《OceanBase资深DBA进阶培训》第一期精彩回顾,视频回放、PPT及配套习题已同步上线,快来检验你的学习成果吧!
课程回放直达
课后练习挑战
小贴士:观看完课程内容后,再进行练习,效果更佳哦!
作者:武乃辉,花名:@刘彻 ,OceanBase 开源团队数据迁移技术负责人。
他是 OceanBase 团队中,在阿里巴巴和蚂蚁集团工作时间最久、资历最深的大佬(比 OceanBase 数据库的创始人、CEO、CTO、XO、EMO……的资历都要更深)。
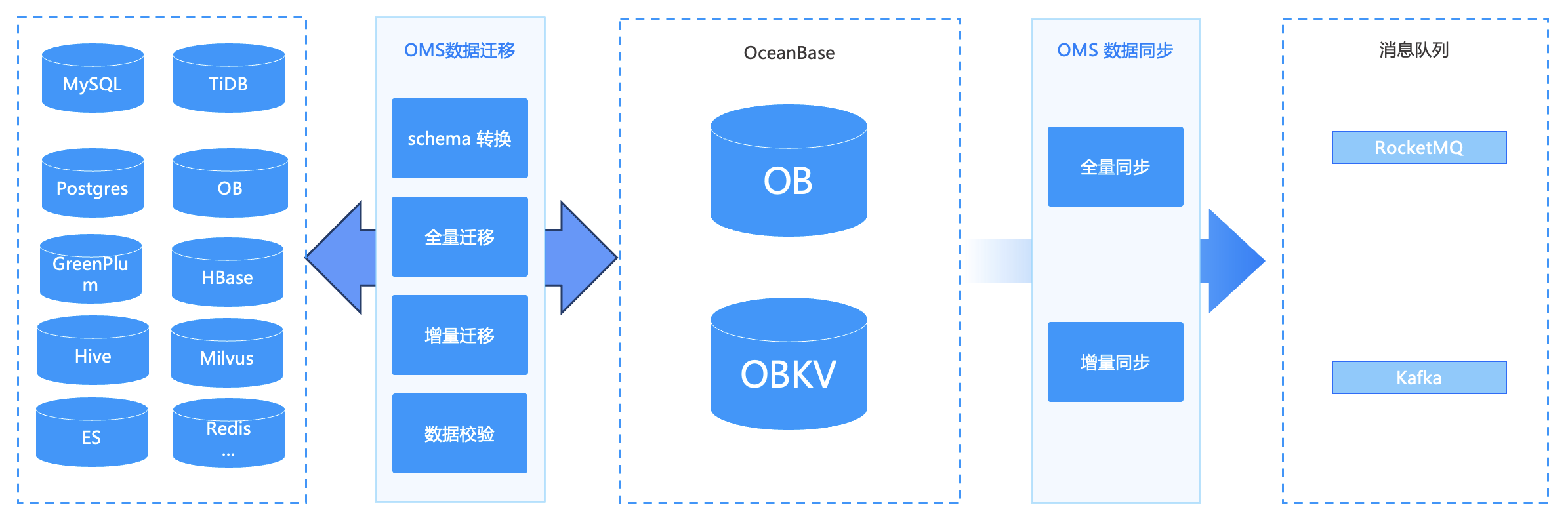
OMS (OceanBase Migration Service) 是 OceanBase 提供的一站式数据传输服务,主要解决异构数据库如何将数据迁移到 OceanBase 中,以及 OceanBase 和 OceanBase 之间数据迁移的问题。
同时,OMS 也具备异地容灾能力、数据库版本升级能力、实时计算能力。迁移到 OceanBase 的数据,可以使用 OMS 将这些数据发送到下游的消息队列,供实时计算平台(如 Flink)从消息队列中订阅增量数据。
目前 OMS 已经支持多种异构数据库,例如常见的 MySQL、TiDB、PostgreSQL、GreenPlum,KV 场景的 HBase、Redis,大数据场景的 Hive 以及近两年讨论度极高的向量数据库 Milvus,都支持直接迁移到 OceanBase。
OMS 主要提供 Schema 转换、全量迁移、增量迁移、数据校验四个能力。
Schema 转换即为结构迁移,例如将 MySQL 的一张表迁移到 OceanBase 之前,需要在目标端创建表结构,使用 OMS 不需要用户手动创建表结构,OMS 可以直接实现表结构的转换迁移。
全量迁移即将源端的存量数据迁移到 OceanBase,相当于数据初始化。在业务不停写的情况下,全量迁移过程必然会产生增量数据,因此也需要实现增量数据迁移。在数据迁移完成后,需要进行数据校验,保证源端数据和目标端数据基本上一致。因此 OMS 在数据迁移过程中主要提供了数据结构迁移、数据迁移、数据校验三大功能。
OMS 数据迁移的流程如下图所示:
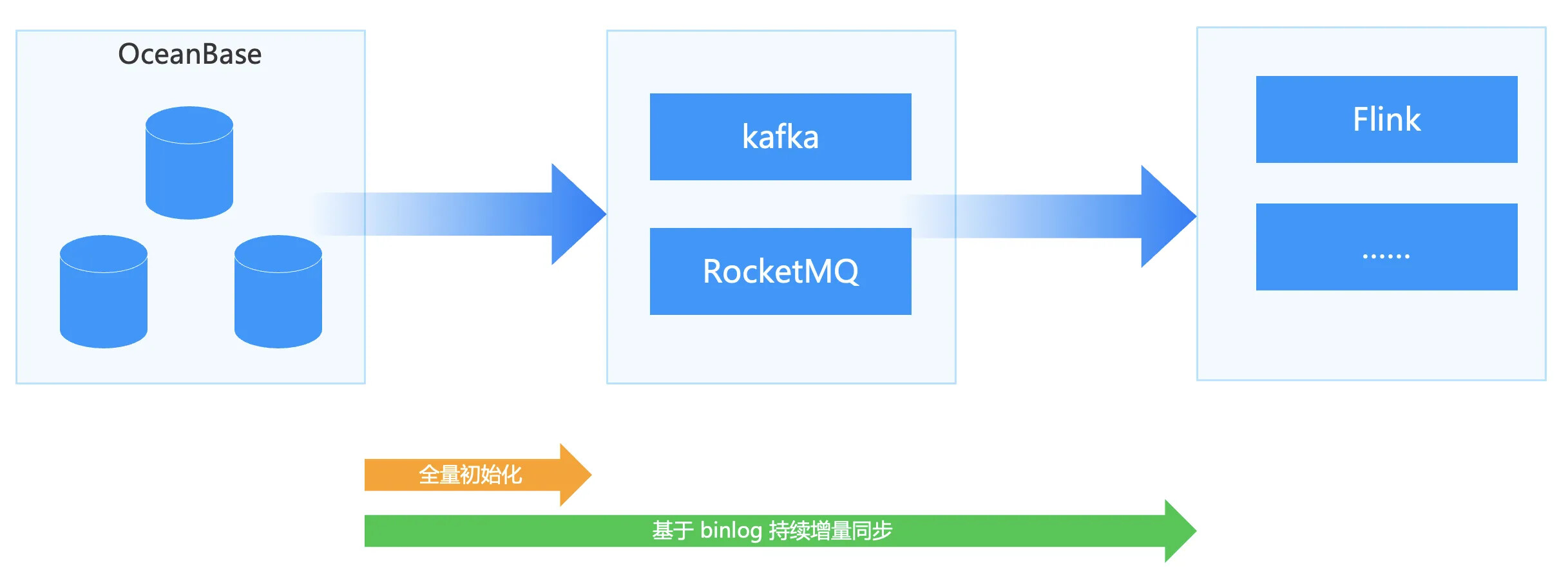
OMS 数据同步指将 OceanBase 的数据同步迁移到消息队列如 kafka、RocketMQ,提供给下游的实时计算平台使用。例如用 Flink 订阅 kafka 数据完成实时计算业务。
