ob版本:4.3.5.3
执行:SELECT COUNT(*) FROM t_msg 耗时8秒左右,这个表有几百万数据
但是另外一张表,有1千多万条数据,执行count,却只需要几十毫秒。
t_msg的表结构:
CREATE TABLE t_msg (
msg_id varchar(64) NOT NULL COMMENT ‘消息id,64位整型’,
msg_type varchar(20) DEFAULT NULL COMMENT ‘消息类型:text image voice video location link’,
ToUserName varchar(100) DEFAULT NULL COMMENT ‘开发者微信号’,
FromUserName varchar(100) DEFAULT NULL COMMENT ‘发送方帐号(一个OpenID)’,
Content varchar(1000) DEFAULT NULL COMMENT ‘文本消息内容’,
PicUrl varchar(500) DEFAULT NULL COMMENT '图片链接 ',
MediaId varchar(100) DEFAULT NULL COMMENT ‘图片消息媒体id,可以调用多媒体文件下载接口拉取数据’,
voice_Format varchar(100) DEFAULT NULL COMMENT '语音格式,如amr,speex等 ',
ThumbMediaId varchar(100) DEFAULT NULL COMMENT ‘视频消息缩略图的媒体id,可以调用多媒体文件下载接口拉取数据。’,
Location_X varchar(100) DEFAULT NULL,
Location_Y varchar(100) DEFAULT NULL,
Scale varchar(100) DEFAULT NULL COMMENT '地图缩放大小 ',
link_Label varchar(500) DEFAULT NULL COMMENT ‘地理位置信息’,
Title varchar(500) DEFAULT NULL COMMENT ‘消息标题’,
Description text DEFAULT NULL COMMENT ‘消息描述’,
Url varchar(500) DEFAULT NULL COMMENT ‘消息链接’,
create_time datetime DEFAULT NULL COMMENT ‘消息创建时间’,
PRIMARY KEY (msg_id),
KEY i_t_msg_content (Content(383)) BLOCK_SIZE 16384 LOCAL,
KEY i_t_msg_create_time (create_time) BLOCK_SIZE 16384 LOCAL,
KEY i_t_msg_fromuser (FromUserName) BLOCK_SIZE 16384 LOCAL
) ORGANIZATION INDEX DEFAULT CHARSET = gbk ROW_FORMAT = DYNAMIC COMPRESSION = ‘zstd_1.3.8’ REPLICA_NUM = 3 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE ENABLE_MACRO_BLOCK_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0 COMMENT = ‘接收到的微信消息’
请教问题在哪里,谢谢!!!
2 个赞
辞霜
#3
每次执行 SELECT COUNT(*) FROM t_msg都是一样的耗时么。
可以使用obdiag 收集一下sql信息
SQL性能问题, 此处env中的trace_id对应gv$ob_sql_audit的trace_id
obdiag gather scene run --scene=observer.perf_sql --env “{db_connect=’-hxx -Pxx -uxx -pxx -Dxx’, trace_id=‘xx’}”
每次都是这个执行时间。
我安装了obdiag,执行
obdiag gather scene run --scene=observer.perf_sql --env “{trace_id=‘YB42AC11AC54-00063C5082F2D4DB-0-0’}”
log文件如下:
sql_result.zip (225.7 KB)
但界面上看,貌似有报错:
[ERROR] __execute_code_task_one Exception : expected string or bytes-like object
Gather scene results stored in this directory: /data1/obdiag_gather_pack_20250828112507
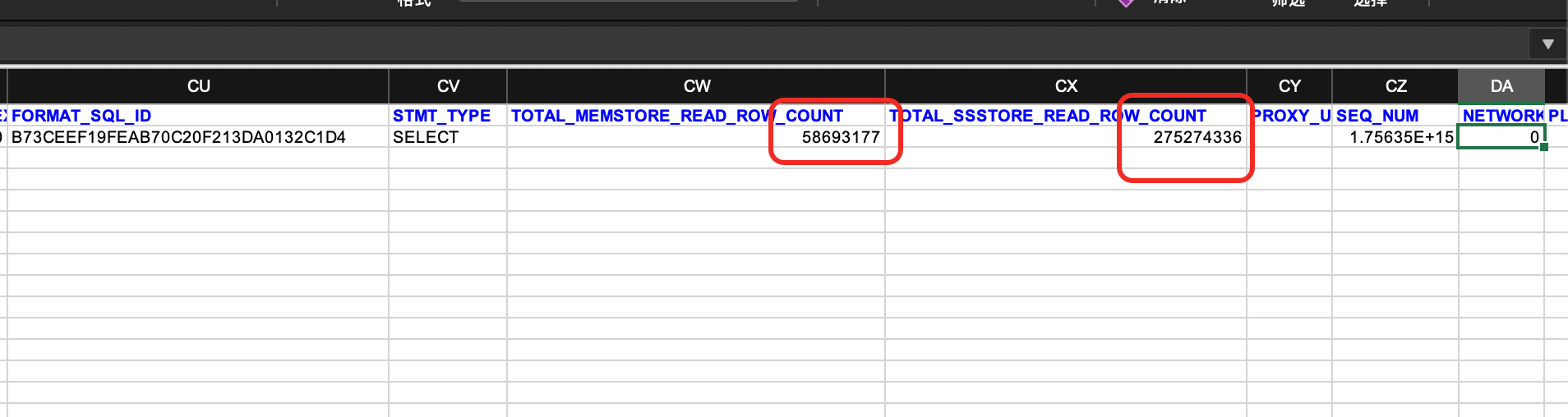
是gv$ob_sql_audit对应的这一行记录吧?
