

RAG(Retrieval-augmented generation)检索增强生成给大模型提供了已有的特定领域知识,但稍显不足的是 RAG 的文档是静态的,当你有了新想法,无法实时更新到文档,当然可以事后更新,但是在时效性上已经有了延迟,就好像在购物网站上你搜索了某样东西,第二天才推给相似的推荐,体验不够好。
我今天想吃火锅、明天想吃烧烤,或者今天很冷、今天下雨了,这些偏好和事实在你和大模型对话时肯定不想一遍一遍的重复,但是在当前的对话机制下,你可能不得不这样做,因为当你新开一个对话,所有过往的信息都没了,大模型面对的是一个全新的你。
OceanBase MCP Server 新增 Memory Tools,与 AI 的对话过程中你的喜好将被记住,并在后续任务处理过程中优先检索 Memory 以获得个性化体验,打造更懂你的 AI 助理。
一起开始探索之旅吧!
前提条件
准备 OceanBase 数据库
记忆功能使用向量存储,OceanBase 的版本需要支持向量,建议使用 v4.3.5.3+ 的版本,下面的命令可以直接启动一个 4.3.5.3 的 OceanBase
sudo docker run -p 2881:2881 --name obvector -e MODE=mini -d oceanbase/oceanbase-ce:4.3.5.3-103000092025080818