OMS 数据同步支持全量初始化,例如可以将 OceanBase 的某一张表全量同步到消息队列中,也可以选择不全量同步。其次 OMS 支持持续增量同步,增量同步主要基于 OceanBase 的 Clog 即 binlog 的持续增量同步。
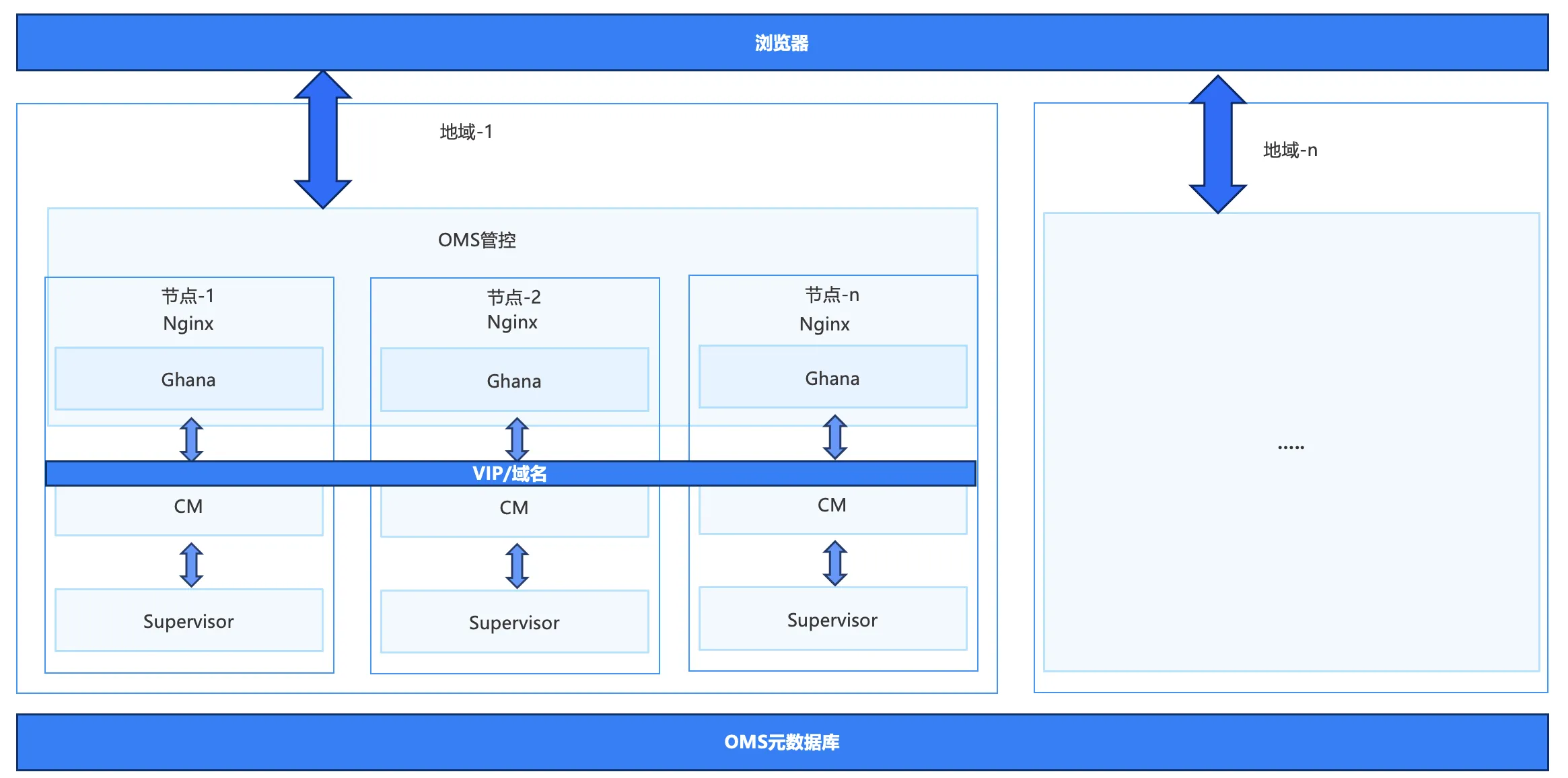
OMS 提供了可视化的集中管控平台,用户可以通过浏览器访问 OMS 进行管控。在部署类型上,OMS 支持单节点部署、单地域多节点部署、多地域多节点部署等多种部署方式。可以通过部署多个节点实现在迁移任务中的容灾备份。多地域部署是为了在源库和目标库不在同一个机房的场景下,让数据同步时,store 组件启动在源端机房,增同步组件启动在目标机房。
同时,OMS 本身也提供了 HA 高可用能力,当 OMS 部署服务器发生单点故障或个别任务进程发生异常时,HA 能够及时发现、介入并尝试恢复。
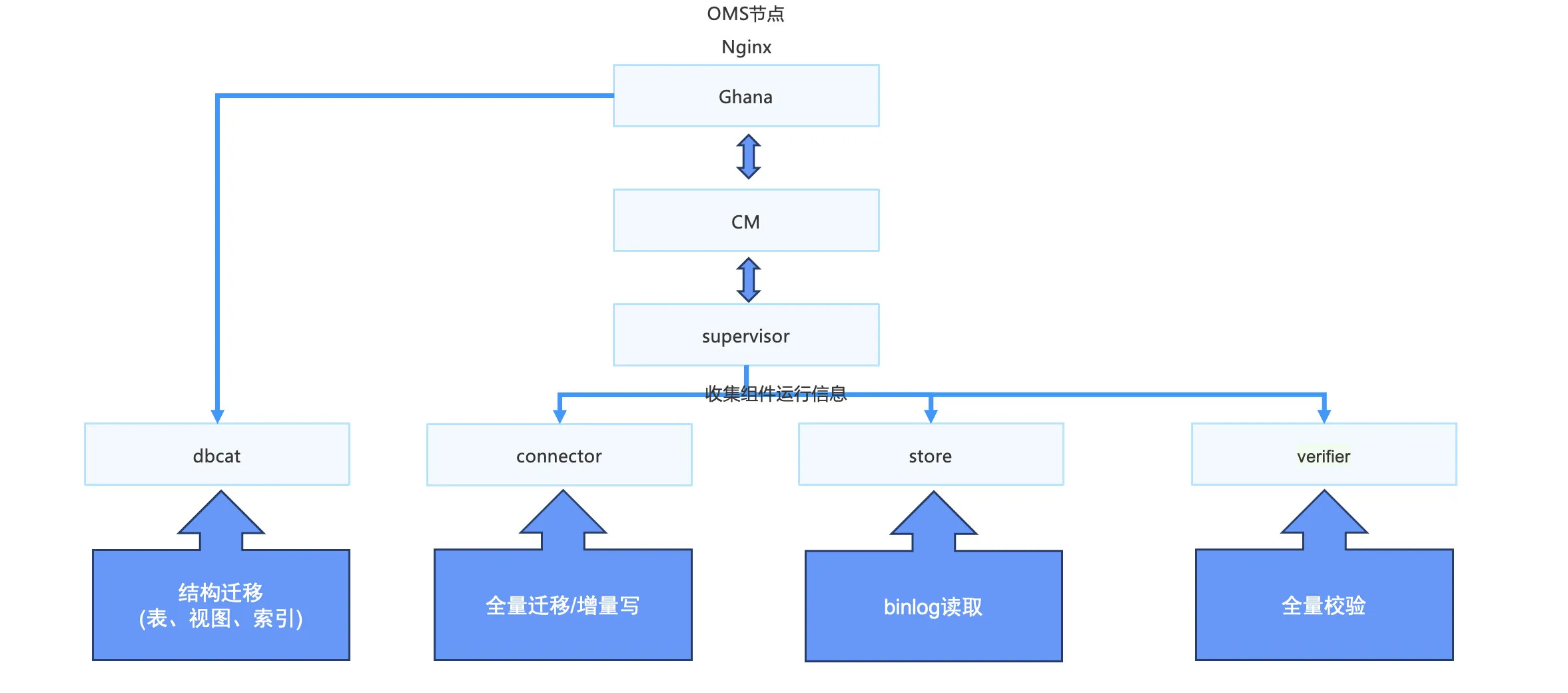
OMS 具体迁移同步过程中使用的组件包含:
最后,无论是多地域部署还是多节点部署,OMS 元数据库只能有一个。
上文已经具体介绍了各个组件的功能,下文介绍一下各个组件之间的关系。
首先 Ghana 调用 DBCat 映射到 OMS 进行结构迁移,在创建以及链路运行中,Ghana 会请求 CM,CM 最终调用 Supervisor 组件启动链路所需要的组件,同时 Supervisor 定时像 CM 汇报组件运行状态信息。Supervisor 可以调用的组件包括 binlog 拉取组件 Store、全/增量同步组件connector、全量校验组件 Verifier 等。
OMS 适用的典型场景有单向迁移、双向双活、全量数据迁移、增量数据同步、全量校验等。
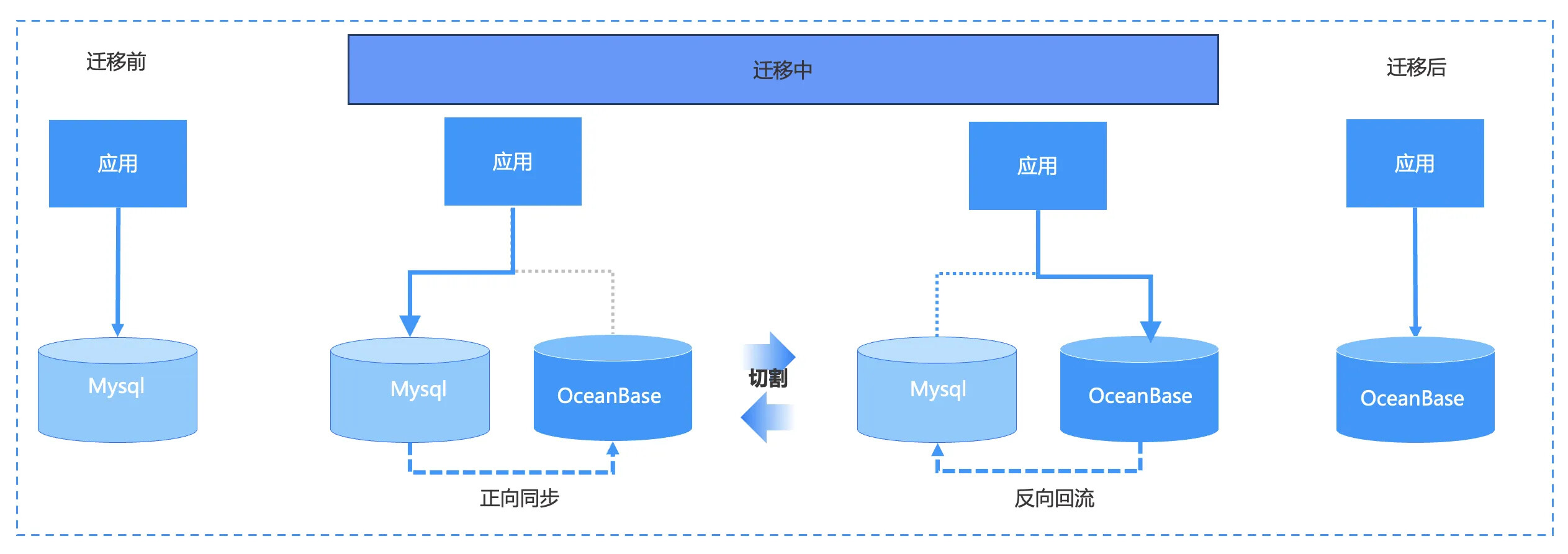
如果要将 MySQL 数据迁移到 OceanBase,迁移前,应用连接的数据库是 MySQL,需要使用 OMS 建立一条链路把 MySQL 的数据迁移到 OceanBase,在完成数据迁移、数据校验后,用户进行数据库割接,割接之后应用连接的数据库就切换到了 OceanBase。此时在 OMS 中启动反向链路,应用新增的数据会通过反向链路流向 MySQL。
当 OMS 在数据迁移或者割接过程中出现问题,用户可以直接进行回滚。因为新增到 OceanBase 的数据也通过反向链路流向了 MySQL,过程中数据不会出现丢失。
最后当应用访问比较稳定时,可以收回 MySQL 的对应资源并将 OMS 的反向链路停止。完成迁移后,最终应用可以直接仅使用 OceanBase,OMS 的链路也可以同时停止。