我导出来放到excel里面了
sql_audit.zip (10.5 KB)
来轩
#10
你可以对比一下COUNT快的表,MEMSTORE和SSTORE的数据量应该是很小的,这个合并一下,合并完成之后count(*)就会非常的快了
1 个赞
表数据是一直在写,但是速度快的表也是一直在写的。
请问您说合并一下如何做? 有指令吗 谢谢!
来轩
#12
你表的数据量目前多少,从SQL_AUDIT中看到要从SSTORE扫描2亿的数据,MEMSTORE扫描几千万的数据,我说的合并是指把租户做下合并,如果是生产环境,不要轻易的做合并,因为比较消耗数据库的资源,另外描述一下你这个表的业务场景,是否每天都要做大量的DML操作,比如插入数据,删除数据,从你上面的描述这个表只有几百万的数据,但是从SQL_AUDIT中的信息看,这个表的数据不至几百万的量
1 个赞
刚执行的:
SELECT COUNT(*) FROM t_msg
结果
5,775,608
耗时9秒
SELECT COUNT(*) FROM t_order_file;
结果
12,037,802
耗时0.099秒
来轩
#14
插入数据、更新数据没有什么问题,看下这个表是否一直在删除数据,然后再插入数据
来轩
#16
explain extended SELECT COUNT(*) FROM t_msg; 发下执行计划
Query Plan
|ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)|
|0 |SCALAR GROUP BY | |1 |119970 |
|1 |└─TABLE FULL SCAN|t_msg(i_t_msg_content)|5775726 |15290 |
Outputs & filters:
0 - output([T_FUN_COUNT_SUM(T_FUN_COUNT()(0x7fbf9e425580))(0x7fbf9e4f7f40)]), filter(nil), rowset=256
group(nil), agg_func([T_FUN_COUNT_SUM(T_FUN_COUNT()(0x7fbf9e425580))(0x7fbf9e4f7f40)])
1 - output([T_FUN_COUNT()(0x7fbf9e425580)]), filter(nil), rowset=256
access(nil), partitions(p0)
is_index_back=false, is_global_index=false,
range_key([t_msg.__substr383_20(0x7fbf9e4c71e0)], [t_msg.msg_id(0x7fbf9e429960)]), range(MIN,MIN ; MAX,MAX)always true,
pushdown_aggregation([T_FUN_COUNT()(0x7fbf9e425580)])
Used Hint:
/*+
*/
Qb name trace:
stmt_id:0, stmt_type:T_EXPLAIN
stmt_id:1, SEL$1
Outline Data:
/*+
BEGIN_OUTLINE_DATA
INDEX(@“SEL$1” “weixin_maintain”.“t_msg”@“SEL$1” “i_t_msg_content”)
OPTIMIZER_FEATURES_ENABLE(‘4.3.5.3’)
END_OUTLINE_DATA
*/
Optimization Info:
t_msg:
table_rows:6147320
physical_range_rows:5775726
logical_range_rows:5775726
index_back_rows:0
output_rows:5775726
table_dop:1
dop_method:Table DOP
avaiable_index_name:[i_t_msg_content, i_t_msg_create_time, i_t_msg_fromuser, t_msg]
stats info:[version=2025-08-14 16:14:12.808131, is_locked=0, is_expired=0]
dynamic sampling level:0
estimation method:[OPTIMIZER STATISTICS, STORAGE]
Plan Type:
LOCAL
Note:
Degree of Parallelisim is 1 because of table property
来轩
#18
手动收集一下表统计信息
CALL dbms_stats.gather_table_stats(‘用户名称’,‘表名’,granularity=>‘GLOBAL’,degree=>‘16’,method_opt=>‘FOR ALL COLUMNS SIZE AUTO’);
查询:CALL dbms_stats.gather_table_stats(‘weixin_maintain’, ‘t_msg’, granularity=>‘GLOBAL’, method_opt=>‘FOR ALL COLUMNS SIZE AUTO’)
错误代码: 4012
Timeout
执行耗时 : 0 sec
传送时间 : 0 sec
总耗时 : 27.414 sec
执行了好几次,都是报超时,这个是改哪个参数加大超时时间?
来轩
#21
set ob_query_timeout=3600000000;