或者免费试用云上数据库
对于其他支持向量的 OceanBase 版本,需要手动配置 ob_vector_memory_limit_percentage
安装 OceanBase MCP Server
启用 Memory 能力需要更多的依赖包以及 Embedding 模型,可以通过以下命令快速安装
# Python 版本支持 3.10~3.12
pip install oceanbase-mcp
pip install oceanbase-mcp[memory] --extra-index-url https://download.pytorch.org/whl/cpu
在任意目录下创建 .env 文件,配置变量信息
OB_HOST=127.0.0.1
OB_PORT=2881
OB_USER=
OB_PASSWORD=
OB_DATABASE=
ENABLE_MEMORY=1 # default 0 disabled, set 1 to enable
EMBEDDING_MODEL_NAME=BAAI/bge-small-en-v1.5 # default BAAI/bge-small-en-v1.5, You can set BAAI/bge-m3 or other models to get better experience.
EMBEDDING_MODEL_PROVIDER=huggingface
OB_HOST: 数据库的连接地址
OB_PORT: 端口
OB_USER: 用户名
OB_PASSWORD: 密码
OB_DATABASE: 连接的数据库
其他的配置项可以保持不动
配置方式
启动
在配置 env 文件的目录下使用 uv 的方式启动,uv 的安装及使用方式,可以参考 GitHub 文档
uv run oceanbase_mcp_server --transport sse --host 0.0.0.0 --port 8000