首先前置条件是表必须有 PK 或 UK。迁移的关键流程为:结构迁移结束后,需要启动全量存量数据拉取。但在启动存量拉取之前,需要启动 Store 组件,保证从拉取的数据位点开始,新的变更数据已经存放在 Store,此时再启动全量 connector 开始拉取全量数据。待全量数据拉取完成后,再启动一个 connector 增量。由于 Store 在全量迁移前已经启动,增量数据实际上是在 Store 中消费数据,因此此时只要 connector 的数据实时同步后,最终目标端数据会和原表保持一致。
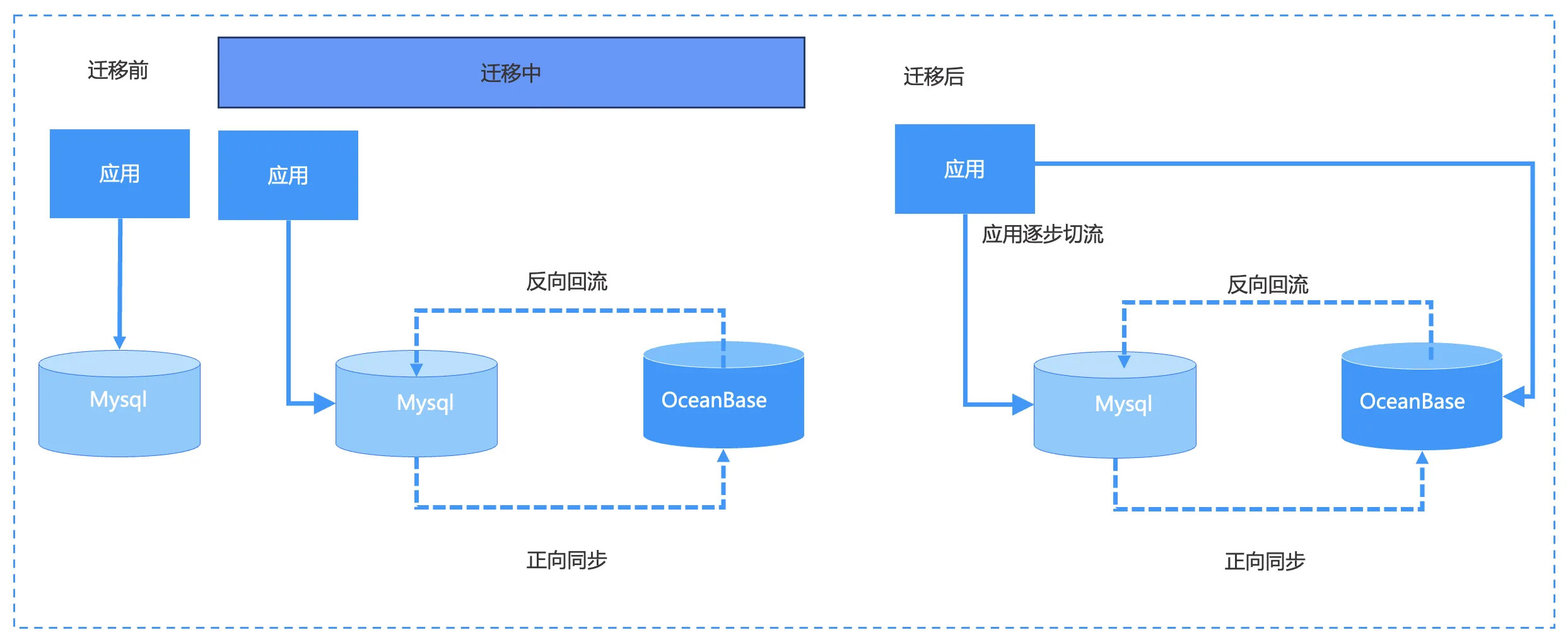
双向双活是 OMS 支持的又一典型场景。上文提到的单向迁移相当于直接从源端到目标端的单向数据复制,只有切换反向回流才会出现反向同步动作。双向同步和单向同步的区别是,在做完正向同步后,反向链路也会集中在一起,相当于形成了一个完整的数据流通闭环链路。其中需要注意的和单向迁移的一点区别是,需要防止 OMS 的回环复制。
那么双向双活场景主要解决什么问题呢?应用在切换数据库的时候不是类似单向迁移的直接切换,而是会对数据进行灰度同步,例如对用户数据按照百分比进行切流的过程。当数据逐步切流到最终百分之百切到 OceanBase 后,迁移链路可以切断,也可以根据实际需求不切断。
在数据双向迁移的链路中,OMS 在同步数据,同时应用也在写数据。如果不对这两部分数据进行区分,数据从 MySQL 到 OceanBase 后又会通过反向链路写回到 MySQL,造成数据有重复问题,因此我们需要实现防回环复制。防回环复制的关键是如何区分同步工具和应用写入的数据,即给这部分数据打标,OMS 实现了以下两个方案:
事务表方案(通用):
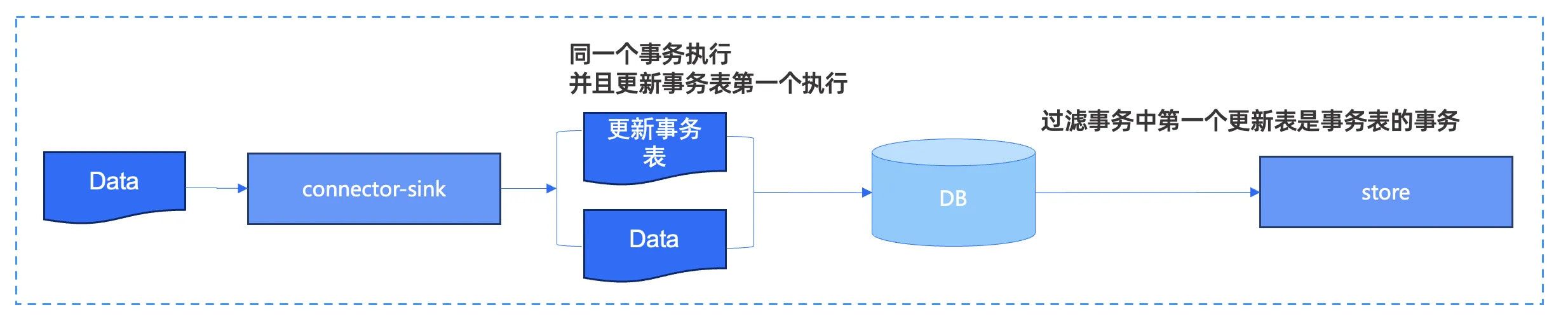
事物表方案是其中一个比较通用的方案。具体流程为:首先在 connector-sink,即在写入数据库时收到上游的增量数据后,在写入 DB 之前会创建一个事务,这个事务的第一条执行语句是会更新一个事务表,更新完事务表后才会去写真正的数据,这样做的目的是让这个事务的第一个表是事务表。下游在订阅 DB binlog 时会进行解析。如果发现事物表中第一个表是事务表就会过滤掉,最终可以识别出哪些是 OMS 写的,哪些是业务写的,即只要事务中第一个表不是事务表,则为业务写的。如果是事务表,则为 OMS 写的。
threadid 方案(仅使用 OceanBase)
第二个方案仅限于使用 OceanBase,在写 OceanBase 时设置一个 threadld,即在 OMS 中设置一个固定值。设好固定值后再开始写数据。对于 OceanBase 的 store 来说,会默认过滤的是来自 OceanBase 的 OMS 达标数据,可以实现防循环复制功能。
