性能机器
新集群: 单机集群。 56核,256G内存
obproxy:8核16G内存。 单独为了同步备库分别给原集群和新集群在各自内网中都各建了一个代理。
OMS: 64核128G内存;部署在原集群的内网中
原集群和新集群属于不同机房,但是有光纤直连。最大网速10Gbps。并且新旧集群机器和oms机器之间网速都使用iperf3 工具测试过。10Gbps可能不太稳定,但是8Gbps是稳的
全量迁移任务配置:

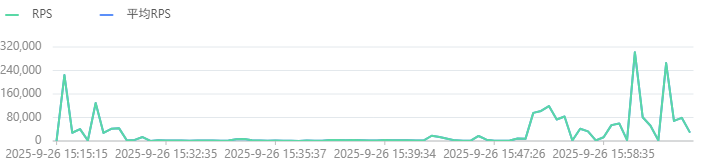
同步性能:
如图所示,同步性能及其不稳定。
根据调优文档 执行 ./connector_utils.sh diagnose命令。
显示
[Scene] JdbcWriteSlowScene
commit/batch=75517.00ms, execute/record=3.00ms, 建议查看该时间是否合理
日志中经常出现的异常:
com.alibaba.druid.pool.GetConnectionTimeoutException: wait millis 12000, active 814, maxActive 1089, creating 1, createElapseMillis 64
求助该如何调整oms服务
开那么多并发干啥?内存还挺小,有没有宽表?多分区表?大字段表?
淇铭
#5
./connector_utils.sh metrics 查看一下 看看瓶颈在哪里
1 个赞
rocH
#6
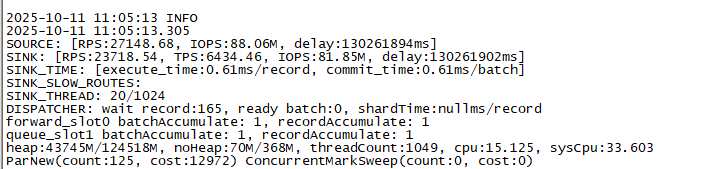
2025-09-26 18:00:25 INFO
2025-09-26 17:57:20.597
SOURCE: [RPS:3876.18, IOPS:nullM]
DATAFLOW: [slice:145.7ms, query:0.93ms, sliceQueue:143]
SINK: [RPS:39014.88, TPS:129.88, IOPS:40.324M]
SINK_TIME: [execute_time:6.54ms/record, commit_time:2852.77ms/batch]
SINK_THREAD: 1024/1024
DISPATCHER: wait record:null, ready batch:191, shardTime:nullms/record
queue_slot1 batchAccumulate: 512, recordAccumulate: null
heap:52632M/58982M, noHeap:61M/0M, threadCount:3041, cpu:37.414, sysCpu:44.565
ParNew(count:32, cost:18997) ConcurrentMarkSweep(count:947, cost:5586858)
连接并发开的太多了吧,正常同步很少开64以上,一般32个并发已经很高,连接数越多协调成本越高。建议是基于16、32个并发先观测瓶颈点是网络,还是源端、目标端负载(尤其CPU),不一定是OMS的问题
rocH
#8
ConcurrentMarkSweep(count:947, cost:5586858)
看这个指标感觉是fullgc过于频繁
查找到对应 全量任务的java进程。
ps -ef| grep ds/run
查看gc状况
./jstat -gcutil 52565 3s
如上图,一直在fullgc
rocH
#11
确认了是内存参数设置问题,之前设置了 64GB~64GB。 经常fullgc。
导致同步速率呈现这种波浪形。谷底就是因为在fullgc导致进程阻塞。
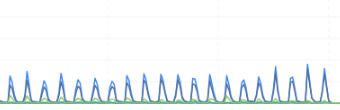
把内存参数调整为 32GB~64GB就没有这个问题了。
目前全量同步已经完成。但是增量同步却出现因 源端解析log过慢导致同步比较慢的情况。
我执行 ./connector_utils.sh diagnose 进行检测。
提示:
StoreParserSlowScene
可能存在源端投递数据瓶颈
当前调整的并发度为1024。
继续往上加并发度也没有效果。加到4096反而效率降低到 1024的 10%
机器状况显示, oms的cpu使用率才20%不到。
如何才能提高源端解析日志的速度
并发度1024,jvm内存参数64GB~128GB. 执行 ./connector_utils.sh metrics显示如下