在客户端中配置
可以在任何支持 MCP 的客户端中配置,这里使用 CherryStudio 作为示例
自定义一个名称,类型选择“服务器发送事件(sse)”,配置 URL,URL 格式:http://ip:port/sse,保存
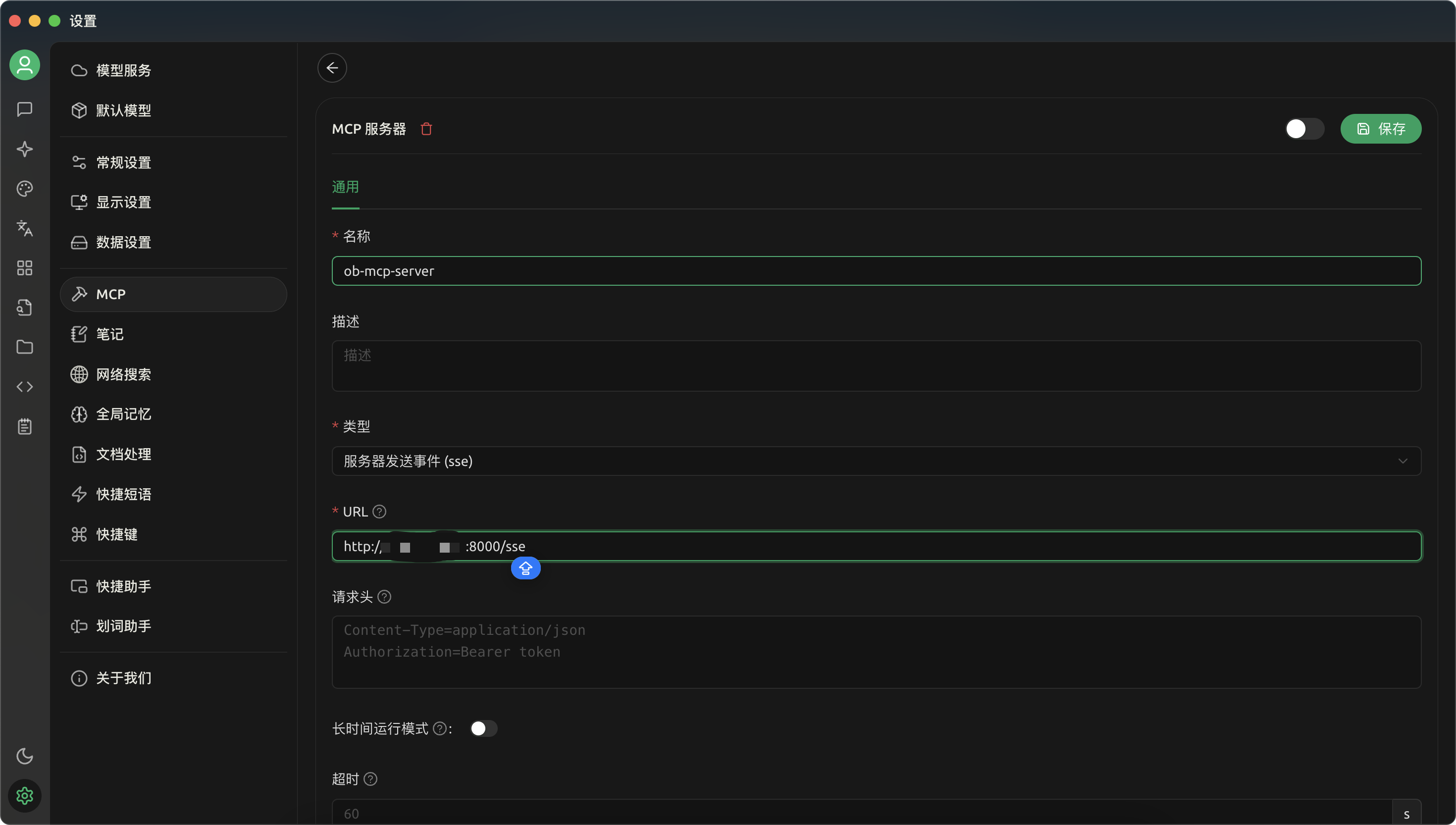
在聊天页面配置
点击锤子图标,选择刚添加的 MCP 服务 ob-mcp-server
开始对话
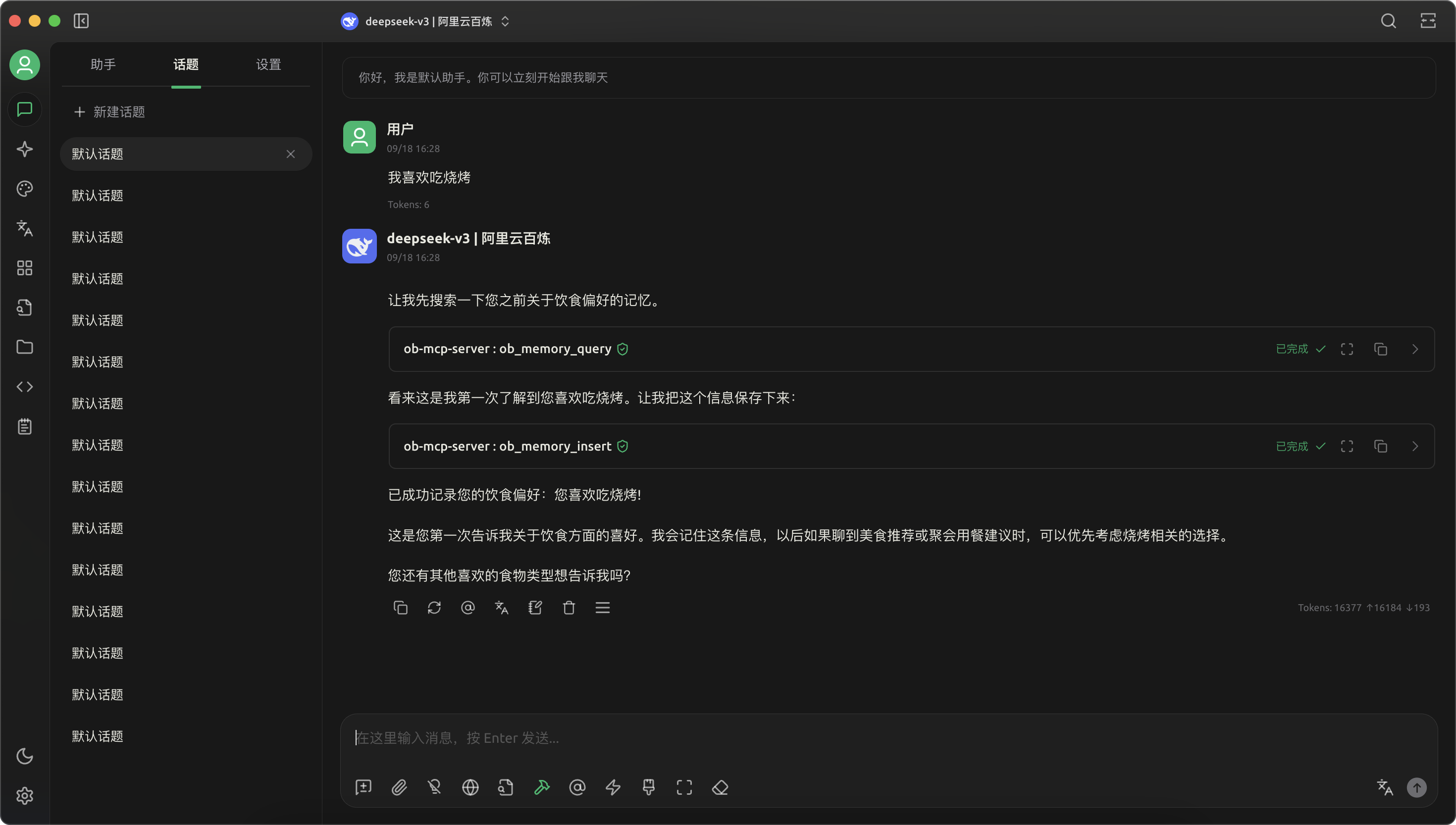
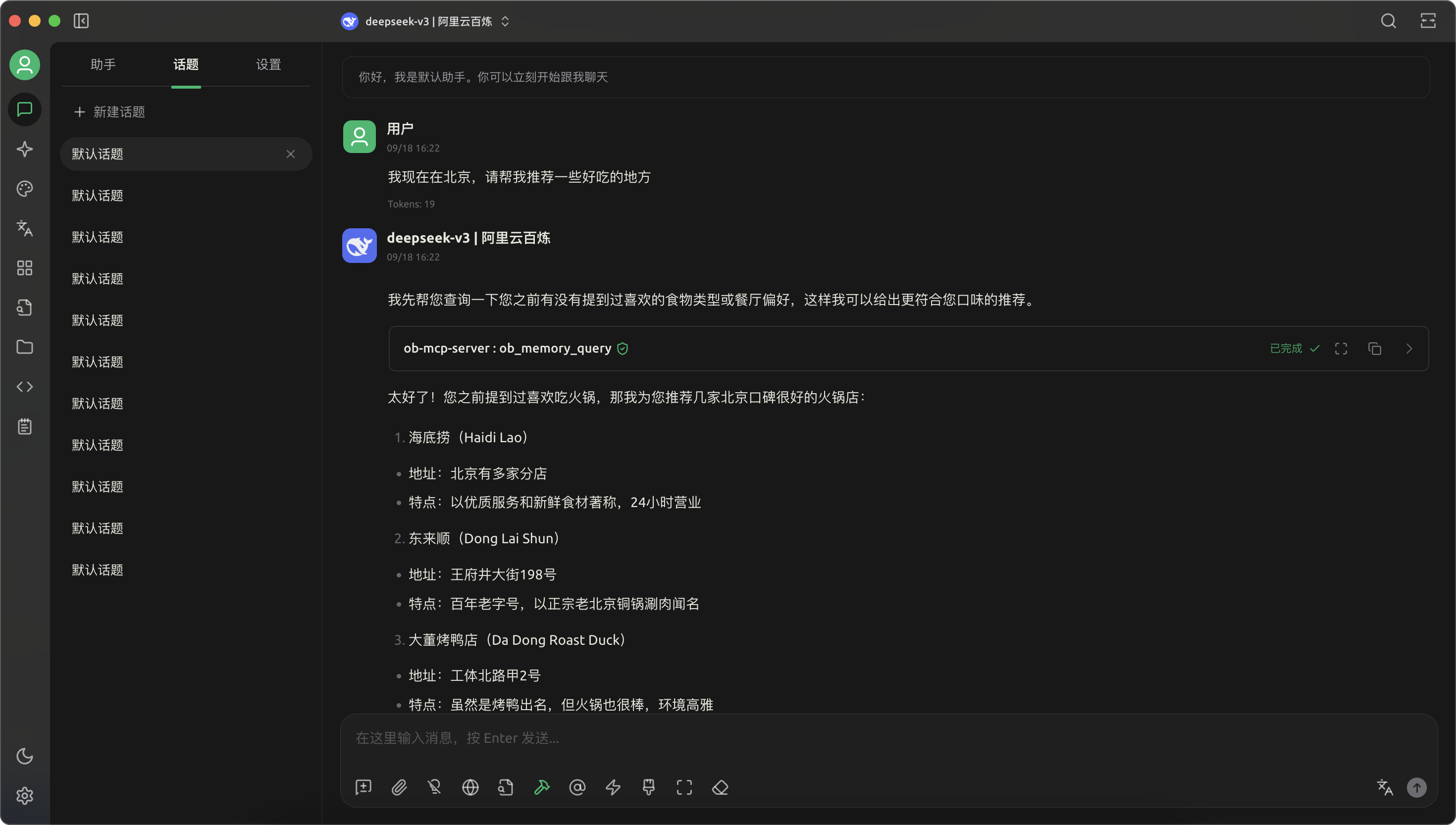
