每个盘有 4T 妥妥的够
info.txt (34.4 KB)
2 个赞
哪个视图呀老师
2 个赞
DBA_OB_TENANTS
obclient(root@sys)[oceanbase]> select * from DBA_OB_TENANTS where TENANT_ID=1002\G;
*************************** 1. row ***************************
TENANT_ID: 1002
TENANT_NAME: test
TENANT_TYPE: USER
CREATE_TIME: 2025-09-17 15:18:52.465702
MODIFY_TIME: 2025-09-17 15:18:52.465702
PRIMARY_ZONE: RANDOM
LOCALITY: FULL{1}@zone1, FULL{1}@zone2, FULL{1}@zone3
PREVIOUS_LOCALITY: NULL
COMPATIBILITY_MODE: MYSQL
STATUS: RESTORE
IN_RECYCLEBIN: NO
LOCKED: NO
TENANT_ROLE: RESTORE
SWITCHOVER_STATUS: NORMAL
SWITCHOVER_EPOCH: 0
SYNC_SCN: 1757516431141480004
REPLAYABLE_SCN: 1757516431141480004
READABLE_SCN: 1757516431141480004
RECOVERY_UNTIL_SCN: 1757516431141480004
LOG_MODE: NOARCHIVELOG
ARBITRATION_SERVICE_STATUS: DISABLED
UNIT_NUM: 2
COMPATIBLE: 4.3.5.3
MAX_LS_ID: 1018
RESTORE_DATA_MODE: REMOTE
COMMENT:
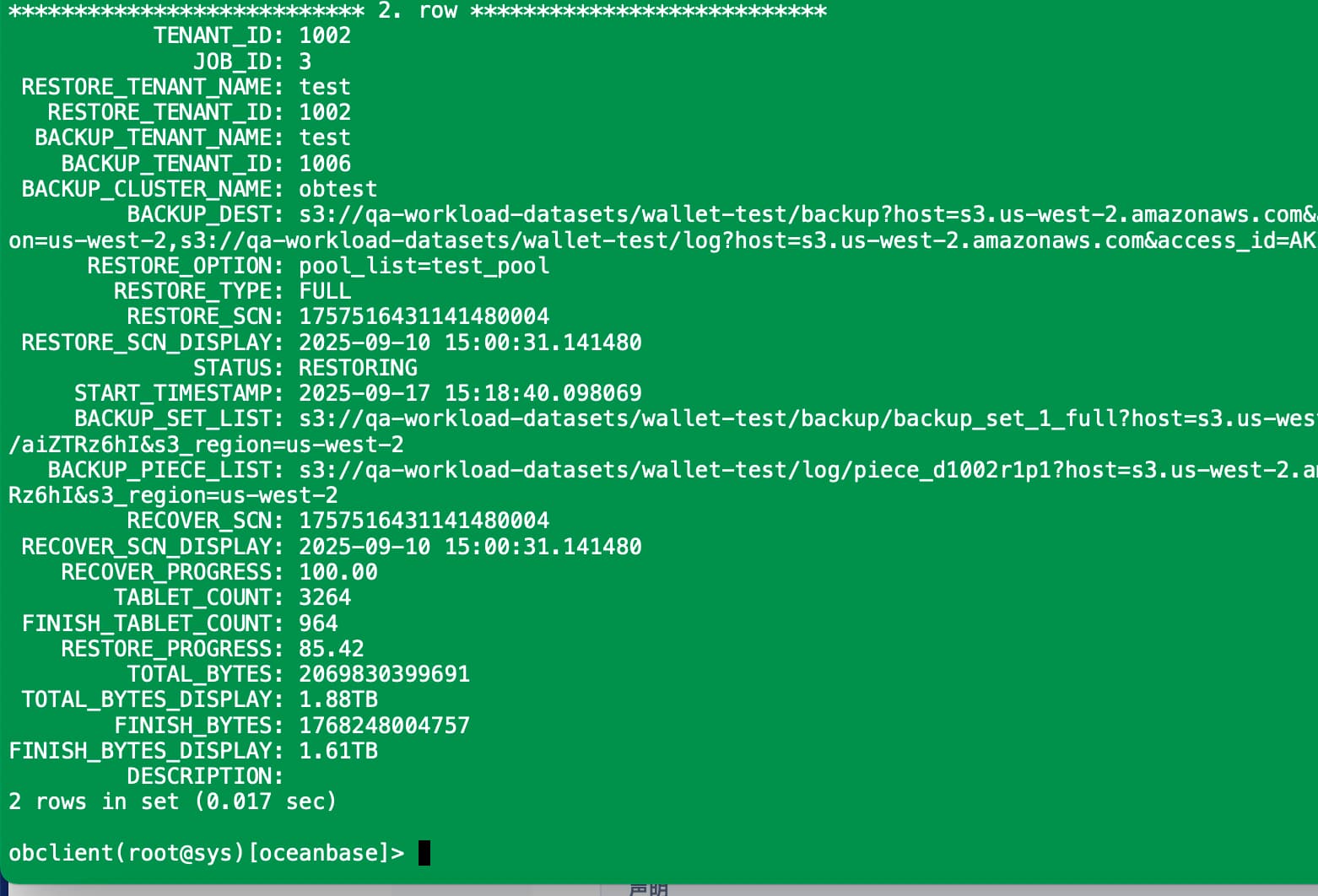
*************************** 2. row ***************************
TENANT_ID: 1002
JOB_ID: 3
RESTORE_TENANT_NAME: test
RESTORE_TENANT_ID: 1002
BACKUP_TENANT_NAME: test
BACKUP_TENANT_ID: 1006
BACKUP_CLUSTER_NAME: obtest
