

45 个赞
OceanBase 4.3.6 全量恢复中 Recover 完成但 Restore 进度为 0 的原因分析与排查方法
您遇到的问题是在 OceanBase 4.3.6 版本中执行全量备份恢复时,recovery 阶段已于昨晚 23 点完成,但 restore 进度条仍显示为 0。这种情况看似矛盾,实则可能由系统状态展示延迟或概念误解引起。以下基于官方文档和恢复机制进行全面解析。
 核心结论
核心结论
极大概率:数据 restore 实际已完成,但由于状态未正确刷新或监控工具延迟,导致
RESTORE_PROGRESS显示为 0。
OceanBase 的恢复流程中,“restore”和“recover”是两个不同阶段:
-
 Restore:指将备份集中的数据文件加载到目标集群;
Restore:指将备份集中的数据文件加载到目标集群; -
Recover:指应用归档日志(archive log)到指定时间点或 SCN。
正确的顺序是:先完成 restore,再执行 recover。
因此,如果 recover 已完成,说明数据 restore 早已完成 —— 否则无法进入日志恢复阶段。
 关键系统视图与字段说明
关键系统视图与字段说明
请使用 sys 租户登录,并查询以下视图以获取真实状态:
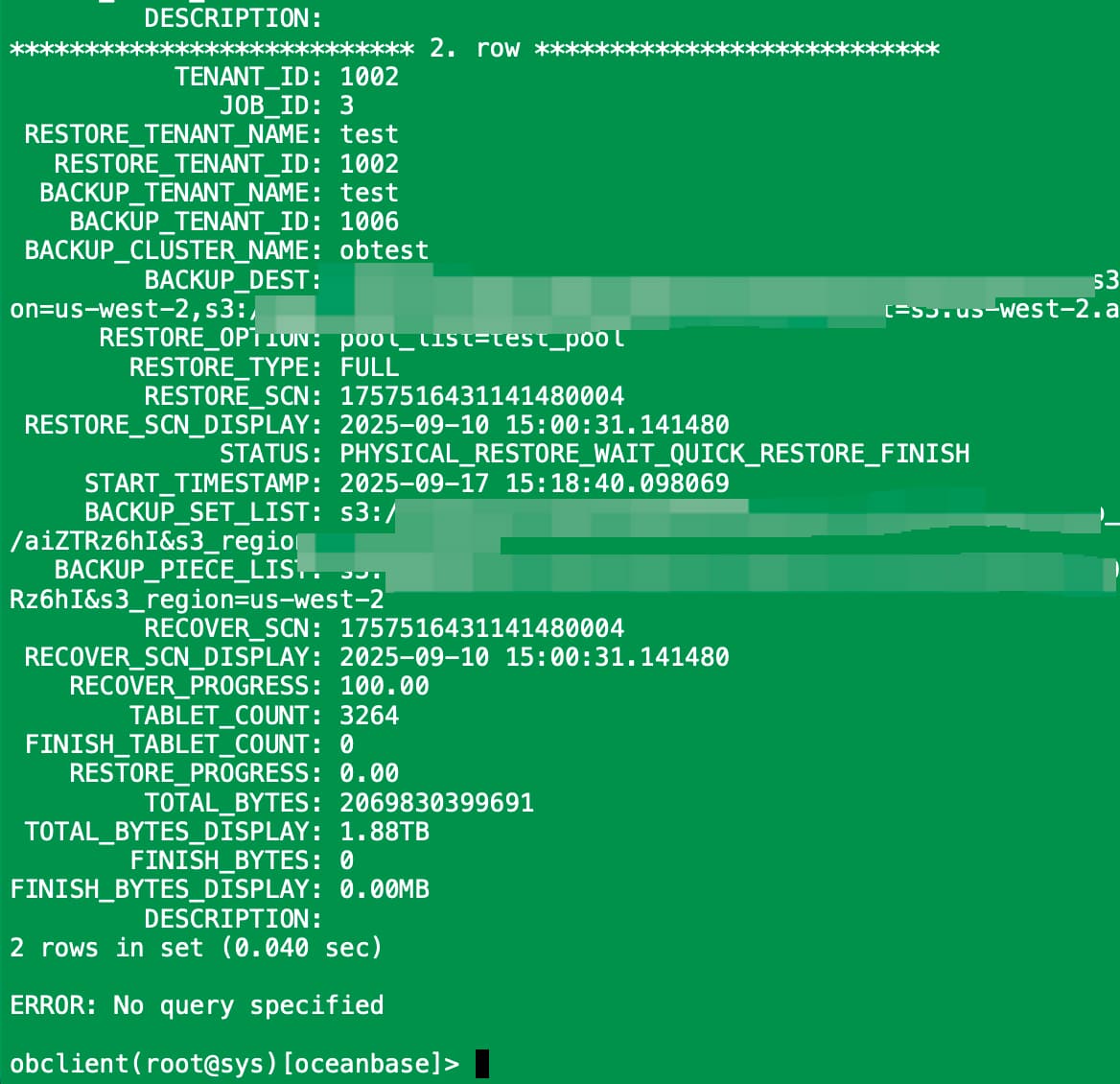
1. CDB_OB_RESTORE_PROGRESS:查看恢复任务总体进度