- 告诉大模型我喜欢吃烧烤,大模型自动调用了 OceanBase MCP Server 的工具,帮我记录了这个喜好
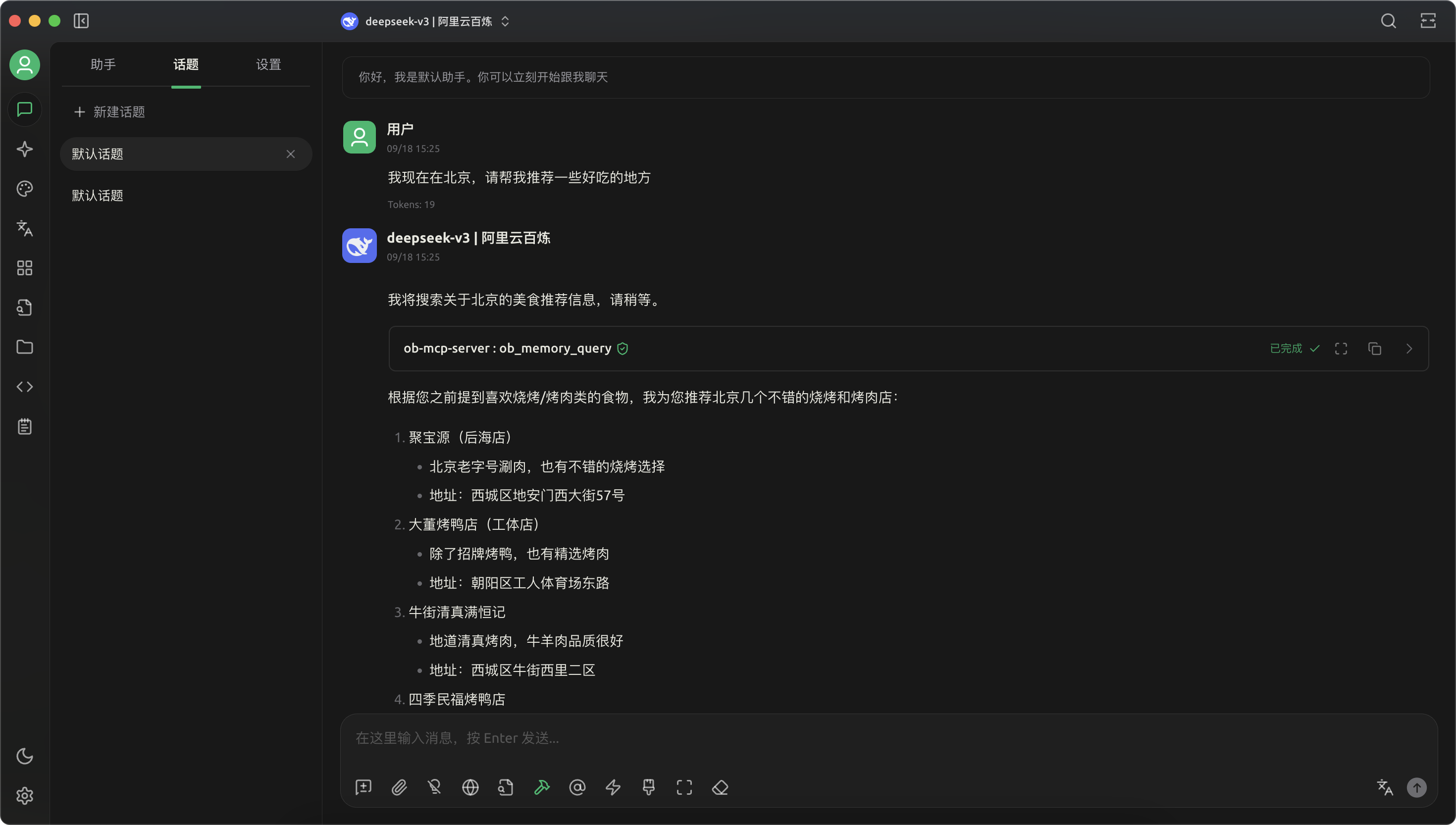
- 在一个新开的对话窗口,请大模型推荐一些好吃的地方,它自动在记忆中搜索到我喜欢吃烧烤,给我推荐了吃烧烤的地方
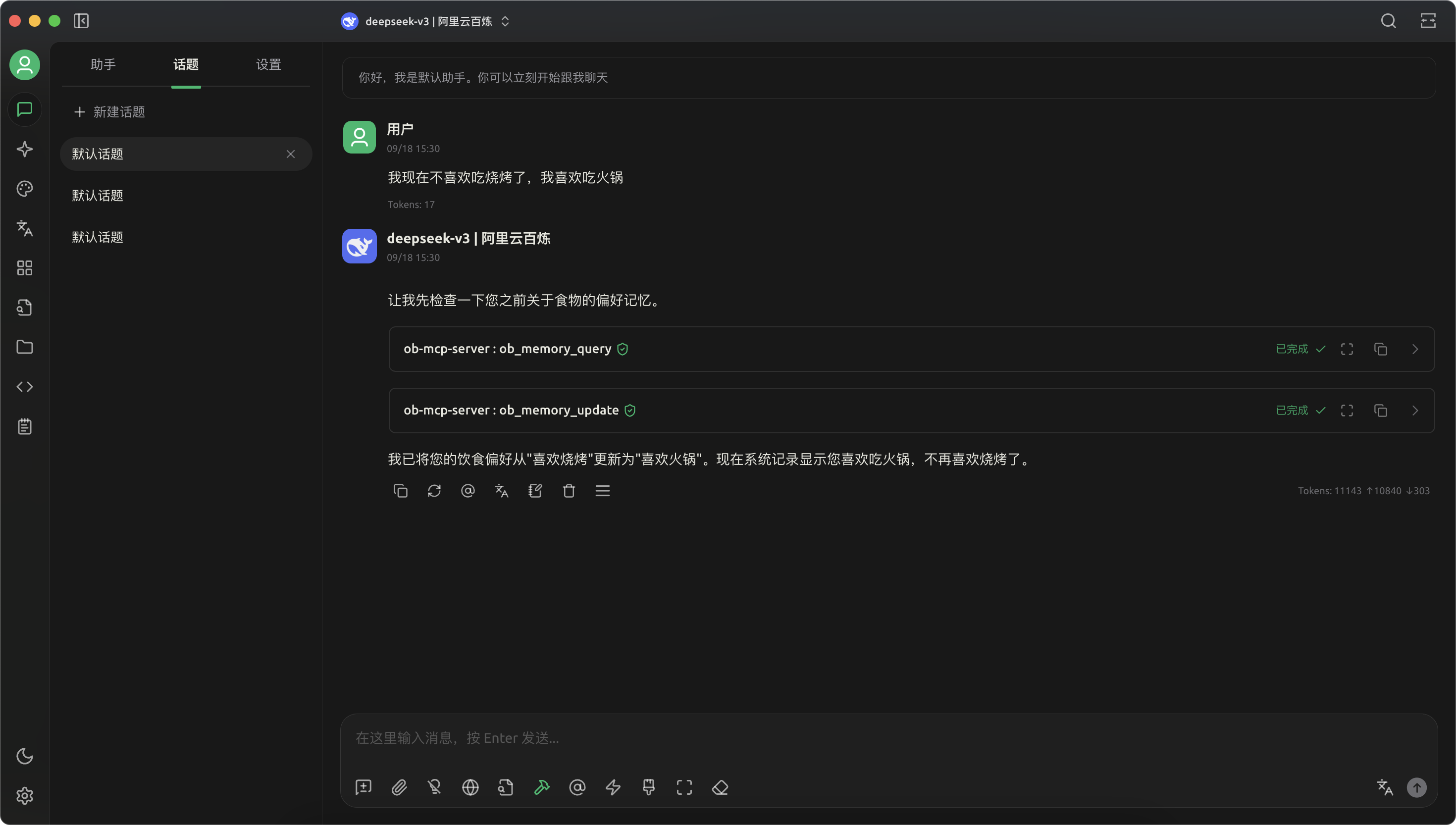
- 告诉它我现在不喜欢吃烧烤了,喜欢吃火锅,记忆自动更新为“我喜欢吃火锅”
- 重新开一个窗口,请大模型推荐好吃的地方,现在它给我推荐的都是一些吃火锅地方
