ob:社区版 4.3.5.3
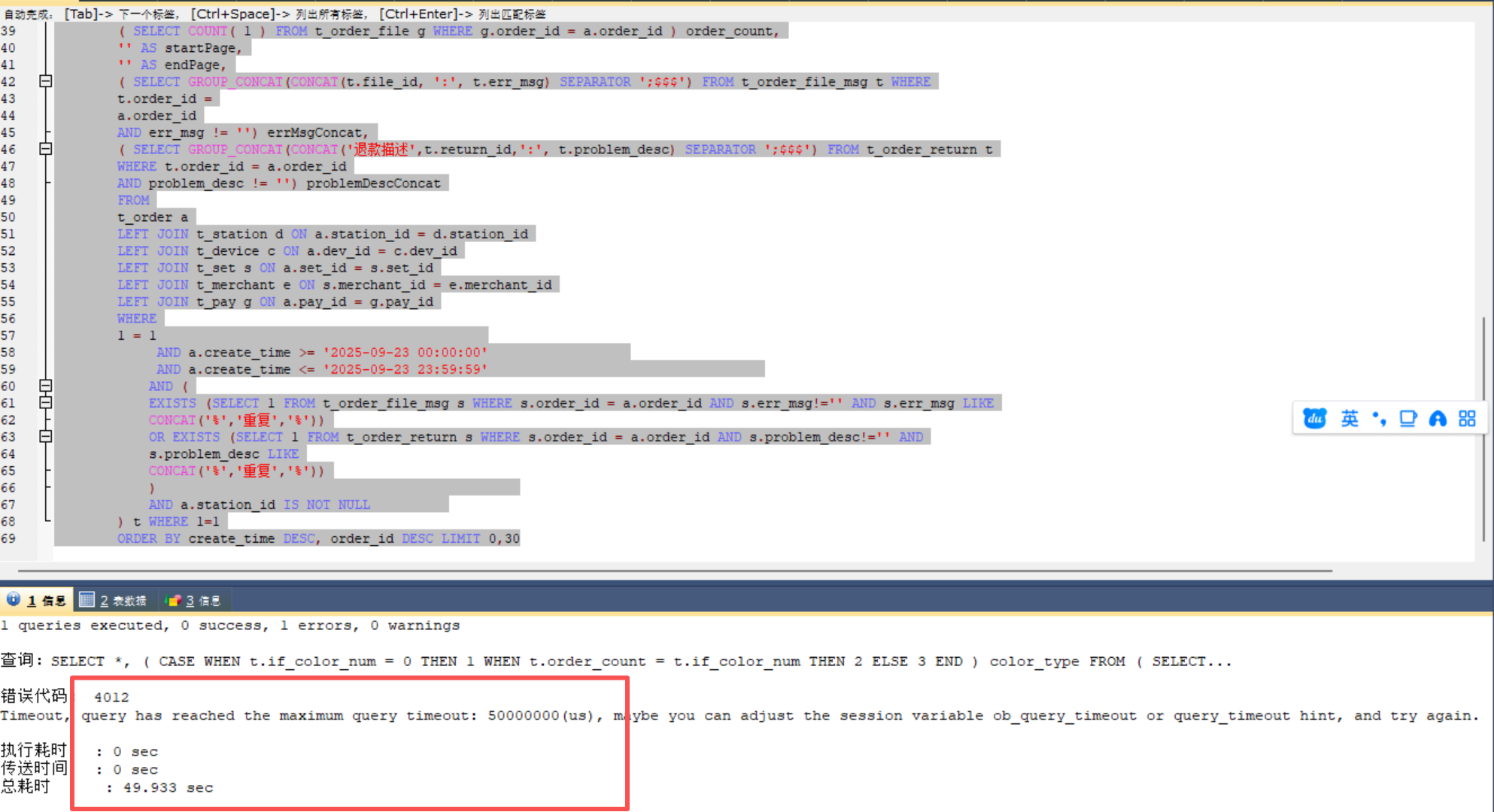
这个sql是有点复杂,其实这个时间点,满足条件的数据只有7条,按我们常规的理解,对这7条数据做排序,几乎不需要时间吧,可是居然会超时。
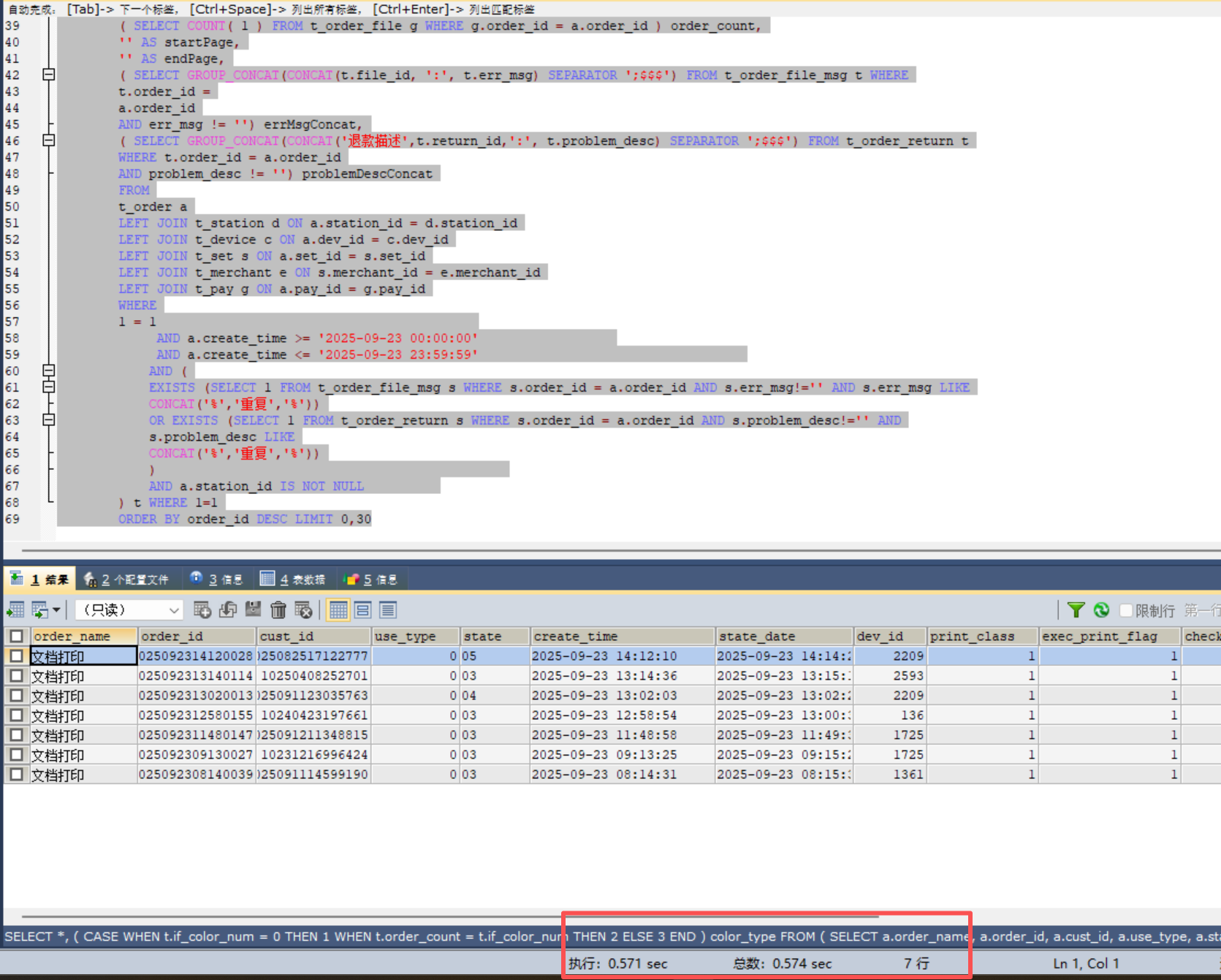
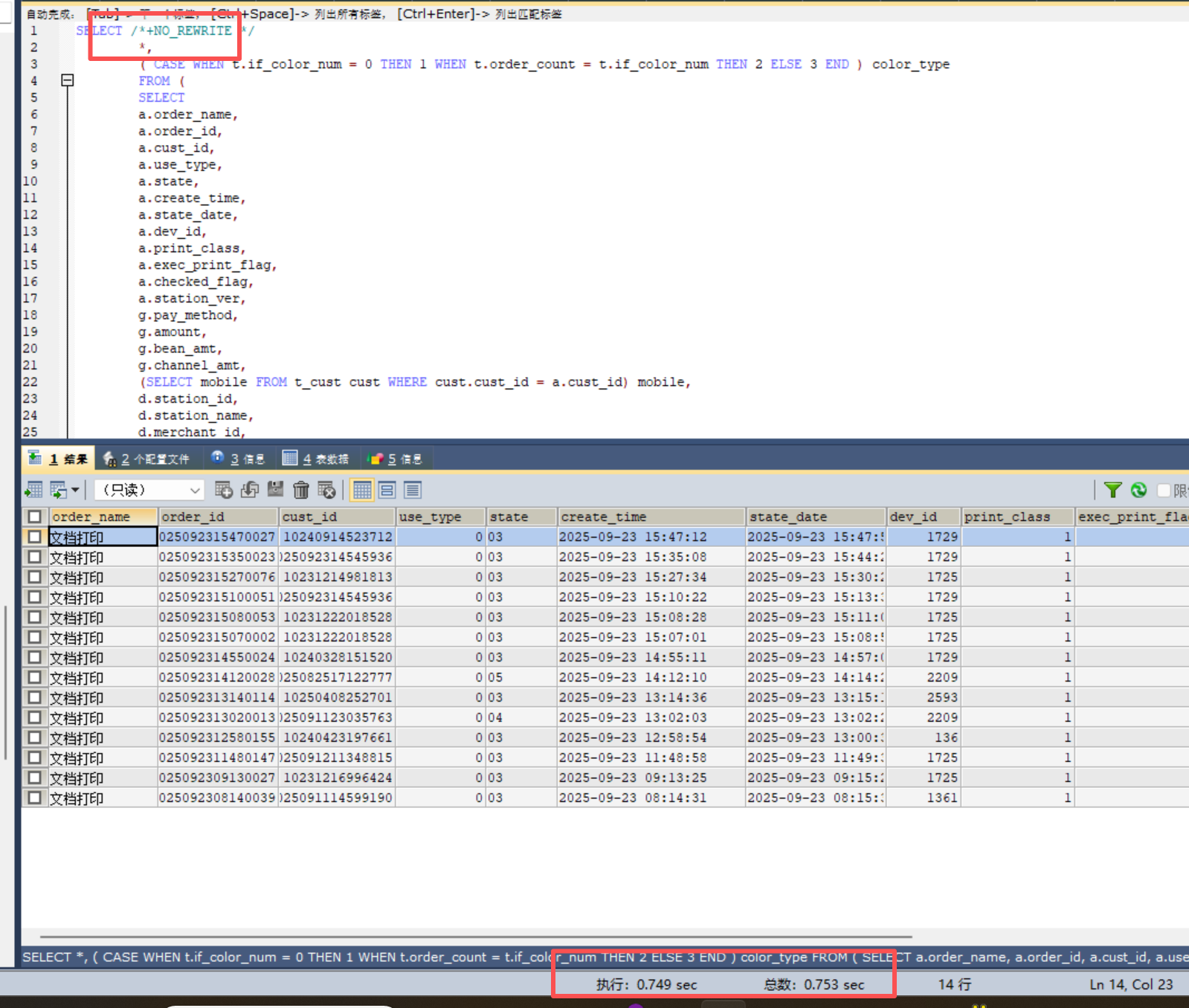