SELECT
TENANT_ID,
JOB_ID,
RESTORE_TENANT_NAME,
STATUS,
RESTORE_PROGRESS, -- 数据恢复进度(%)
RECOVER_PROGRESS, -- 日志恢复进度(%)
RECOVER_SCN_DISPLAY, -- 日志恢复完成时间
TOTAL_BYTES_DISPLAY,
FINISH_BYTES_DISPLAY
FROM oceanbase.CDB_OB_RESTORE_PROGRESS;
重点关注字段:
-
RESTORE_PROGRESS:应接近 100% -
RECOVER_PROGRESS:应为 100% 或已达到目标 SCN -
STATUS:应为RESTORE_SUCCESS或类似成功状态
 常见原因分析
常见原因分析
 原因一:混淆了“restore”与“recover”的含义
原因一:混淆了“restore”与“recover”的含义
许多管理工具或前端界面将整个恢复过程统称为“restore”,但实际上:
- “进度条为0”可能是前端仅监控
RESTORE_PROGRESS,而忽略了RECOVER_PROGRESS。 - 当前处于 recover 完成阶段,系统认为任务即将结束,不再更新
RESTORE_PROGRESS。
![]() 建议:不要依赖单一“进度条”,应结合多个视图判断。
建议:不要依赖单一“进度条”,应结合多个视图判断。
