

oms store 同步的原理?
**OMS 的 Store 组件通常将这些增量数据(变更事件)缓存在内存中用于高效同步,需要每条都持久化到oms节点的本地磁盘中吗? 这块的介绍在哪里?
3 个赞
同问
Oracle Reader
Oracle Reader 的主要流程包括:日志拉取、预解析过滤、事务管理、日志解析和回查。
日志拉取
基于 Oracle LogMiner 来获取增量变更日志(读取 V$LOGMNR_CONTENTS 的内容),可以通过并发拉取多个归档文件的变更来提升拉取速度。
预解析过滤
预解析出一些关键信息,比如该条变更属于哪张表,然后根据黑白名单进行过滤,仅保留需要同步的表的记录。
事务管理
由于 OMS 在使用 LogMiner 时不使用 DBMS_LOGMNR.COMMITTED_DATA_ONLY 选项(该选项在遇到大事务时可能会内存不足,OMS 自身可处理大事务),因此拉取的日志变更在事务层面可能是交错的,同时包含回滚的事务以及 ROLLBACK TO SAVEPOINT 的事务。在事务管理阶段将同一个事务聚合在一起,吐出已提交的事务,丢弃被回滚的事务,同时支持处理 ROLLBACK TO SAVEPOINT 的事务,**大事务暂存到磁盘以减少内存开销。**
日志解析
根据列类型对列值做解析。
回查
由于 LOB/LONG 等类型 LogMiner 并不保证会吐出该类型的值,因此一些变更还需要通过回查数据库获取该列的值
1 个赞
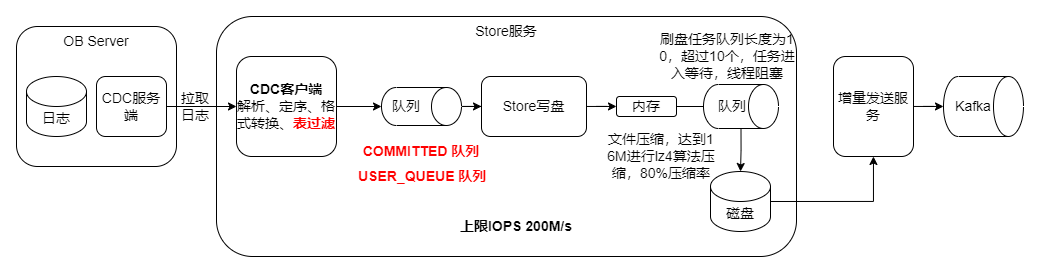
OMS 的 Store 组件主要负责从源端读取原始数据,包括数据库日志(如 Oracle 的 Redo Log 或 MySQL 的 Binlog),经过解析、过滤和格式化后,将增量数据持久化存储在 OMS 节点的本地磁盘中。持久化存储是为了防止数据丢失,并支持回拉功能,即使在 OMS 节点重启后仍能继续增量同步。
在 OMS 社区版中,增量数据的处理流程大致如下:
- 日志拉取:Store 组件通过特定的方法(如 Oracle 的 LogMiner 或 MySQL 的 Binlog)从源端获取增量变更日志。
- 预解析过滤:提取日志中的关键信息,如表名、操作类型等,并根据配置的黑白名单进行过滤,仅保留需要同步的记录。
- 事务管理:聚合同一个事务的变更记录,处理事务的提交和回滚,确保只有已提交的事务被同步。
- 日志解析:根据列类型对列值进行解析,转换成 OMS 内部格式。
- 回查:对于某些特殊类型的数据(如 LOB、LONG 类型),LogMiner 可能无法完整解析,需要通过回查数据库获取完整的列值。
- 持久化存储:将处理后的增量数据持久化存储到 OMS 节点的本地磁盘中,以便后续的增量同步组件(Incr-Sync)读取和应用。
在处理大事务时,OMS 会将大事务的变更记录暂存到磁盘,以减少内存开销,确保系统的稳定性和性能。
检索到的文档如下:
1 个赞
同问