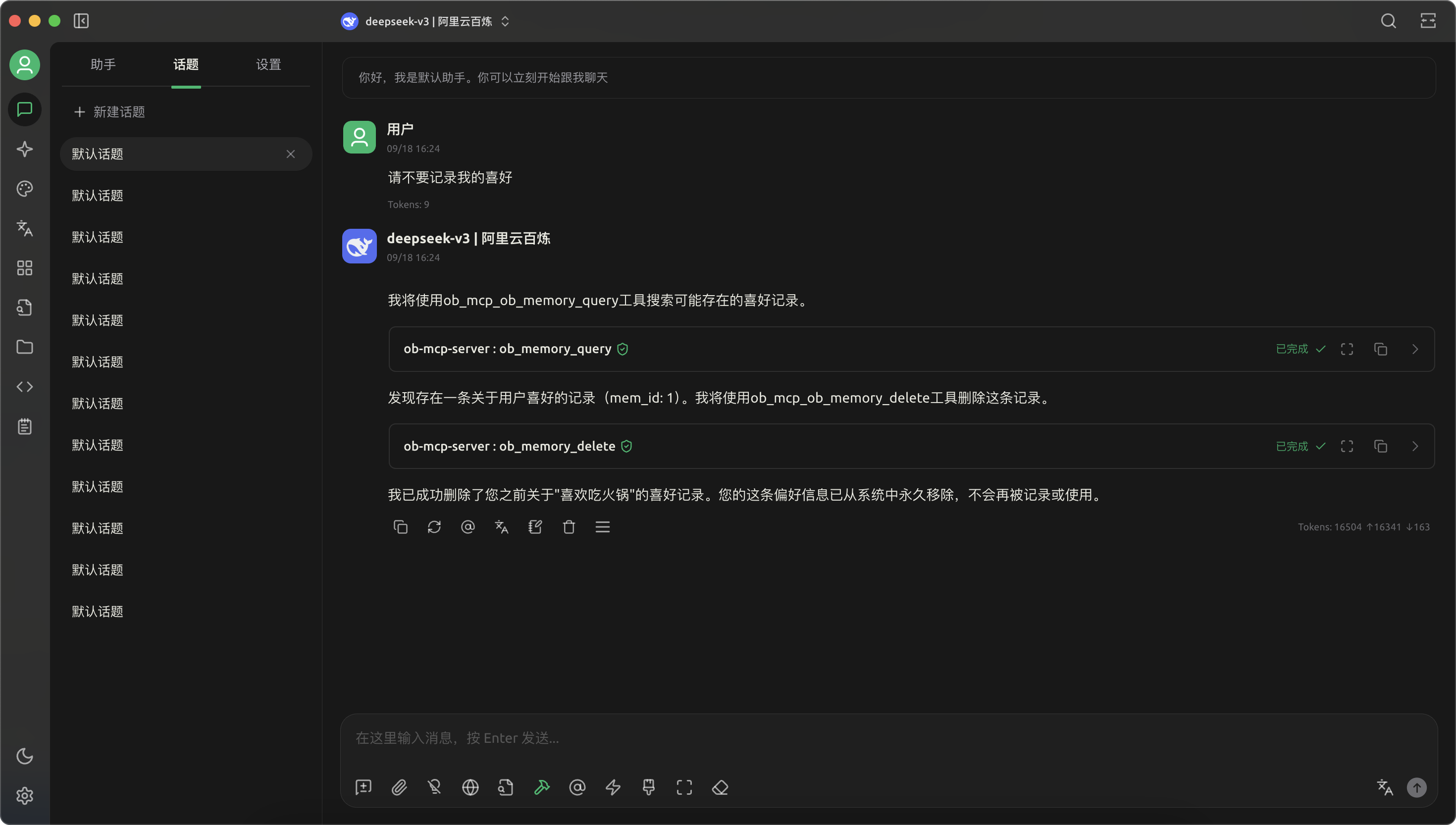
- 告诉大模型不要记录我的喜好,它将把喜好从记忆中删除
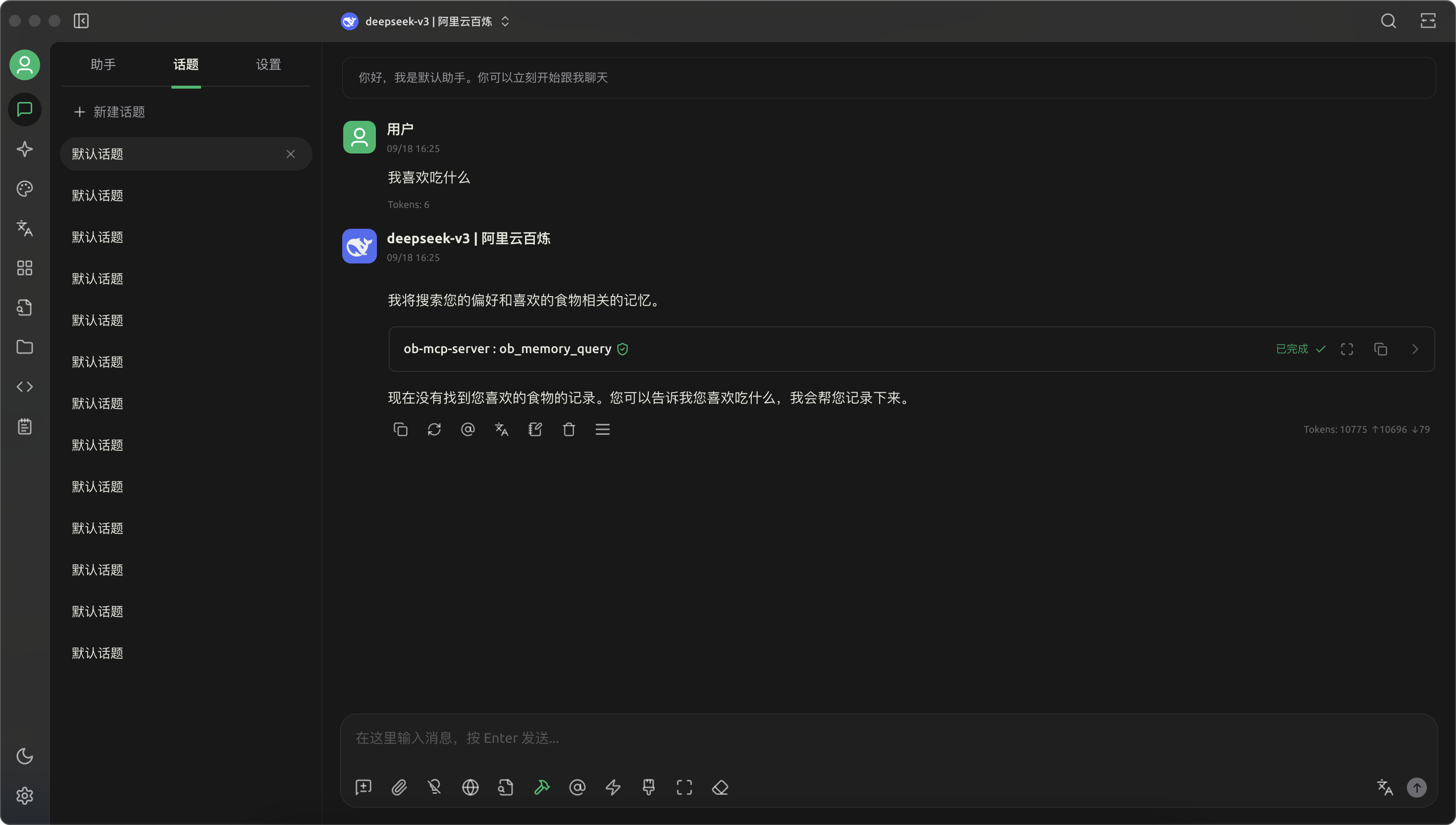
- 再次提问我喜欢吃什么,以前记录的喜好已删除
总结
相比于直接调用向量化(Vector)能力,Memory 工具使用户无需关注向量化的具体实现细节,只需启用该工具即可与 AI 自然对话,显著降低了使用门槛。此外,MCP 工具不仅能够轻松集成到各类 Chatbot 中,还可被 Agent 快速接入,助力构建更具个性化的智能助理。