只执行内查询:
1秒不到,属于正常。
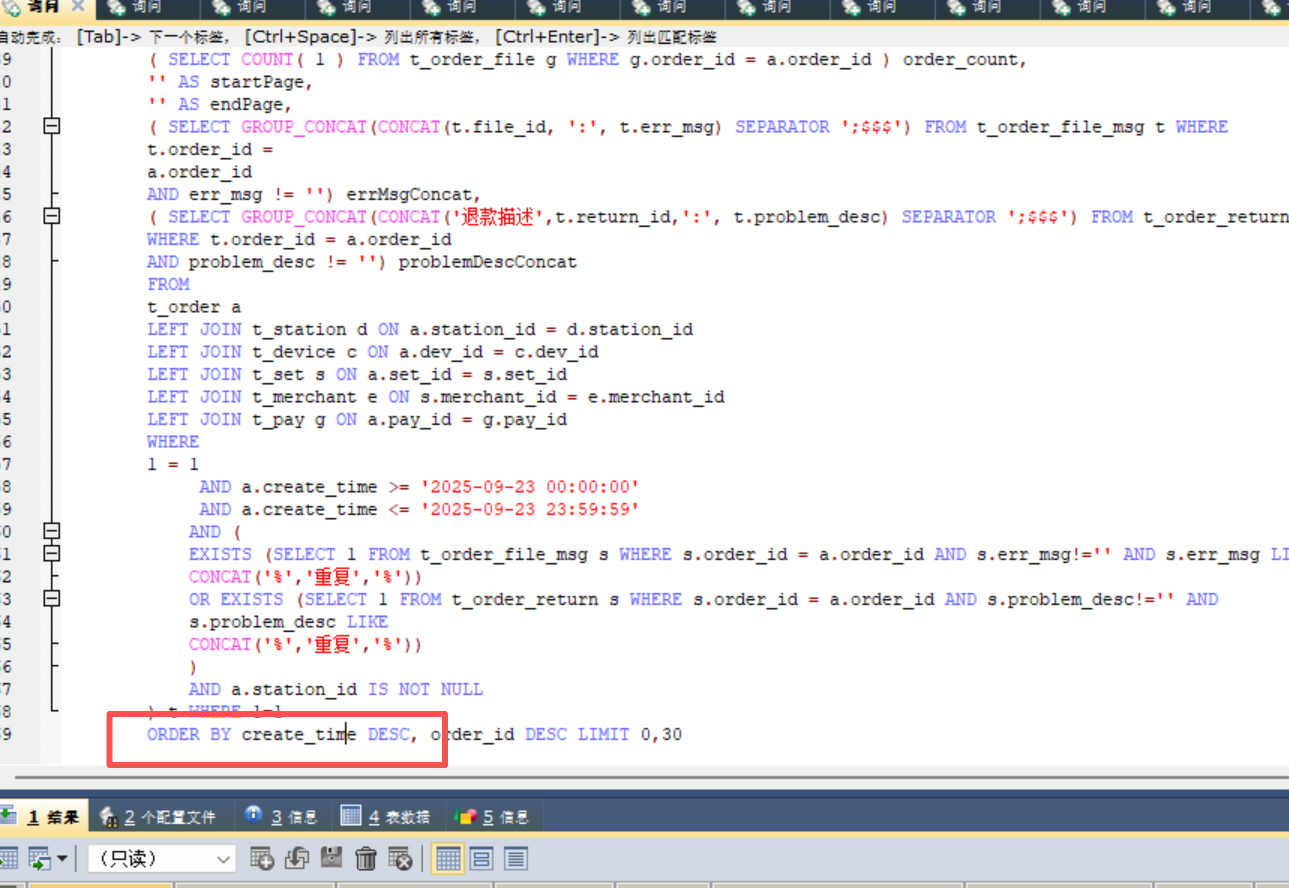
然后更想不到的是,把原始sql order by 里面的create_time去掉,也很快
但是只要把create_time加上去,必现超时。
不得不让人对ob的查询引擎感到疑惑啊,这种现象mysql上从来没遇到过。
附上sql文本:
ob-query-timeout-sql.txt (2.9 KB)
