【 使用环境 】生产环境
【 OB or 其他组件 】 oceanbase
【 使用版本 】
【问题描述】
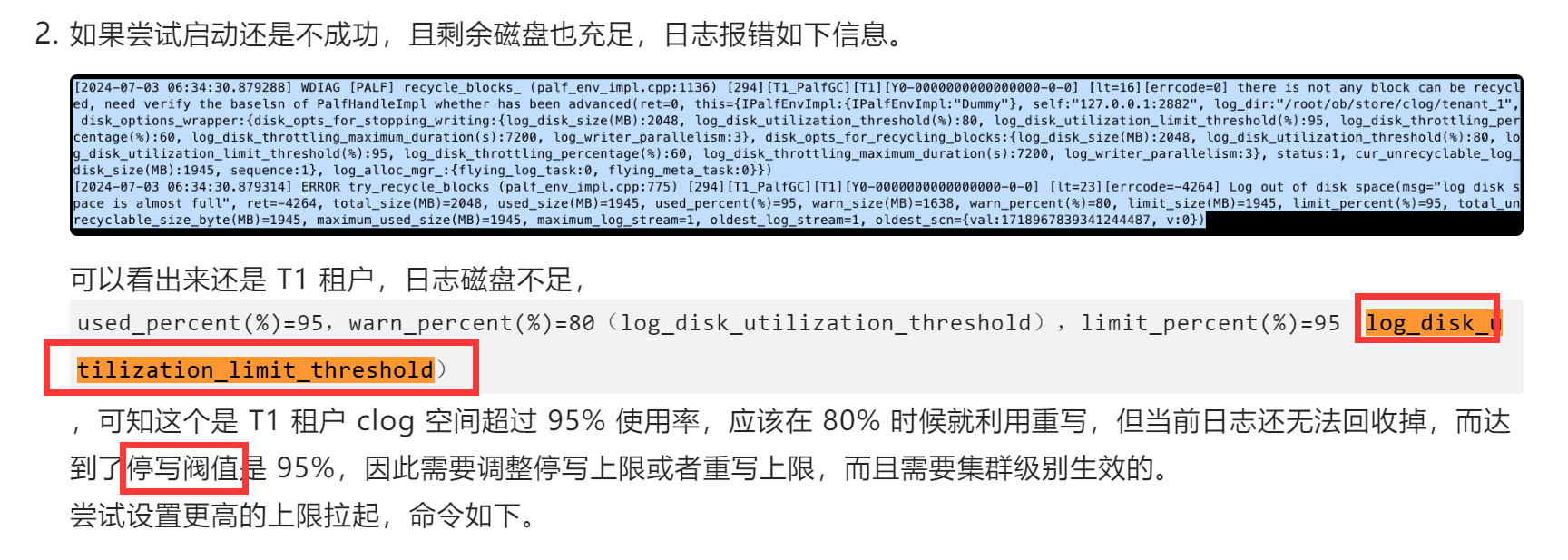
ocp部署的,通过杀进程,在安装目录上手动启动observer进程,登录sys租户登录一直处于Server is initializing状态,启动顺序是3个节点逐一杀进程后,逐一启动。
ob日志一直相似的滚动。详细见附件
observer.log.zip (17.5 MB)
[2025-09-23 16:29:16.418625] WDIAG [COORDINATOR] refresh (election_priority_impl.cpp:268) [33731][T1001_L0_G2][T1001][YF5A2C0A80AA3-00063F72CBE4B780-0-0] [lt=10][errcode=-4018] refresh priority failed(ret=-4018, ret=“OB_ENTRY_NOT_EXIST”, MTL_ID()=1001, ls_id={id:1}, *this={priority:{is_valid:false, is_observer_stopped:false, is_server_stopped:false, is_zone_stopped:false, fatal_failures:[], is_primary_region:false, serious_failures:[{type:SCHEMA NOT REFRESHED, module:SCHEMA, info:schema not refreshed, level:SERIOUS}], is_in_blacklist:false, in_blacklist_reason:, scn:{val:0, v:0}, is_manual_leader:false, zone_priority:9223372036854775807}})
[2025-09-23 16:29:16.418729] WDIAG [COORDINATOR] compare_with (election_priority_impl.cpp:212) [33731][T1001_L0_G2][T1001][YF5A2C0A80AA3-00063F72CBE4B780-0-0] [lt=52][errcode=0] compare between invalid priority
[2025-09-23 16:29:16.423827] WDIAG [SQL] do_close_plan (ob_result_set.cpp:850) [33372][T1_FreInfoReloa][T1][YF5A2C0A80AA3-00063F72CEB45B11-0-0] [lt=0][errcode=-4006] exec result is null(ret=-4006)
[2025-09-23 16:29:16.423836] WDIAG [SQL] do_close (ob_result_set.cpp:947) [33372][T1_FreInfoReloa][T1][YF5A2C0A80AA3-00063F72CEB45B11-0-0] [lt=6][errcode=0] fail close main query(ret=0, do_close_plan_ret=-4006)
[2025-09-23 16:29:16.423870] WDIAG [SQL.PC] common_free (ob_lib_cache_object_manager.cpp:141) [33372][T1_FreInfoReloa][T1][YF5A2C0A80AA3-00063F72CEB45B11-0-0] [lt=0][errcode=0] set logical del time(cache_obj->get_logical_del_time()=4945347077236, cache_obj->added_lc()=false, cache_obj->get_object_id()=42004, cache_obj->get_tenant_id()=1, lbt()=“0x7bb5945 0xfb02508 0x74dc8b4 0x78d9087 0x77e5bc9 0xef4b6f7 0x77ded10 0x77d1d9a 0x77d1caf 0x77c2426 0x7d9b153 0x188a9349 0x7841d7a 0x783b973 0x1f5af0a8 0x1f5ad20e 0x7f55fa64bea5 0x7f55fa374b0d”)
[2025-09-23 16:29:16.428216] WDIAG [SHARE.SCHEMA] get_tenant_schema_guard (ob_multi_version_schema_service.cpp:1176) [33675][T1001_ReqMemEvi][T1001][Y0-0000000000000000-0-0] [lt=6][errcode=-5627] get tenant schema store fail, maybe local schema is old(ret=-5627, tenant_id=1001)
[2025-09-23 16:29:16.428232] WDIAG get_global_sys_variable (ob_basic_session_info.cpp:1057) [33675][T1001_ReqMemEvi][T1001][Y0-0000000000000000-0-0] [lt=12][errcode=-4029] fail get schema guard(ret=-4029)