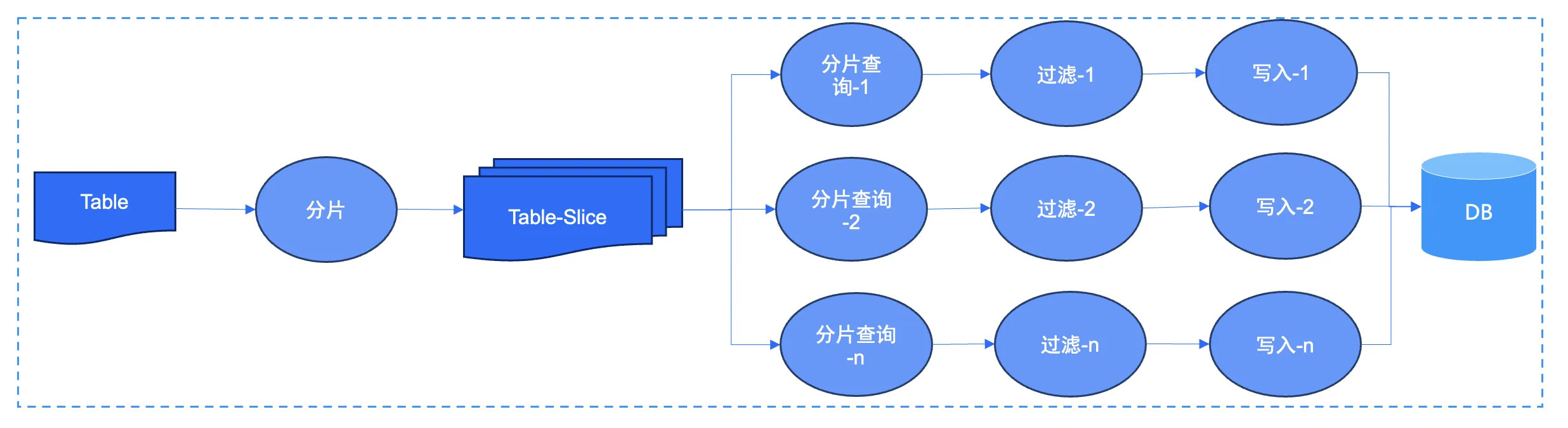
在实际迁移过程中通常会有一些比较大的表,如果整张表只发起一条链路处理会导致迁移速度非常慢,因此在对表进行迁移之前,OMS 的全量迁移组件 connector 会先对表使用 PK/UK 或者用户指定的索引进行分片。分片的目的是将表的数据分成若干小的数据段,后续即可形成并发链路。
分片原理:
select id from table_name where id > 上次分片_id order by id limit 1000 /* 分片大小 */, 1;
select id from table_name partition(pt2024) where id > 上次分片_id order by id limit 1000 /* 分片大小 */, 1;
对于没有 PK 或 UK 的用户,用户可以指定分片索引,默认不分片一次查询所有数据。
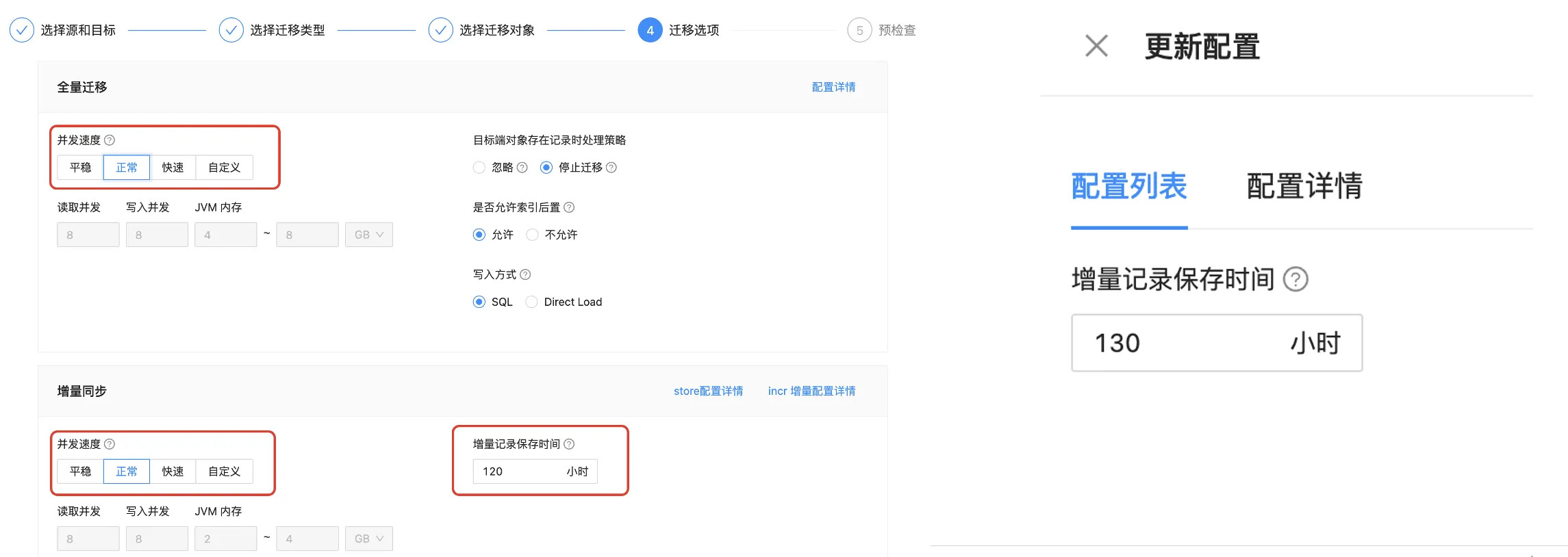
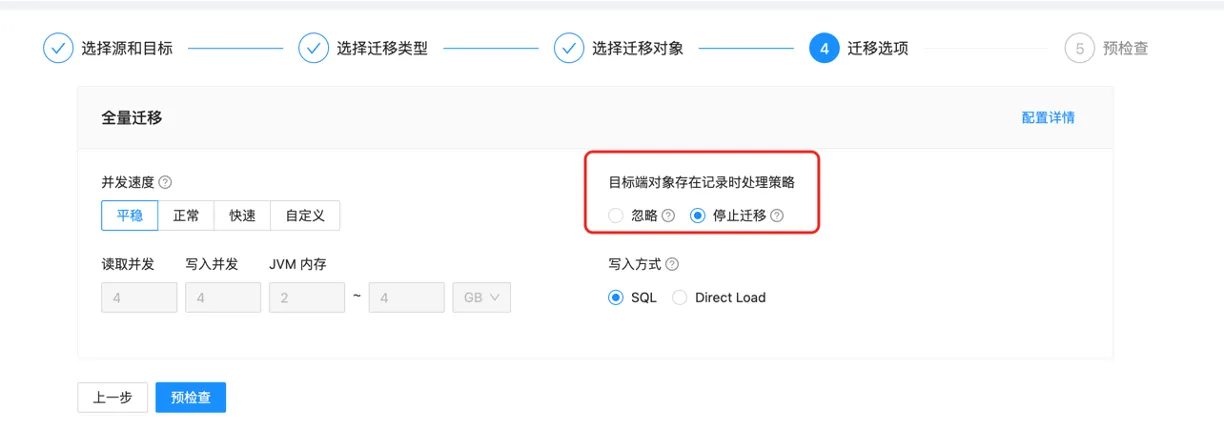
关于数据写入,除了常规的 SQL (通过 INSERT 或 REPLACE 写入表) 写入方式,OceanBase 还提供了特有的旁路导入方式(Direct Load)高效插入数据,其核心是通过绕过 SQL 解析层,直接在底层数据文件中分配空间并写入数据。OMS 迁移选项页面提供了相关入口,用户在创建链路时可以选择相应参数。
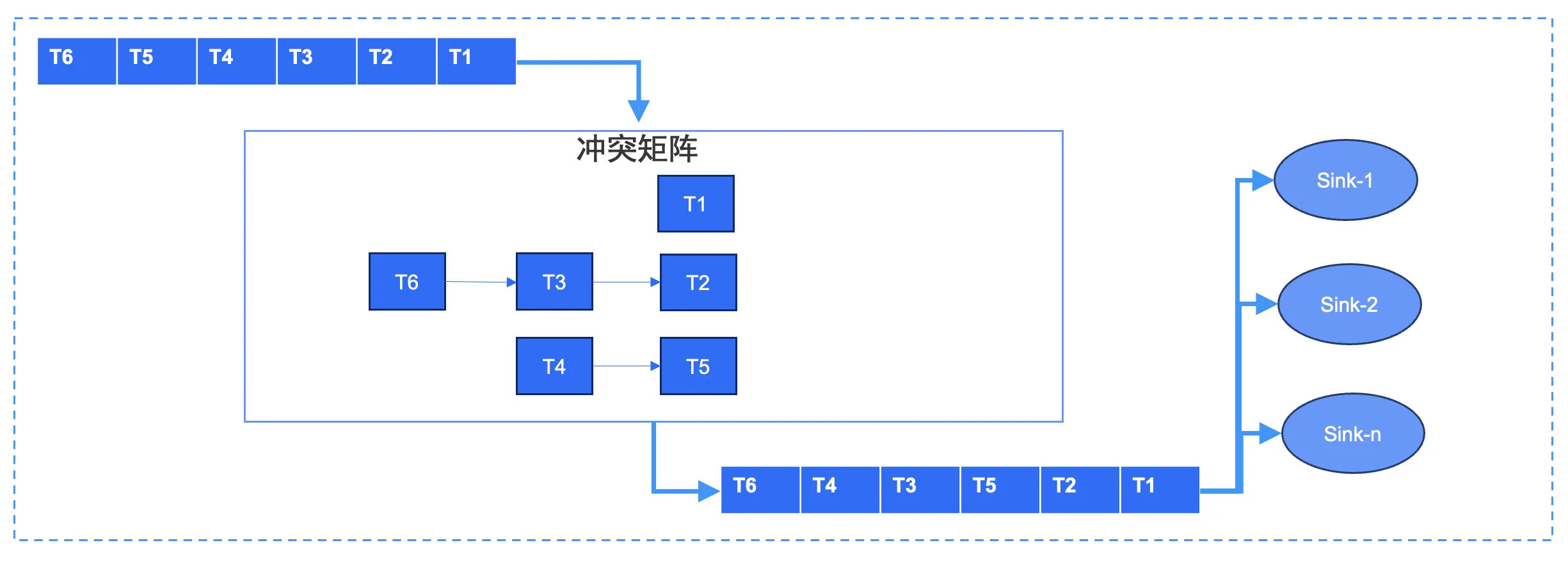
对于增量数据,由于增量数据通常是串行的无法并行,因此我们引入了冲突矩阵检测,对于不同 PK 且没有上下游关系的数据可以并行执行。增量数据的位点主要取可执行性事务中最小事务 commit 时间为安全位点,因此有时候会看到 OMS 页面上位点会有一定延迟,但实际查询数据时延迟并没有那么大。
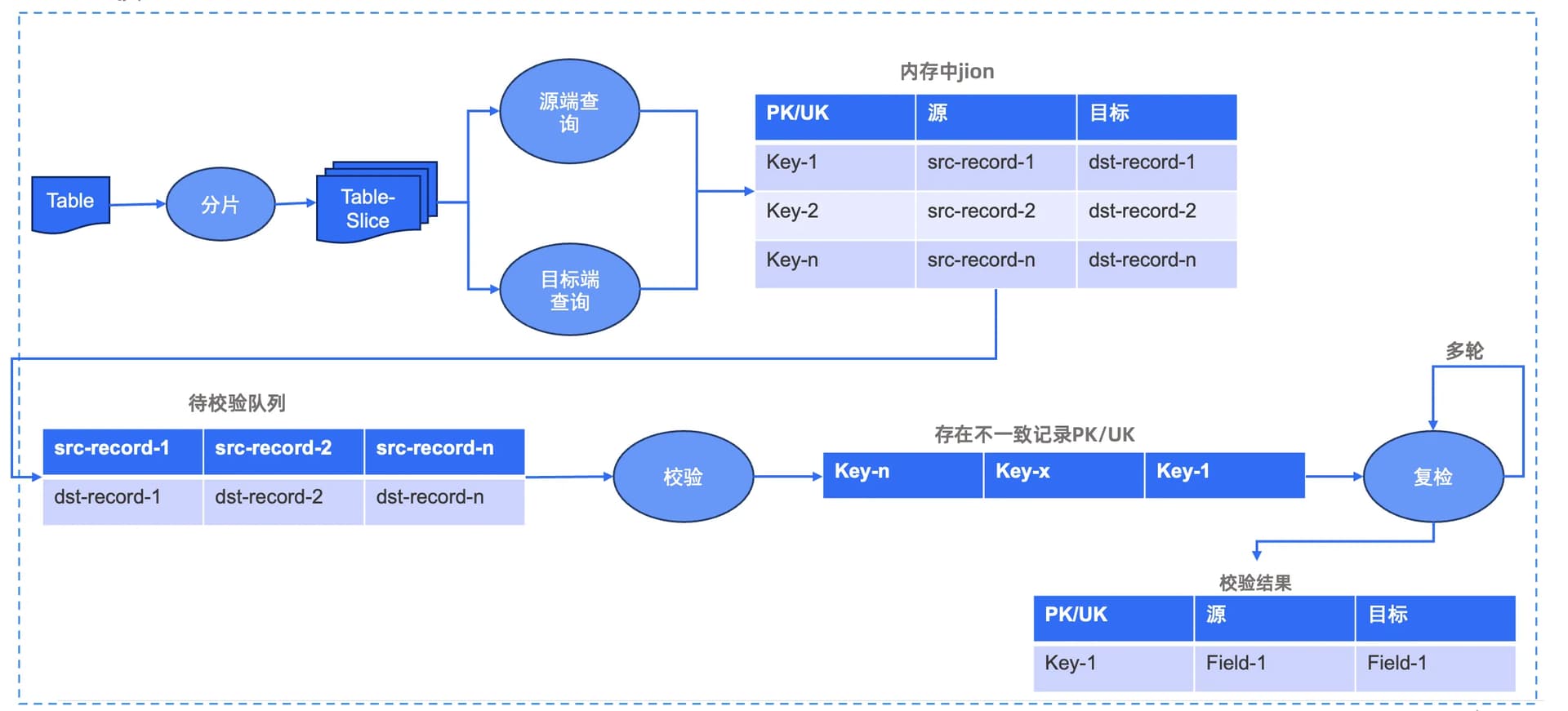
全量校验的初期和全量迁移一样有分片的动作,分好片后,会利用完成的分片分别在源端和目标端查询数据,将数据查询出来后,按照表的 PK 在内存中进行 JOIN 校验,完成后放到待校验队列中,然后校验模块会从校验队列中把源端和目标端的具体记录拿出来进行比对,并将比对不一致的记录的 PK 或 UK 值进行记录。
由于在校验过程中,增量数据还在运行,可能存在增量延迟等导致数据未写入到目标端,为了保证结果的准确性,需要进行多轮复检,其中复检次数用户可以使用参数对复检时间和次数进行配置。