BACKUP_DEST: s3://qa-workload-datasets/wallet-test/backup?host=s3.us-west-2.amazonaws.com&access_id=AKIA5Y2EJ64JJO3JG2QQ&access_key=q1yEiUVoQf6wHrnuoDEPVTlqn6Pz1L/aiZTRz6hgion=us-west-2,s3://qa-workload-datasets/wallet-test/log?host=s3.us-west-2.amazonaws.com&access_id=AKIA5Y2EJ64JJO3JG2QQ&access_key=q1yEiUVoQf6wHrnuoDEPVTlqn6Pz1L/aiZTRz6hI&s3_region=-2
RESTORE_SCN: 1757516431141480004
RESTORE_SCN_DISPLAY: 2025-09-10 15:00:31.141480
RESTORE_OPTION: pool_list=test_pool
RESTORE_TYPE: FULL
START_TIMESTAMP: 2025-09-17 15:18:40.098069
FINISH_TIMESTAMP: 2025-09-18 12:01:57.127203
STATUS: SUCCESS
BACKUP_PIECE_LIST: s3://qa-workload-datasets/wallet-test/log/piece_d1002r1p1?host=s3.us-west-2.amazonaws.com&access_id=AKIA5Y2EJ64JJO3JG2QQ&access_key=q1yEiUVoQf6wHrnuoDEPVTlqn6ZTRz6hI&s3_region=us-west-2
BACKUP_SET_LIST: s3://qa-workload-datasets/wallet-test/backup/backup_set_1_full?host=s3.us-west-2.amazonaws.com&access_id=AKIA5Y2EJ64JJO3JG2QQ&access_key=q1yEiUVoQf6wHrnuoDEPV1L/aiZTRz6hI&s3_region=us-west-2
BACKUP_CLUSTER_VERSION: 17180067075
LS_COUNT: 7
FINISH_LS_COUNT: 0
TABLET_COUNT: 3264
FINISH_TABLET_COUNT: 3264
TOTAL_BYTES: 2069830399691
TOTAL_BYTES_DISPLAY: 1.88TB
FINISH_BYTES: 2069830399691
FINISH_BYTES_DISPLAY: 1.88TB
DESCRIPTION: NULL
COMMENT:
2 rows in set (0.023 sec)
这个速度也太慢了 全备时间 包括 日志恢复+restore 的吧? 这是我第二次全备恢复 上次也是 10 几个 小时
目前restore有进度了是吧?