2 个赞
辞霜
#3
建表sql也麻烦提供一份
使用obdiag执行sql性能分析一下
SQL性能问题, 此处env中的trace_id对应gv$ob_sql_audit的trace_id
obdiag gather scene run --scene=observer.perf_sql --env “{db_connect=’-hxx -Pxx -uxx -pxx -Dxx’, trace_id=‘xx’}”
1 个赞
来轩
#8
加个 /+NO_REWRITE/ 试下看下执行计划
1 个赞
淇铭
#9
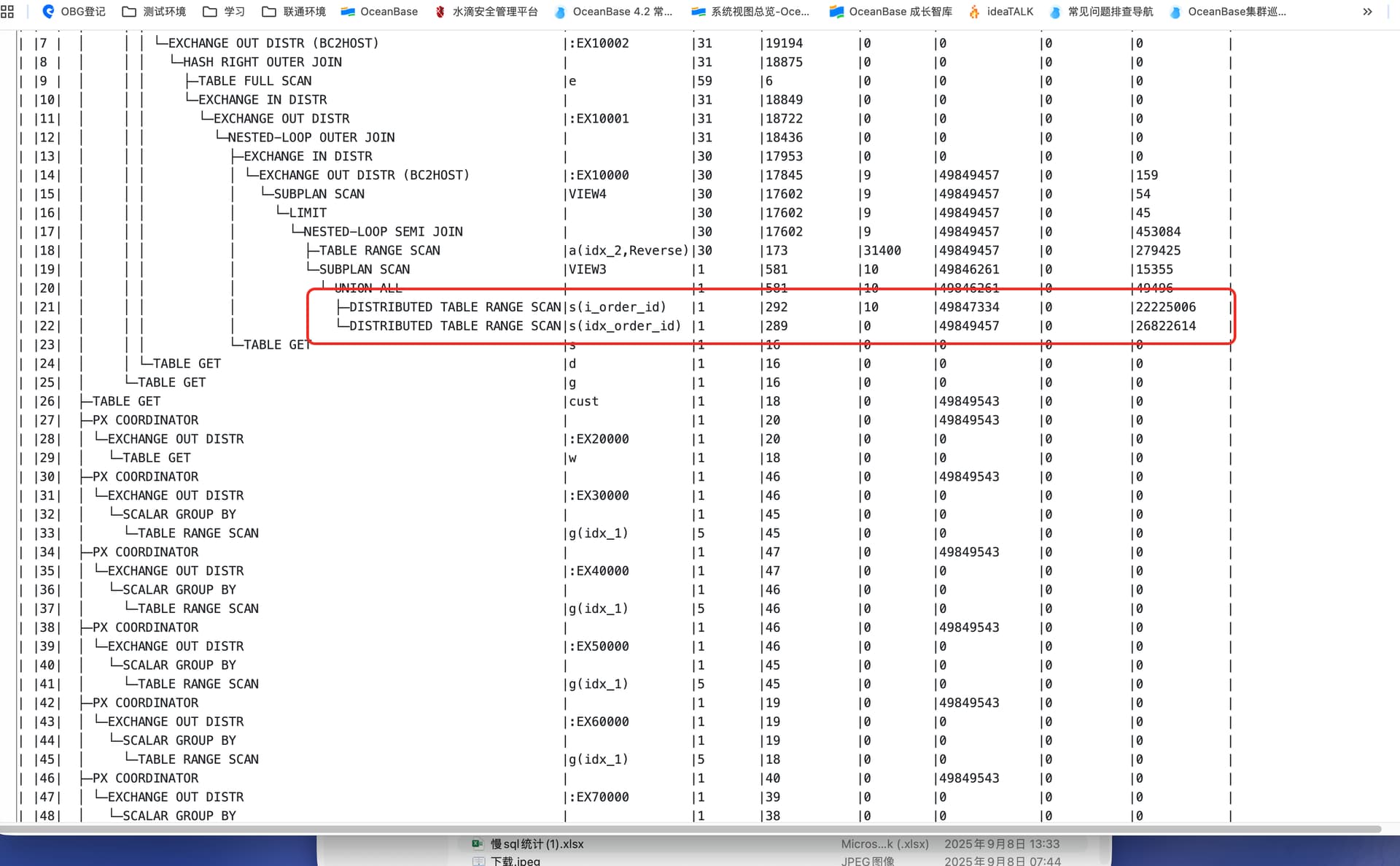
/+NO_USE_DAS(@“SEL$3” “s”@“SEL$3”) NO_USE_DAS(@“SEL$4” “s”@“SEL$4”)/ 语句中加上hint 在提供一下执行计划 explain extended