最终复检完成后,针对不一致的数据会输出校验结果。由于全量校验会对每个字段值进行比对,因此可以在 OMS 页面看到具体校验结果,例如:某一个 PK 的源端和目标端的具体字段值、为什么比对不上、PK 值只在源端目标端没有、PK 值只在目标端源端没有等。
OMS 问题排查基本方法
在问题排查中,安装、配置和日志目录是比较关键的目录。
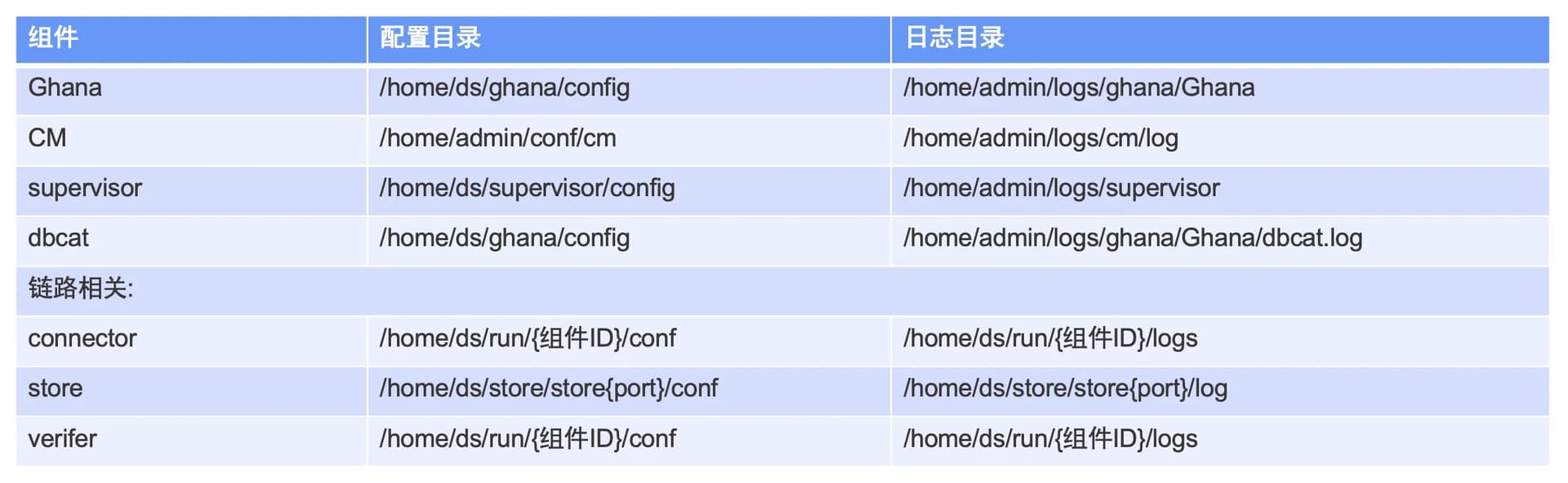
OMS 的安装配置文件目录为 /home/admin/conf/config.yaml,用于存放元数据配置以及 OMS 组件端口配置,包括 Ghanag、CM、Supervisor、dbcat 等,具体见下图。安装 OMS 时,组件日志目录会默认创建在 /home/admin/logs 目录下,分别对应不同组件名称。
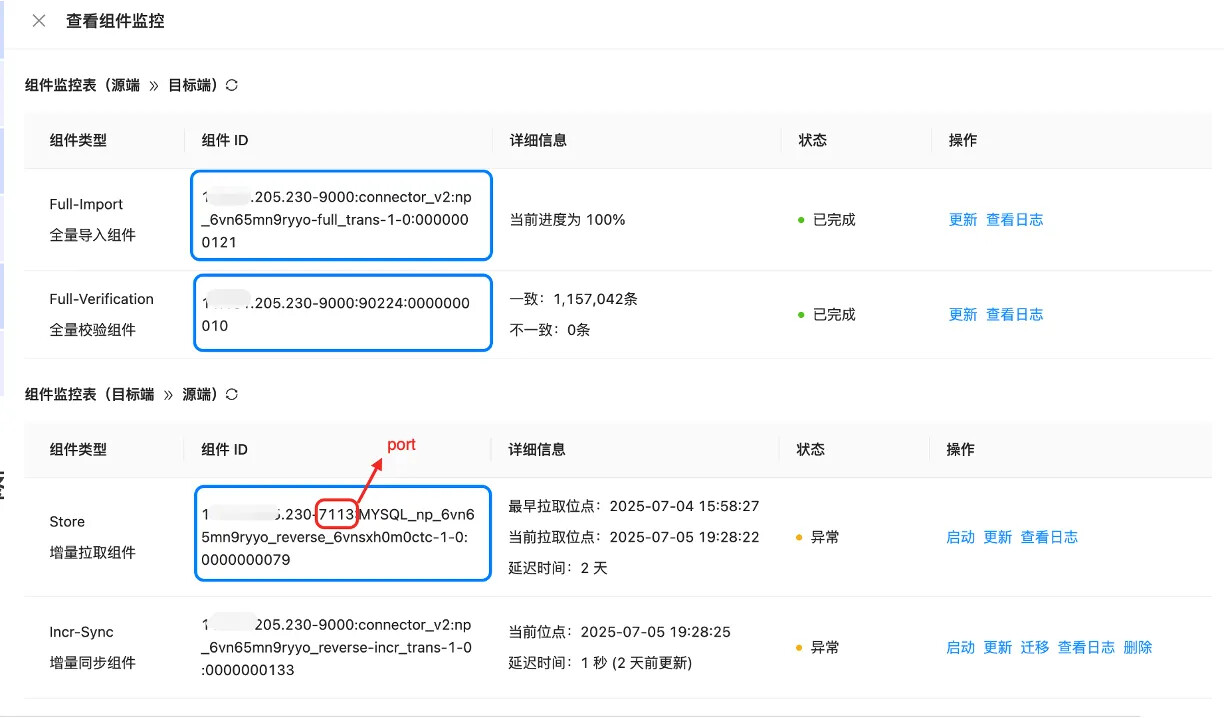
链路相关组件 connect、store 以及 verifer,其中 connect 和 verifer 是校验组件和全量增量组件,配置目录默认在 /home/ds/run/{组件ID} /conf 目录下,日志目录默认在 /home/ds/run/{组件ID} /logs 目录下。增量拉取组件 Store 的配置目录和日志目录中需要加端口即 {storeport},查找方式见下文。
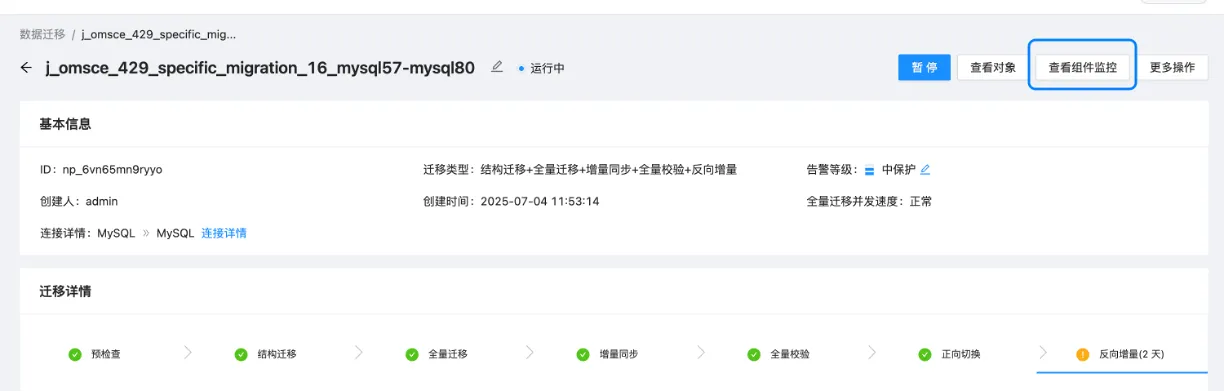
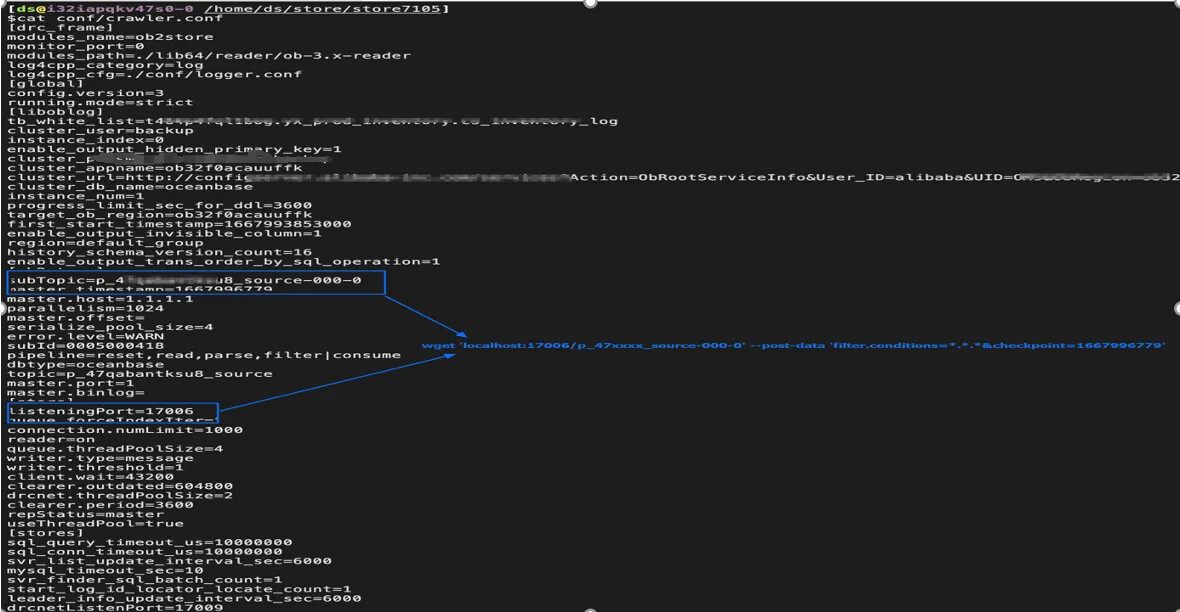
{组件ID} 和 {storeport} 的查找方式:如下图所示,{组件ID} 可以在 OMS页面-具体链路-查看组件监控-组件ID 列查看,包含全量组件 ID,校验组件 ID 及增量组件 ID,其中需要特别注意的是 {storeport} 和链路相关,在组件 ID 中的 IP 后,如下图红框所示。
Supervisor 服务是 Python 提供的服务,OMS 的组件状态通过 Supervisor 服务进行监控和控制,包括 Nginx、Ghana、CM、Supervisor、sshd,其中 Nginx 即浏览器访问的默认端口为8089、Ghana 默认端口为8090、CM 默认端口为8088、Supervisor 默认端口为9000、sshd 默认端口为2023。
supervisord 配置文件所在目录为 /etc/supervisor/conf.d,配置文件中可以找到用于启动组件的脚本,可以在脚本中调整 jvm 参数。