这个1002租户一共有多少tablet呢?
select count(*),zone from dba_ob_table_locations group by zone;
对,你再查下这两个SQL,我看下耗时明细
select gmt_create, name2, value2, name3, value3, rs_svr_ip, rs_svr_port, timestampdiff(SECOND, gmt_create, lead(gmt_create) over (order by gmt_create)) as cost from __all_rootservice_event_history where module like 'physical_restore' and event like 'change_restore_status' and value1=2 order by gmt_create;
select gmt_create, svr_ip, svr_port, name2, value2, name3, value3, name4, value4, name5, value5, name6, value6 from __all_server_event_history where event like 'restore_ls' and value1=1002 and cast(value3 as unsigned)<7 order by cast(value2 as unsigned), svr_ip, svr_port, cast(value3 as unsigned);
第一个
obclient(root@sys)[oceanbase]> select gmt_create, name2, value2, name3, value3, rs_svr_ip, rs_svr_port, timestampdiff(SECOND, gmt_create, lead(gmt_create) over (order by gmt_create)) as cost from __all_rootservice_event_history where module like 'physical_restore' and event like 'change_restore_status' and value1=2 order by gmt_create;
Empty set (0.006 sec)
第二个

修正了下sql,再查下,发下完整的数据
select gmt_create, name2, value2, name3, value3, rs_svr_ip, rs_svr_port, timestampdiff(SECOND, gmt_create, lead(gmt_create) over (order by gmt_create)) as cost from __all_rootservice_event_history where module like 'physical_restore' and event like 'change_restore_status' and value1=3 order by gmt_create;