 原因二:系统状态未及时刷新(常见于 V4.1+)
原因二:系统状态未及时刷新(常见于 V4.1+)
根据文档描述,在 V4.1.0 及以上版本中,OceanBase 采用“日志齐步走”策略。某些情况下,即使日志已全部回放完毕,restore_status 仍可能停留在 6 或 8 状态,导致外部感知异常。
排查步骤如下:
步骤 1:检查日志是否已恢复至租户
SELECT count(1) FROM oceanbase.GV$OB_LOG_STAT
WHERE tenant_id = <your_tenant_id>
AND end_scn < (SELECT recovery_until_scn FROM oceanbase.DBA_OB_TENANTS WHERE tenant_id = <your_tenant_id>);
- 若返回 0 → 表示日志已全部加载成功。
步骤 2:检查日志是否已回放完成
-- 查看待回放任务数量
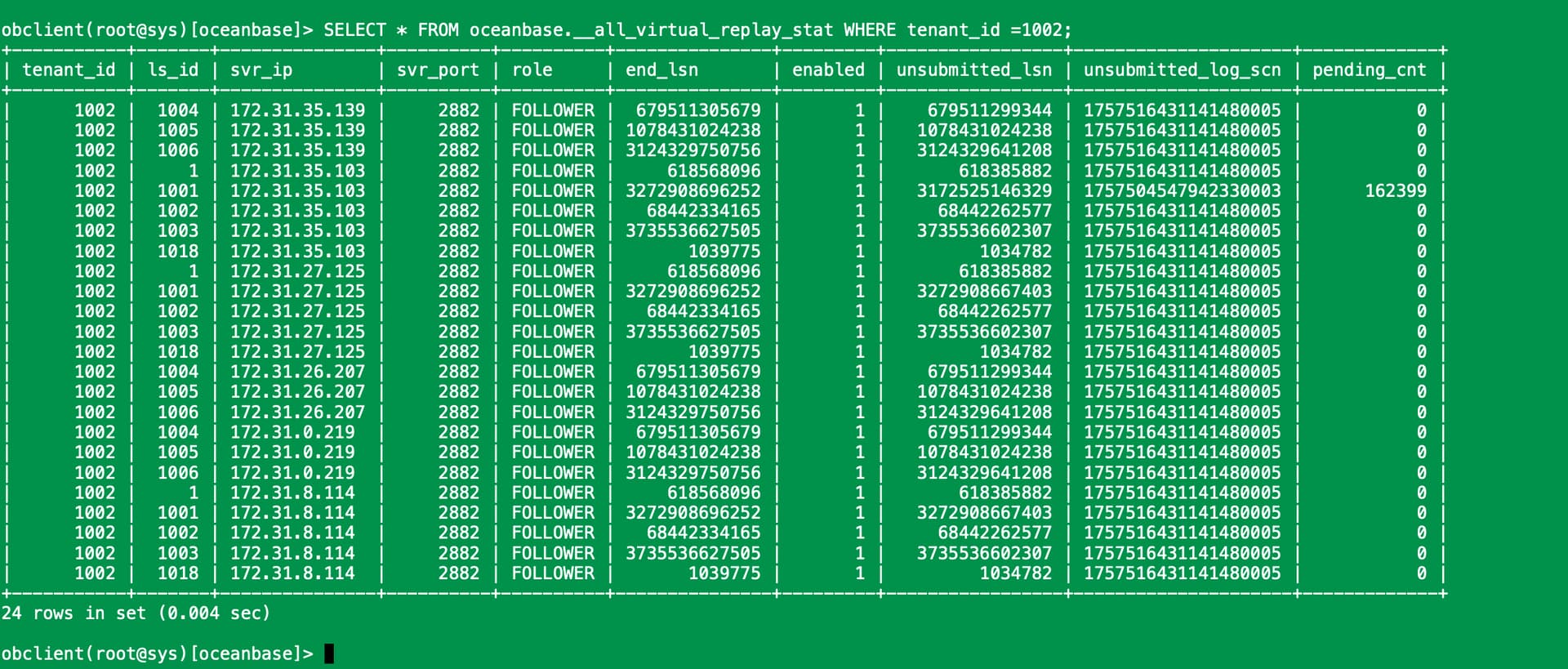
SELECT * FROM oceanbase.__all_virtual_replay_stat WHERE tenant_id = <your_tenant_id>;
-- 获取恢复终点 SCN
SELECT recovery_until_scn FROM oceanbase.DBA_OB_TENANTS WHERE tenant_id = <your_tenant_id>;
