

OceanBase 存储过程概述
存储过程可以用来 “封装” 一组为了完成特定功能的 SQL 语句集,经编译后存储在数据库中,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。

使用存储过程的优势
- 重复使用,提升性能。存储过程只在创建时进行编译,以后每次执行存储过程都不需要重新编译,而一般 SQL 语句每执行一次就编译一次,使用存储过程可提高数据库执行速度。
- 减少网络流量。存储过程位于服务器上,调用的时候只需要传递存储过程的名称以及参数即可,降低了网络传输的数据量。
- 安全性。参数化的存储过程可以防止 SQL 注入式攻击。
说明:
通常情况下,从业务维护和可读性、透明性,以及操作安全性的角度来说,存储过程和触发器这类需求,一般都在业务应用层实现。不鼓励利用数据库中的机制来写非常复杂的业务逻辑,这类业务逻辑放在应用层实现,可读性会更好,而且在数据库迁移的时候,也不用重写逻辑。
边学边练,效果拔群
正所谓 “纸上得来终觉浅,实践才能出真知”,强烈推荐大家点击下面的链接,根据在线体验页面左边的实验文档,亲手体验一把 OceanBase 数据库中存储过程的典型使用场景。
-
在线实验地址:《OceanBase 数据库存储过程典型使用场景》。
- 这个实验应该算是典型使用场景中最基础的场景。在后续的实战营活动中,会有 OceanBase 的资深产研同学进一步为大家介绍通过 “存储过程 + 临时表” 代替传统 ETL 等在生产环境中更加高阶的使用场景。
-
课后小测地址:【DBA 实战营】PL 中的存储过程。
- 大家完成课后小测,并在小测中上传实验截图,判卷通过后就会自动获取 10 积分,并自动获得抽奖资格,有机会获得实体礼物或更高额的积分奖励。

闲言少叙,正文开始。
存储过程的语法不算复杂,详见 OceanBase 官方文档 —— 存储过程。以各位读者的聪明才智,看下官方文档中的几个例子就知道怎么写了,很类似于编程语言里的函数(Function)。
说明:
数据库中也有函数(Function)的概念和能力,和存储过程不同,优点是可以在 SQL 查询中嵌入计算(如 SELECT fn_add(score, 10) …),缺点是不适合封装复杂的 DML 操作和事务,只适合封装其他的计算逻辑(例如四则运算)。
| 维度 | 存储过程(Procedure) | 函数(Function) |
|---|---|---|
| 核心目标 | 执行动作(Do) | 计算并返回值(Return) |
| 返回值 | 无/多(通过 OUT/INOUT) | 必须单值(RETURN) |
| 调用方式 | CALL 单独调用 | 嵌入 SQL 语句(如 SELECT) |
| 参数类型 | IN/OUT/INOUT | 仅 IN(输入) |
| 事务支持 | 支持(COMMIT/ROLLBACK) | 不支持(写事务语句会报错) |
| 结果集返回 | 支持(SELECT 直接返回) | 不支持(函数内写 SELECT 报错) |
存储过程的一个简单示例
在线体验里的示例相对复杂,这里就反过来,给大家写一个最简单的存储过程示例。
现有雇员信息 emp 表(包括员工姓名和薪水),写一个简单的储存过程来修改员工薪水。
emp 表信息:
desc emp;
+----------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+--------------+------+-----+---------+-------+
| ename | varchar(10) | NO | PRI | | |
| sal | decimal(7,2) | YES | | NULL | |
| hiredata | date | YES | | NULL | |
+----------+--------------+------+-----+---------+-------+
3 rows in set (0.03 sec)
select * from emp;
+--------+----------+------------+
| ename | sal | hiredata |
+--------+----------+------------+