select gmt_create, svr_ip, svr_port, name2, value2, name3, value3, name4, value4, name5, value5, name6, value6 from __all_server_event_history where event like 'restore_ls' and value1=1002 and cast(value3 as unsigned)<7 order by cast(value2 as unsigned), svr_ip, svr_port, cast(value3 as unsigned);
select count(*),zone from cdb_ob_table_locations where TENANT_ID=1002 group by zone;
第一个 sql
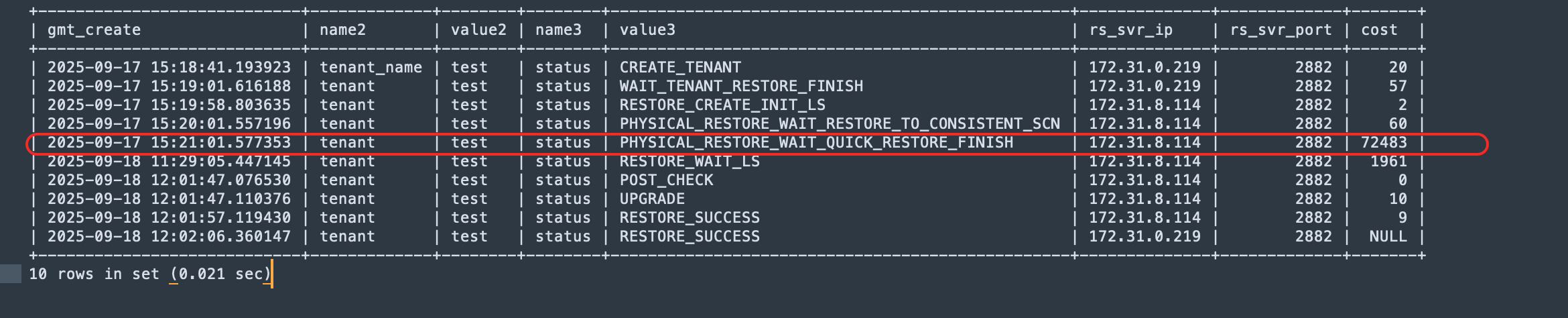
obclient(root@sys)[oceanbase]> select gmt_create, name2, value2, name3, value3, rs_svr_ip, rs_svr_port, timestampdiff(SECOND, gmt_create, lead(gmt_create) over (order by gmt_create)) as cost from __all_rootservice_event_history where module like 'physical_restore' and event like 'change_restore_status' and value1=3 order by gmt_create;
+----------------------------+-------------+--------+--------+-------------------------------------------------+--------------+-------------+-------+
| gmt_create | name2 | value2 | name3 | value3 | rs_svr_ip | rs_svr_port | cost |
+----------------------------+-------------+--------+--------+-------------------------------------------------+--------------+-------------+-------+
| 2025-09-17 15:18:41.193923 | tenant_name | test | status | CREATE_TENANT | 172.31.0.219 | 2882 | 20 |
| 2025-09-17 15:19:01.616188 | tenant | test | status | WAIT_TENANT_RESTORE_FINISH | 172.31.0.219 | 2882 | 57 |
| 2025-09-17 15:19:58.803635 | tenant | test | status | RESTORE_CREATE_INIT_LS | 172.31.8.114 | 2882 | 2 |