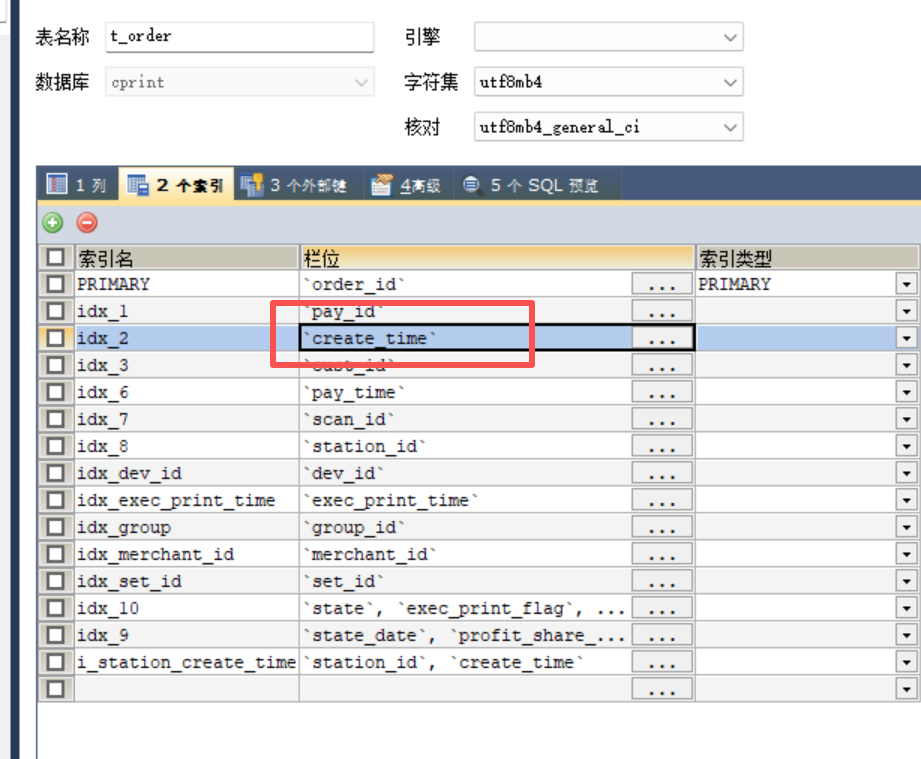
有索引。
但是有没有索引,我都想不明白,内部sql查出来只有7行记录,然后对这7行做排序,有没有索引有影响吗?
加了这个,稳定在1秒一下。
这个查询引擎的运行逻辑真的让人看不懂了,感觉以前mysql学的理论用不上了,不知道该怎么优化sql
来轩
#14