| Harry | 50000.00 | NULL |
| Larry | 40000.00 | NULL |
| Maggie | 46000.00 | NULL |
| OB_User| 15000.00 | NULL |
+--------+----------+------------+
6 rows in set (0.00 sec)
存储过程如下:
delimiter //
create procedure sp_update(in spname varchar(10), in spsal decimal(7,2))
-> begin
-> declare a varchar(10);
-> declare b decimal(7,2);
-> set a = spname, b = spsal;
-> update emp set sal = b where ename = a;
-> end
-> //
Query OK, 0 rows affected (0.00 sec)
Delimiter ;
说明:
OceanBase MySQL 模式的租户,兼容 MySQL 语法,需要使用与 MySQL 相同的语法,即需要设置 Delimiter //,执行完后需要恢复 Delimiter ;。
调用存储过程:
call sp_update('OB_User', 55000);
Query OK, 1 row affected (0.02 sec)
查看执行结果:
select * from emp;
+--------+----------+------------+
| ename | sal | hiredata |
+--------+----------+------------+
| Harry | 50000.00 | NULL |
| Larry | 40000.00 | NULL |
| Maggie | 46000.00 | NULL |
| OB_User| 55000.00 | NULL |
+--------+----------+------------+
6 rows in set (0.00 sec)
OceanBase PL 总体架构
下面这部分内容会稍稍偏底层实现一些。
对 OceanBase 中 PL 和存储过程感兴趣的同学可以选择性地进行阅读。
PL/SQL 是一种程序语言,叫做过程化 SQL语言(Procedural Language/SQL),从 Ada 语言发展而来。PL/SQL 是数据库对 SQL 语句的扩展,在普通 SQL 语句的基础上增加了编程语言的特点,把数据操作和查询语句组织在 PL/SQL 代码的过程化代码中,通过逻辑判断、循环等操作实现复杂的功能。
使用 PL/SQL 可以编写具有很多高级功能的程序,能够把业务逻辑封装在数据库内部,提供更好的抽象或者安全性,同时减少了网络的交互,并且调用更快,从而提升整体性能。
MySQL 的过程化 SQL(存储过程、函数、触发器等)是解释执行:创建时仅做语法/语义检查,执行时由服务器逐行解析并运行内部的 SQL 语句和流程控制逻辑,无预编译为机器码或中间可执行形式。
OceanBase PL 采用编译执行的方式,使用 LLVM 生成 native code,并直接把机器码装载到程序段执行,无需依赖外部 C 编译器和生成动态链接库。编译后的程序比解释执行性能提升 1.05 到 2.4 倍,具体提升的程度取决于程序的特性(因为 OceanBase 中 SQL 语句本身还是解释执行的,如果 PL 的主体是程序控制逻辑,那么性能提升效果会很明显)。
说明:MySQL 8.0 等新版本对存储过程执行效率有优化,但“解释执行”的本质逻辑未改变,只是通过缓存执行计划、优化解析流程等手段提升性能。
下图展示了 OceanBase PL 引擎的总体流程。
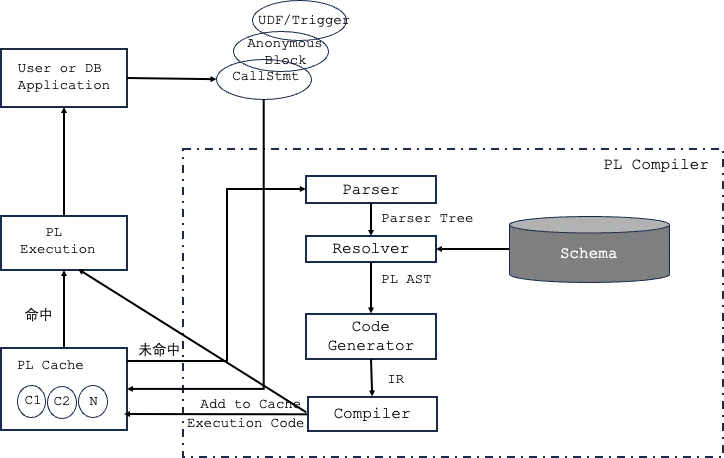
当客户端一条 PL 命令进入 OceanBase 之后,它会依次经过如上的各个组件,最终将执行结果返回给客户端。
接下来我们按照执行顺序简单介绍一下 OceanBase PL 引擎的各个组件,通过了解 PL 的各个组件,大家基本就能拼出 PL 在 OceanBase 中的执行流程了。