| 2025-09-17 15:20:01.557196 | tenant | test | status | PHYSICAL_RESTORE_WAIT_RESTORE_TO_CONSISTENT_SCN | 172.31.8.114 | 2882 | 60 |
| 2025-09-17 15:21:01.577353 | tenant | test | status | PHYSICAL_RESTORE_WAIT_QUICK_RESTORE_FINISH | 172.31.8.114 | 2882 | 72483 |
| 2025-09-18 11:29:05.447145 | tenant | test | status | RESTORE_WAIT_LS | 172.31.8.114 | 2882 | 1961 |
| 2025-09-18 12:01:47.076530 | tenant | test | status | POST_CHECK | 172.31.8.114 | 2882 | 0 |
| 2025-09-18 12:01:47.110376 | tenant | test | status | UPGRADE | 172.31.8.114 | 2882 | 10 |
| 2025-09-18 12:01:57.119430 | tenant | test | status | RESTORE_SUCCESS | 172.31.8.114 | 2882 | 9 |
| 2025-09-18 12:02:06.360147 | tenant | test | status | RESTORE_SUCCESS | 172.31.0.219 | 2882 | NULL |
+----------------------------+-------------+--------+--------+-------------------------------------------------+--------------+-------------+-------+
10 rows in set (0.021 sec)
第二条
info.txt (34.4 KB)
obclient(root@sys)[oceanbase]> select count(),zone from cdb_ob_table_locations where TENANT_ID=1002 group by zone;
±---------±------+
| count() | zone |
±---------±------+
| 3264 | zone2 |
| 3264 | zone3 |
| 3264 | zone1 |
±---------±------+
3 rows in set (0.300 sec)
学习了!!!
遇到类似问题,也是全备恢复租户时,在这个状态特别耗时 PHYSICAL_RESTORE_WAIT_QUICK_RESTORE_FINISH
使用的OB版本是:4.3.5
蹲一个原因
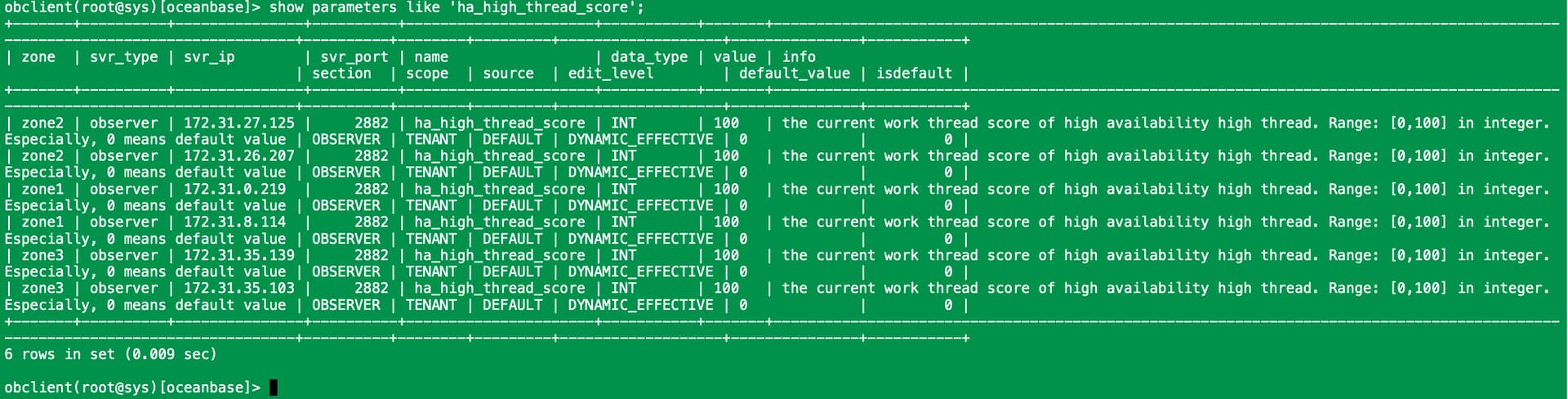
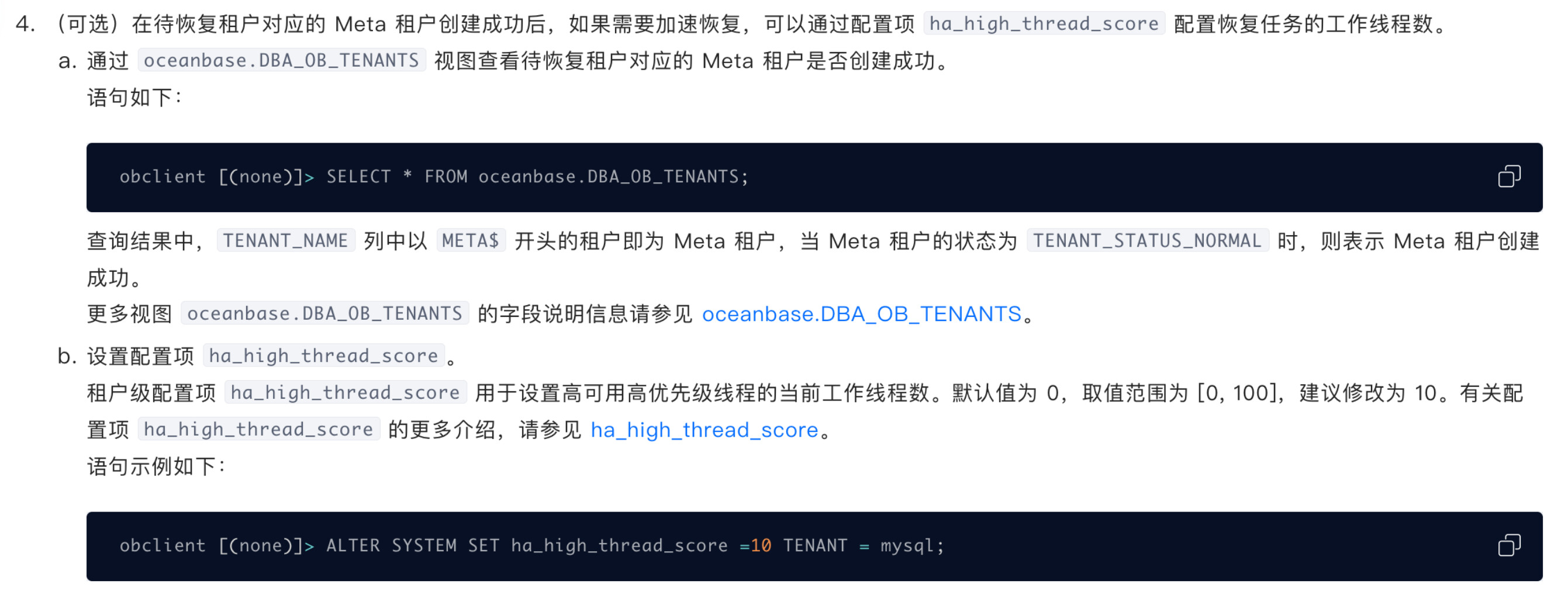
PHYSICAL_RESTORE_WAIT_QUICK_RESTORE_FINISH 这一步耗费了20小时+,我咨询了研发,目前建议是调大参数 ha_high_thread_score 再观察下,调整方式如下
2 个赞
感谢分享!!!
看着问题好复杂
优秀