常用的OMS组件管理命令
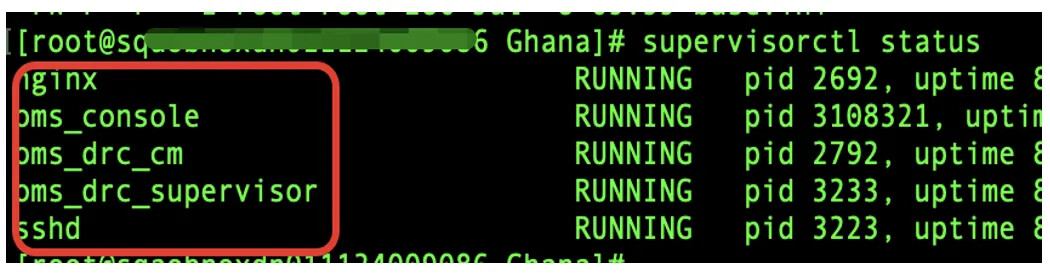
OMS 提供了一些常用命令查看组件状态,进入 OMS 容器后,可以直接通过 supervisorctl status 命令查看。如下图,正常情况下各个组件的状态为 RUNNING。
如果需要停止、启动或重启组件,直接运行 supervisorctl stop/组件名称、supervisorctl start/组件名称、supervisorctl restart/组件名称即可。
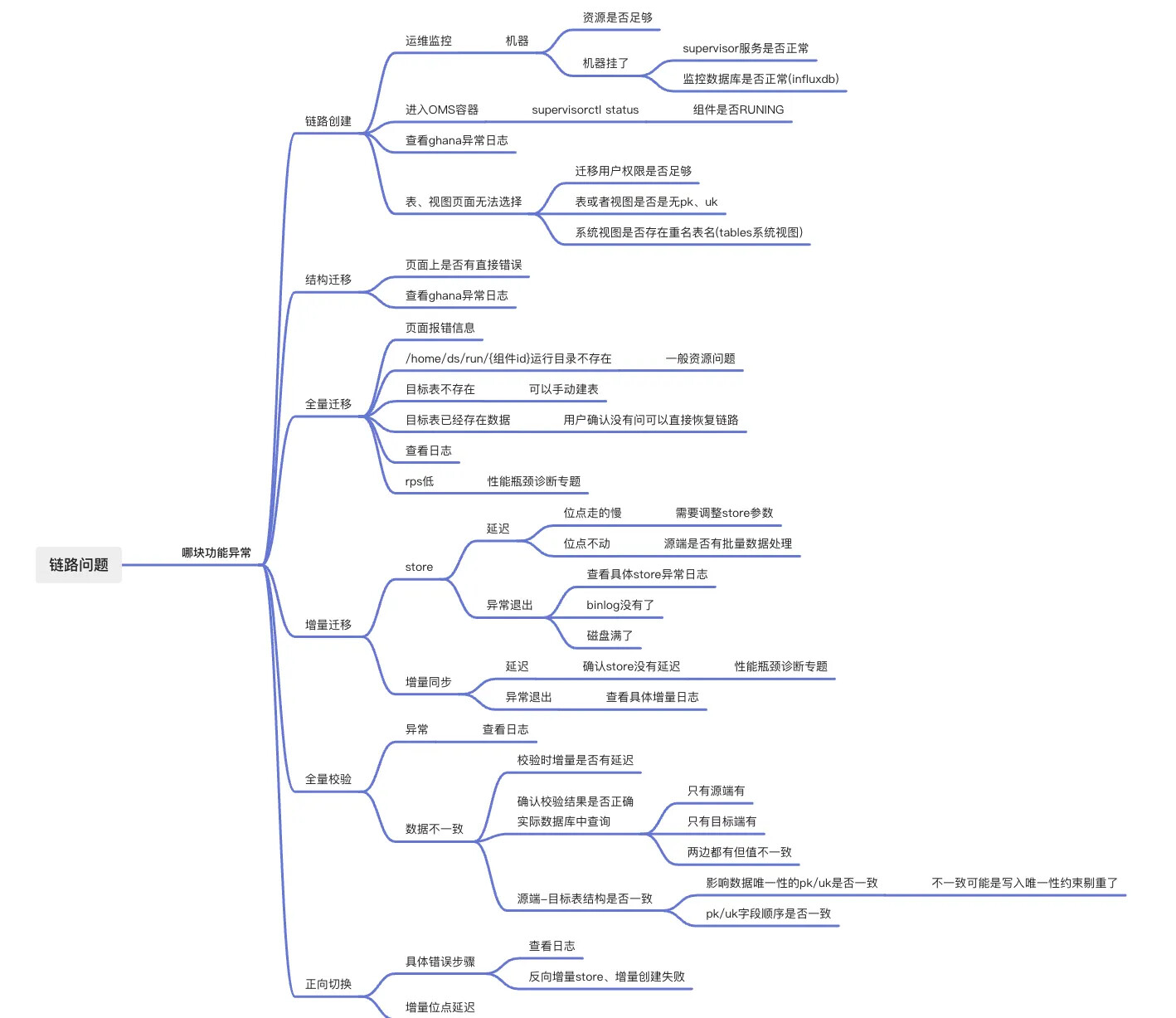
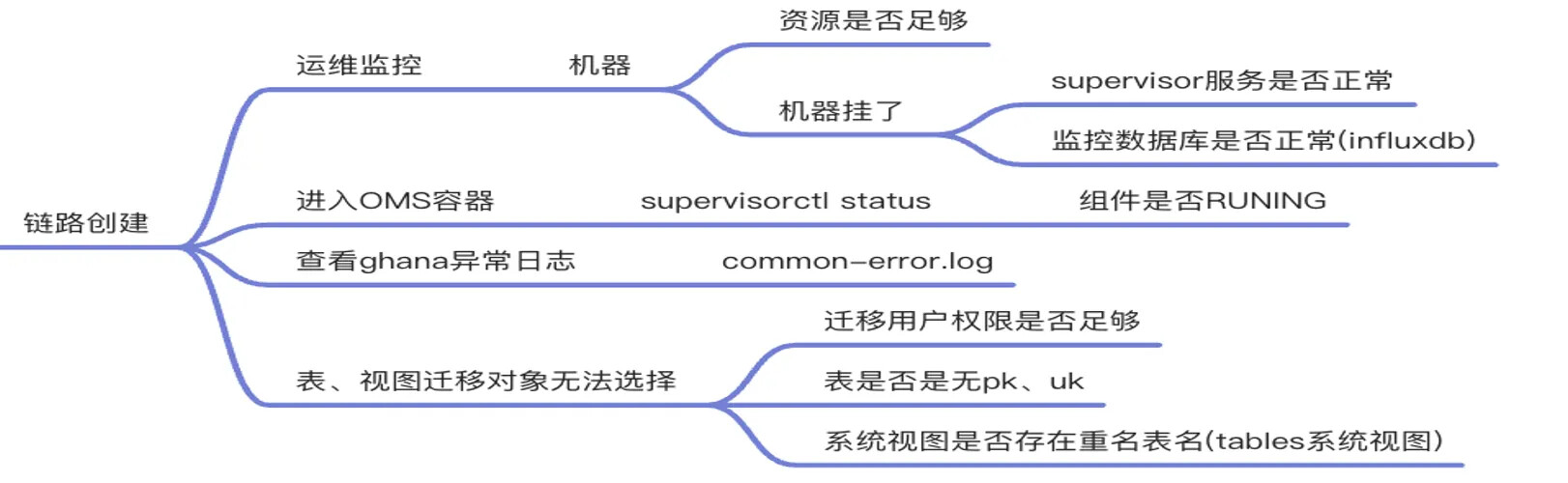
当 OMS 社区版数据迁移或数据同步任务发生报错时,官方提供了一个通用的排查思路,主要分为链路创建、结构迁移、全量迁移、增量迁移、全量校验、正向切换六大类。
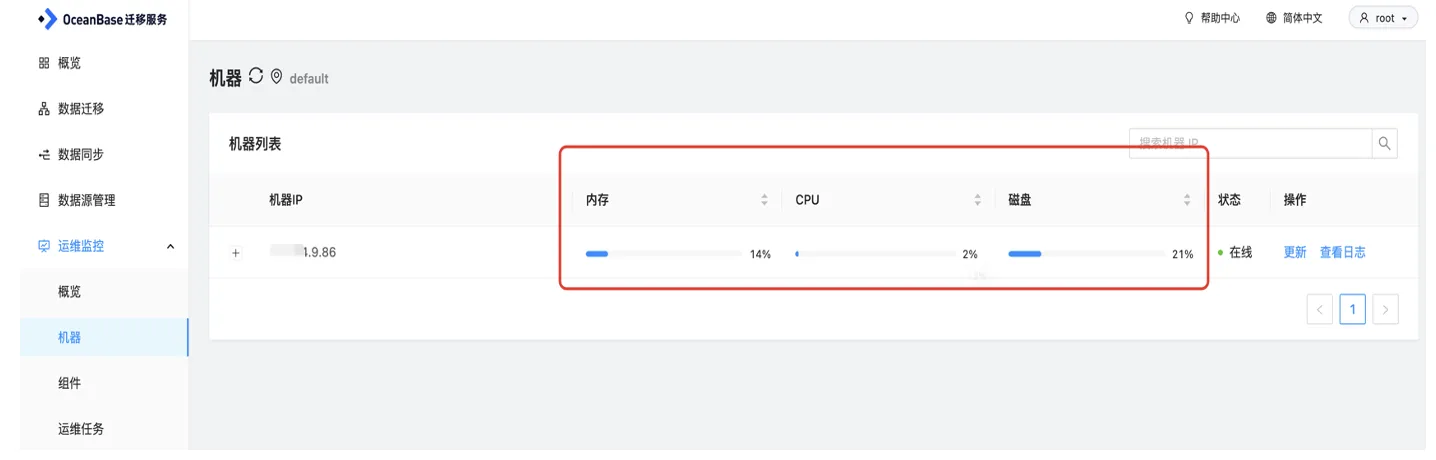
1、查看运维监控,可以进入运维监控页面-机器菜单下,查看机器资源是否充足、机器状态是否正常。
2、进入 OMS 容器,执行 supervisorctl status 命令,查看 OMS 组件服务状态是否都是 RUNNING 状态。
3、查看 ghana 异常日志,如 common-error.log 是否有明显报错。
4、表、视图页面迁移对象是否无法选择,创建链路的时候有时候会碰到选不到这个表,迁移的用户权限是否足够,表或视图是否没有 PK 和UK,系统视图是否存在重名表名(tables 系统视图)
结构迁移阶段如果出现报错,迁移页面上会出现告警提示,同时可以查看 ghana 异常日志中的 dbcat.log 和 common-error.log 查看具体报错。
如果在全量迁移阶段出现报错,
1、直接查看页面的异常报错信息。
2、其次进入组件目录/home/ds/run/{组件id},如果运行目录不存在,一般是资源问题,组件目录创建失败。
3、如果提示目标表不存在,可能原因是没有选择结构迁移,此时需要手动建表。
4、如果目标表已经存在数据,用户需要确认目标表是否有数据、数据是否正常,如果正常,可以直接恢复链路。
5、查看日志,查看组件运行目录下的日志报错。
6、如果 RPS 很低,全量迁移过程很慢,可以直接在 OceanBase 官网文档查看性能瓶颈诊断专题文档。
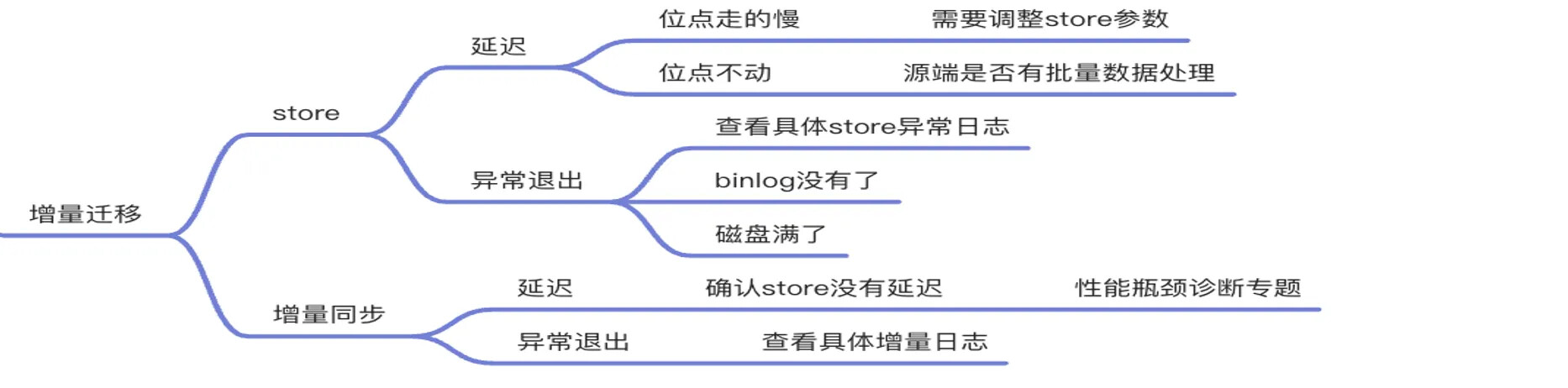
增量迁移阶段涉及 store 和 增量同步 两个组件。
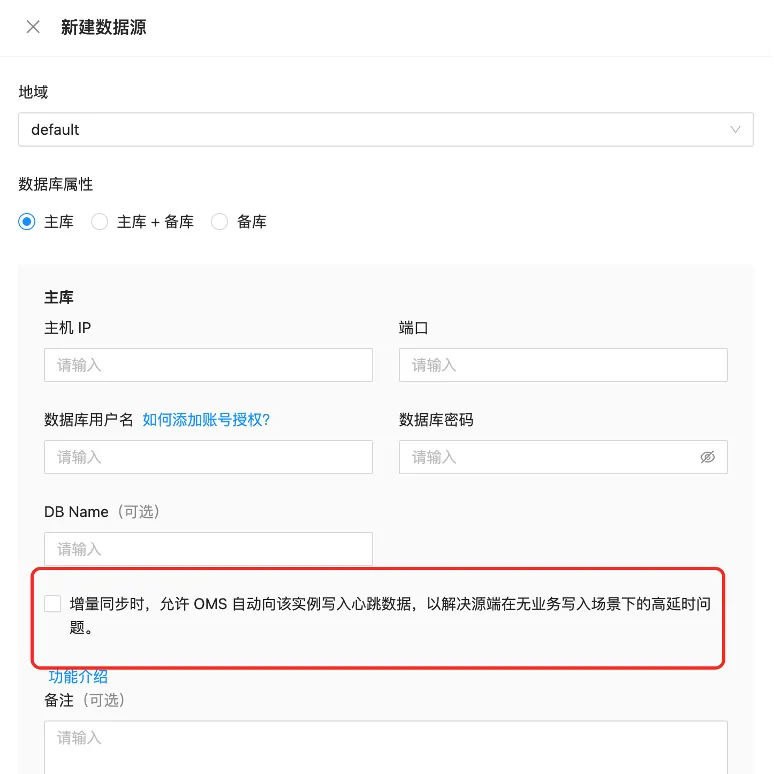