PL 缓存器(pl-cache)
OceanBase 会将 PL 编译后的可执行代码缓存在 pl-cache 中,以便对编译结果进行复用,降低 PL 编译的开销,提升整体的执行效率。对于一条 PL 命令而言,如果 pl-cache 中已经缓存了该条命令涉及到的 PL 程序的编译结果,那么 OceanBase 会使用该缓存的编译结果进行执行,否则进入正常的 PL 程序编译流程,生成的编译结果将被添加到 pl-cache 中供后续 PL 命令复用。
语法分析(Parser)
当一条 PL 命令涉及到的 PL 程序未命中 pl-cache 的时候,它会进入正常的语法分析流程。语法分析的过程把输入的 PL 程序字符串转换为一颗语法树。语法树不包含语义信息,仅仅是是字面的表示。这个过程完全使用 flex 和 bison 自动生成。输出结果是以 ParseNode 为节点的树。
语义分析(Resolver)
语义分析把输入的语法树转换为包含 PL 程序语义的内部数据结构表示(ObPLAST)。在此过程中,还要根据 PL 程序的语义进行语义检查,及时报错。例如,语义检查的内容包括:
- 在使用变量时,变量是否已经进行了定义,类型是否合法。
- 同一个名字空间下符号是否有重复定义,对于重复定义的符号需要及时报错。
- PL 程序中使用的表、列、自定义类型、包、函数等对象是否已经存在。
语义分析的输出为 ObPLAST,这个结构是由符号表、类型表、异常表、标签表以及多个 ObPLStmt 和的集合,多个 stmt 对象表示 PL 程序中的每条指令语句,如 IF、While、Goto。
代码生成(Code generator)
OceanBase PL 采用编译执行的方式,因此由语义分析输出的 ObPLAST 还会进一步进行翻译,为后面编译成可执行代码做进一步的准备。OceanBase 的 PL 采用了 LLVM 作为编译器的后端,代码生成则是为通过使用 LLVM 提供的接口,把 AST 树翻译成 IR 中间码的过程。IR 码可以输出,以核对翻译过程是否正确。
编译(Compiler)
通过 LLVM JIT 把 IR 码生成可执行代码的过程,生成的可执行代码会缓存到 pl-cache 中,供其他语句复用。
PL 执行(PL Execution)
PL 执行器负责执行编译生成的可执行代码,除了执行代码外,执行器还需要做如下一些事情:
- 构造当前 PL 的执行环境,比如设置一些权限相关上下文、准本入参。
- 通过 SPI(Server Programming Interface) 与 SQL 引擎交互,将 PL 中需要执行的 SQL 语句交给 SQL 引擎执行,并从 SQL 引擎中返回结果。
- 处理 PL 的出参以及函数的返回值等信息。
说明:
SPI(Server Programming Interface)用于在 PL 程序中执行 SQL 操作(表达式计算和 SQL 查询)并返回结果。其广泛应用在 PL 实现的各个环节,如 procedure、function、trigger 等。
下图给出了 PL Engine 工作的调用关系图。PL 引擎(PL Engine)和 SQL 引擎(SQL Engine)可以互相交互,SQL 可以直接访问 PL 引擎,比如在一个 SQL 语句中使用了用户自定义函数(function)。PL 引擎可以通过 SPI 接口访问 SQL 引擎,比如在 PL 里进行表达式计算和执行 SQL 语句。
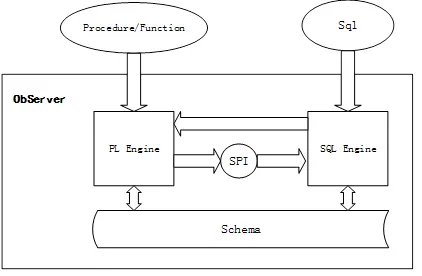
PL 的分布式执行
OceanBase 的分布式特性,天然决定 PL 的执行也是分布式的,但是这种分布式体现在 SQL 的分布式执行上,对于 PL 本身是不会分布式执行的,PL 自身的解析、编译和执行都在某一台 OBServer 节点上完成。当 PL 里涉及到 SQL 交互时,会通过 SPI 调用 SQL Engine,由 SQL Engine 执行 SQL 语句。如果该 SQL 语句是一个分布式的,那么自然而然会进行分布式执行。
分布式执行的 SQL 调用了 PL 函数时,PL 函数可能会在多台 OBServer 节点上编译执行,每台 OBServer 会保证在相同的环境参数下进行编译,从而编译出的 PL 具有相同的行为。