- 如果
pending_cnt = 0且unsubmitted_log_scn >= recovery_until_scn→ 回放完成。
步骤 3:确认 1 号日志流是否同步完成
SELECT ls_id, sync_scn, recovery_until_scn
FROM oceanbase.CDB_OB_LS
WHERE tenant_id = <your_tenant_id>;
- 如果
sync_scn >= recovery_until_scn→ 恢复真正完成。
SELECT * FROM oceanbase.DBA_OB_ROOTSERVICE_EVENT_HISTORY WHERE event LIKE ‘change_restore_status’ AND value1 = <job_id> ORDER BY gmt_create DESC;
解决建议
| 步骤 | 操作 |
|---|---|
| 1 | 登录 sys 租户,确认 CDB_OB_RESTORE_PROGRESS.STATUS 是否为成功状态 |
| 2 | 查询 GV$OB_LOG_STAT 和 __all_virtual_replay_stat 确认日志回放是否完成 |
| 3 | 检查 CDB_OB_LS.sync_scn >= recovery_until_scn 是否成立 |
| 4 | 如所有指标均满足,可认为恢复已完成,无需干预 |
| 5 | 若仍有疑问,导出 trace_id 并联系技术支持 |
 总结
总结
| 问题表现 | 实际含义 | 是否正常 |
|---|---|---|
| Recover 完成,Restore 进度为 0 | 数据 restore 已完成,状态未刷新 |
|
| RECOVER_PROGRESS=100%,但界面卡住 | 恢复流程结束,前端未更新 |
|
状态长期停滞在 RESTORE_WAIT_LS
|
需排查日志流恢复阻塞 |
|
提示:在 OceanBase 中,
RECOVER_PROGRESS达到 100% 即代表恢复完成,RESTORE_PROGRESS仅为中间阶段参考值,后期可能不再更新。
6 个赞
查下这个sql
SELECT * FROM oceanbase.DBA_OB_ROOTSERVICE_EVENT_HISTORY WHERE module='physical_restore';
4 个赞
DBA_OB_ROOTSERVICE_EVENT_HISTORY,看看有没有记录
4 个赞
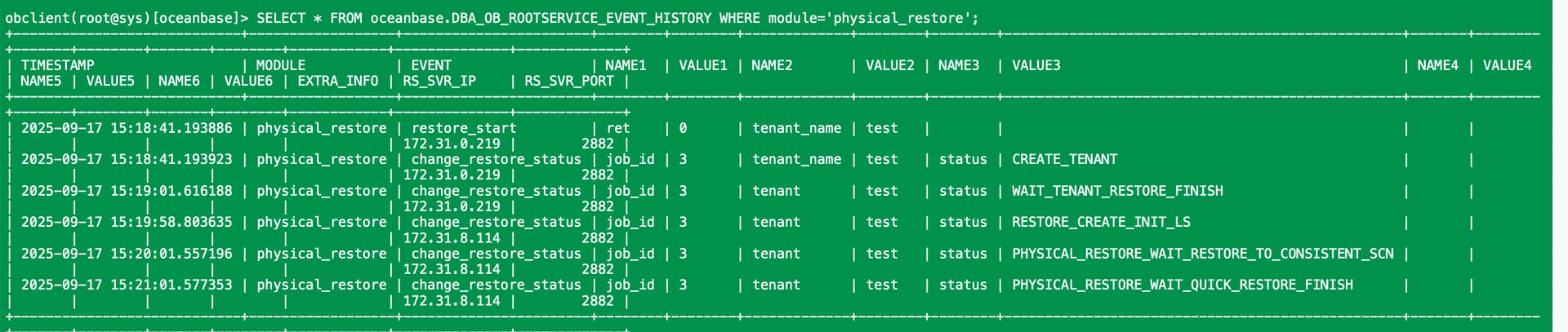
有7千多条记录
4 个赞


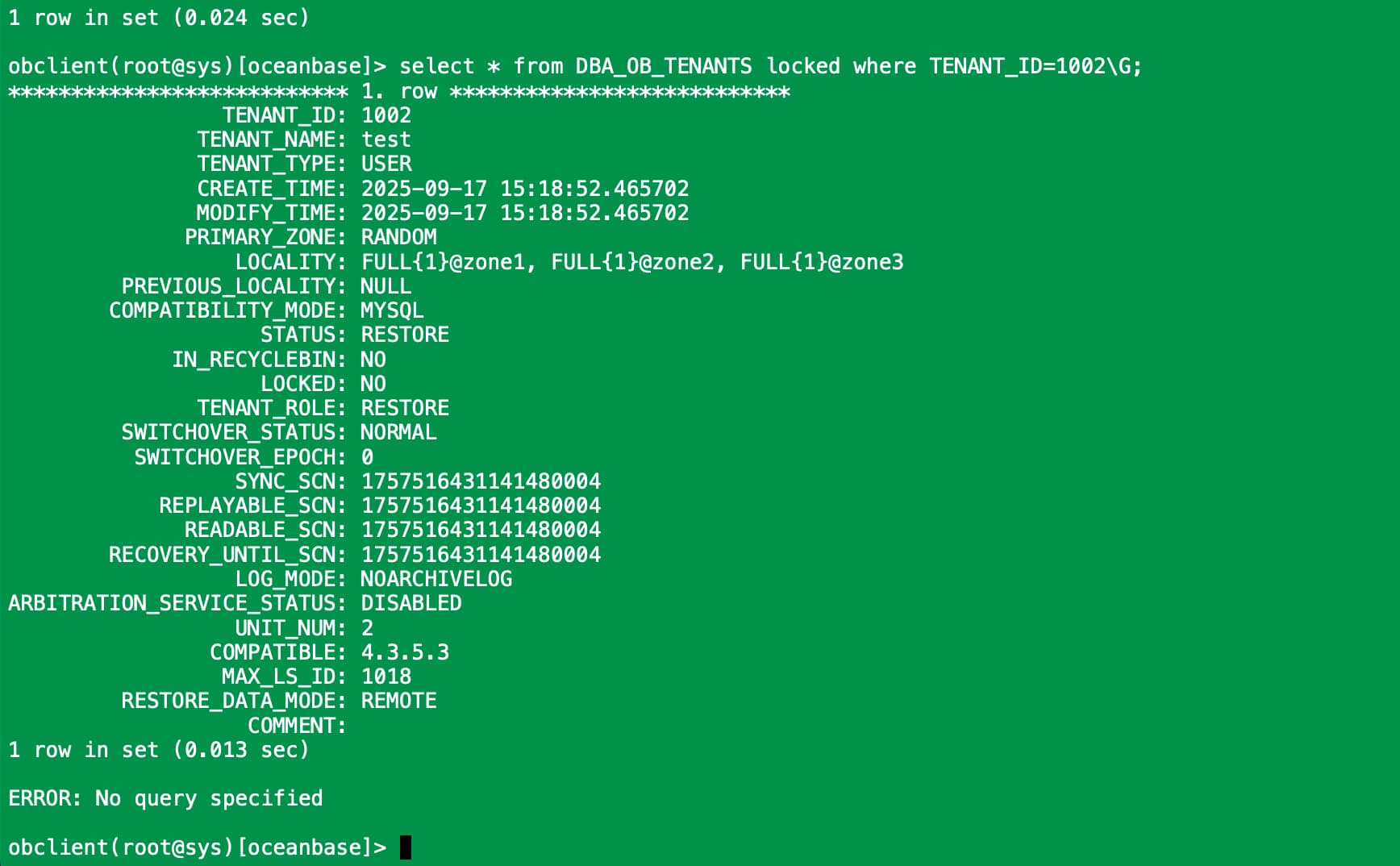
还没有恢复完成,你发起恢复的命令发下
从什么版本恢复到什么版本?