OB 跟MYSQL的优化器不太一样,多了查询改写的步骤,大部分情况查询改写会往好的方向进行改写,但是也有改写之后很差的情况
加了这个hint,执行时间在也1秒一下。
explain_extended.txt (122.9 KB)
淇铭
#16
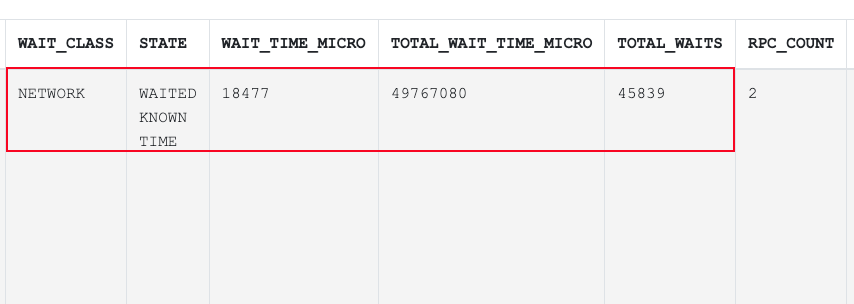
主要是das本地或者远程拉取的时候等待的时间很长 加了hint以后不走das 应该就可以了 目前可以先饶过去 后期会逐渐优化的
1 个赞