1、如果增量同步有延迟,首先查看 store 是否有延迟,如果位点走的慢,需要调整 store 参数。如果位点不动,需要看源端是否有批量数据处理,在源端没有数据更新的情况下,位点也是不动的。另外对于源端更新很慢的场景,可以在 OMS 新建链路-新建数据源时勾选心跳,则不会出现延迟问题。
2、如果 store 异常退出,首先需要查看 store 的异常日志,也可能是请求时间内binlog被删没有了或 OMS 磁盘满了,都可能会导致 store 异常退出。
3、对于增量同步的延迟,首先需要确认 store 是否延迟,,如果 store 没有延迟基本上可以确定为是性能瓶颈,此时可以在官网文档性能瓶颈诊断专题查看如何调整增量性能。
4、如果增量同步异常退出,需要看具体增量日志的异常退出日志。
全量校验阶段如果有异常首先直接查看日志。如果没有异常但数据不一致,可能有如下三种情况
1、首先要确定校验时增量是否有延迟,在增量有延迟的情况下,也可能导致数据不一致,此时可以待增量不延迟即数据位点追上了之后再进行全量校验。
2、需要确认校验结果是不是正确,需要根据不一致的结果到实际的源端数据库和目标端数据库手动查询,确认是否都有不一致的结果数据。一般有三种情况:只有源端有、只有目标端有、两边都有但部分字段不一致。
3、常见的数据不一致的情况是源端-目标端的表结构不一致,影响比较大的是 PK/UK 不一致,可能会导致迁移过程中有数据由于唯一性约束问题被剔重了。此外如果 PK/UK 数据字段的顺序不一致,也可能会导致校验不一致,原因是全量校验时是以源端查询出的分片范围进行查询,如果此时源端和目标端的 PK/UK 字段顺序不一样,会导致分片范围不一致,从而导致最终全量校验不一致。
当正向切换阶段发生报错时,由于正向切换涉及多个步骤,首先需要定位具体报错步骤,其次需要查看日志以及反向增量 store 和增量创建是否失败,如果增量创建失败,一般原因是资源不足。如果在正向切换过程中出现增量位点延迟,正向切换会卡住,因此需要保证在正向切换进行前源端的增量数据全部迁移到了目标端。
上述报错问题的通用排查思路在 OceanBase 官网文档《OMS 社区版问题排查手册》有详细说明,包含全量/增量迁移性能调优、metrics.log 分析、如何从 Store 中 dump 数据、典型使用场景和功能、多表汇聚、容灾双活等内容。文档地址:https://www.oceanbase.com/docs/community-oms-cn-1000000002947335
OMS 组件中的大多数性能问题都可以通过调整并发、JVM 内存、每个分片记录数解决。