show variables like '%version_comment%';
3 个赞
4.3.5.3 到 4.3.5.4
2 个赞
ALTER SYSTEM RESTORE test FROM ‘s3://datasets/backup/?xxxxx, s3://datasets/test/log/?xxx’ WITH ‘pool_list=test_pool’;
2 个赞
正常的物理恢复流程如下, 每一个副本的几乎所有数据都是在RESTORE_WAIT_LS 阶段恢复的,也因此,通常来说,RESTORE_WAIT_LS 阶段是最耗时的阶段,
你这里有些奇怪,目前看到 RECOVER_PROGRESS是100%,就是日志恢复已经完成,卡在了 PHYSICAL_RESTORE_WAIT_QUICK_RESTORE_FINISH,下一个阶段即 RESTORE_WAIT_LS 还没开始,我在看下有什么排查方法

1 个赞
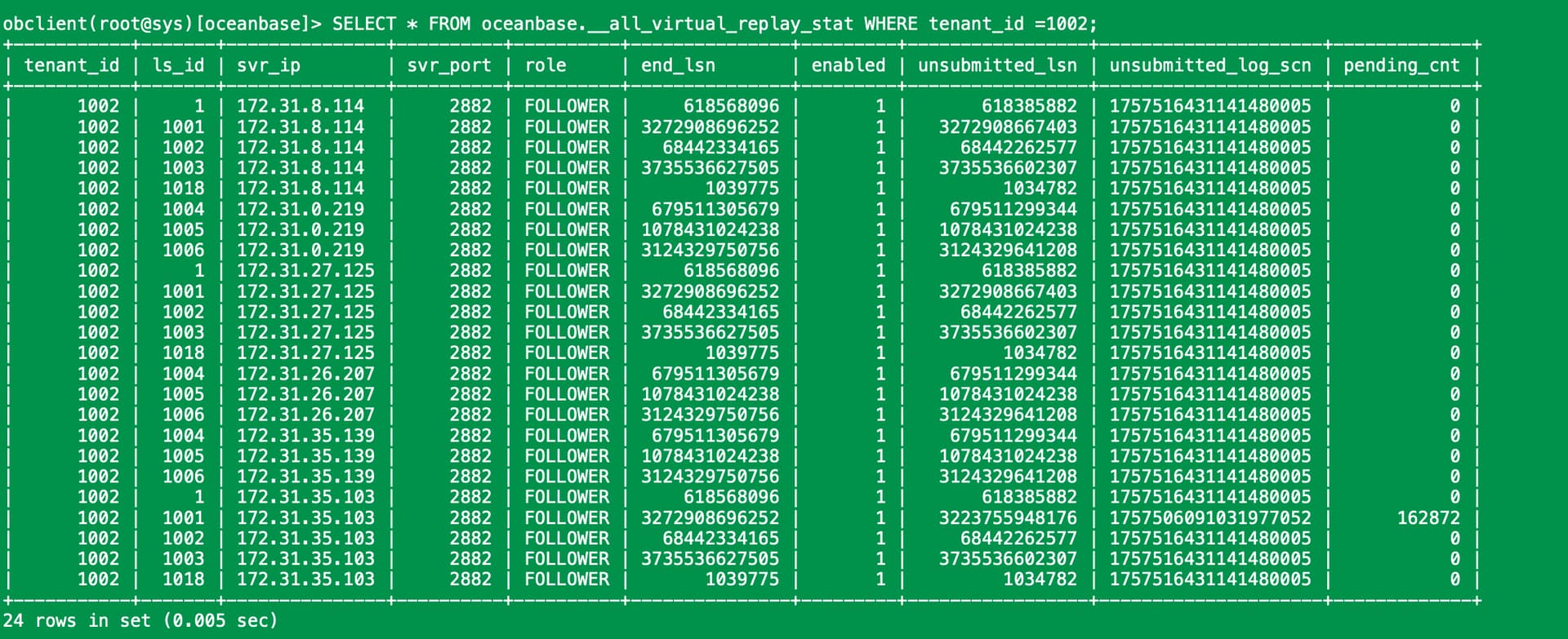
查下这个看是否有数据,sys租户下查下
select gmt_create, svr_ip, svr_port, name2, value2, name3, value3, name4, value4, name5, value5, name6, value6 from __all_server_event_history where event like 'restore_ls' and value1=1002 and cast(value3 as unsigned)<7 order by cast(value2 as unsigned), svr_ip, svr_port, cast(value3 as unsigned);
1 个赞
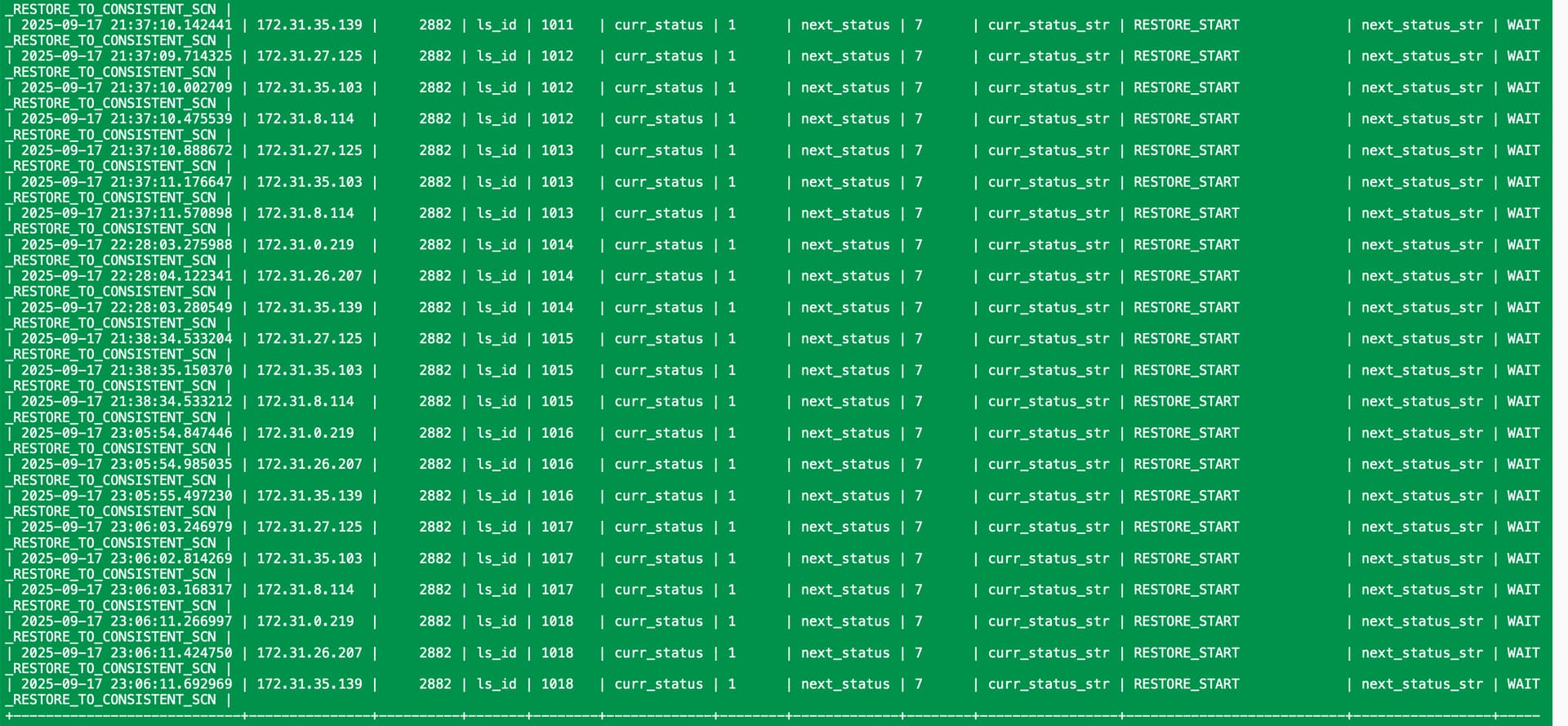
你发下完整的数据,
另外检查下恢复环境 空间是否足够?
1 个赞
查几次这个视图,观察下READABLE_SCN 值是否还有变化?