源端和目标端都有 workerNum 参数用于调整源端读和目标端写的并发数,源端是 source.workerNum,目标端是 sink.workerNum。通常在全量迁移时,源端并发和目标端并发的设置相同,增量同步 Source 中无需设置。并发度和机器CPU核数量相关,最大可以设置为CPU*4,同时需要查看机器中是否存在其他迁移任务在执行。
可以调整 coordinator.connectorJvmParam 参数,主要调整 -Xms8g(初始内存)、-Xmx8g(最大内存)和 -Xmn4g(新增的内存),调整规则如下:初始内存=最大内存新增的内存 = 最大内存 - 4GB,通常一个并发对应 1GB 内存。例如,32 并发,最大内存设置 32GB。
可以调整 source.sliceBatchSize,默认值为 600。对于大表通常 10000 即可,如果设置太大会消耗内存较多。您可以根据 logs/msg/metrics.log 中的 slice_queue 决定是否需要修改。如果是0,则需要增加每个分片的记录数,原因是 Source Worker 线程会从 slice_queue 拉取分片,0 表示没有分片,Source Worker 便会等待空转。
OMS 常见问题以及解决方法。
OMS 安装阶段最常见的问题是端口被占用:
【问题描述】执行安装脚本:sh docker_remote_deploy.sh -o /data/xx -i xx.xx.xx.xx -d reg.docker.alibaba-inc.com/oceanbase/oms:feature_x.x.x_ce,输入配置参数最后报下图错误:
【问题原因】端口被占用,这里的端口指的是 OMS 依赖的组件 nginx/ghana/cm/supervisor/sshd。
【解决办法 1】找到占用端口进程直接 kill,可用 sudo netstat -nap | grep 9000 | grep LISTEN 找到占用端口 9000 的具体进程。
【解决办法 2】在部分可能有其他服务不能直接 kill 的情况下,在安装时,根据安装提示”是否自定义组件端口,并配置相关参数”修改 OMS 组件默认端口,输入 y 并给出各个组件的端口,即可自定义组件端口,解决端口被占用问题。
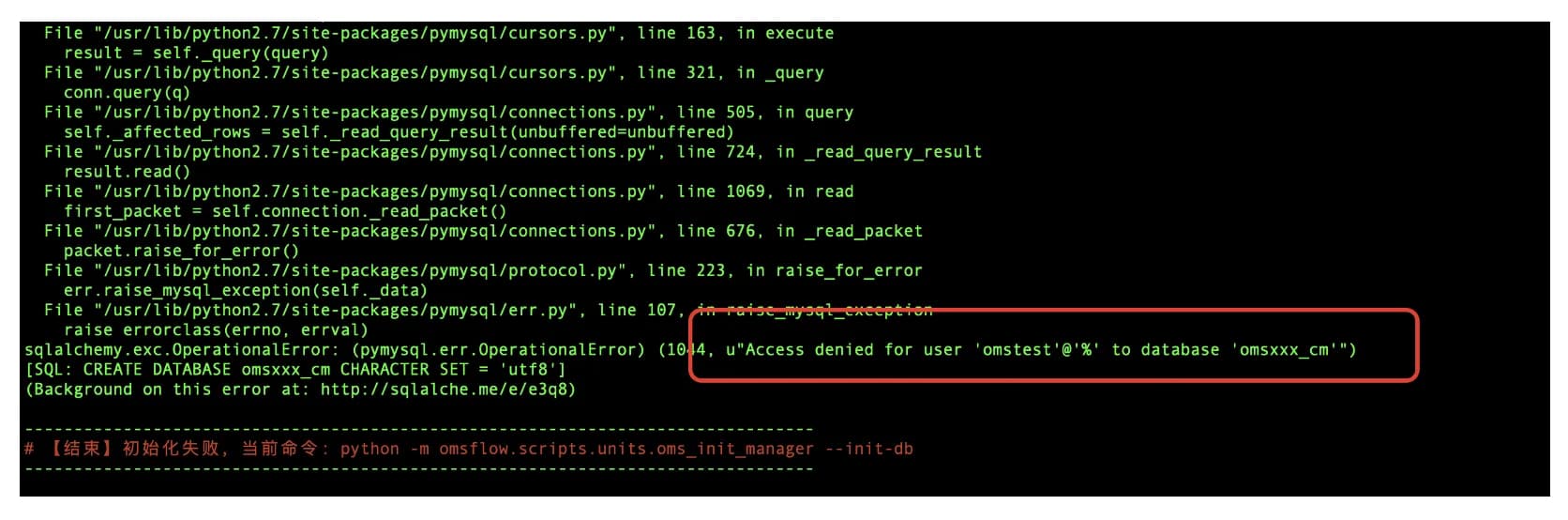
【问题描述】安装时最后执行初始化脚本阶段,OMS 社区版提供的元数据库用户权限不够,报错如下图:
【问题原因】用户需要用创建 db、表、增、删除、改表中数据权限。
【解决办法】元数据库用户在元数据库中进行授权。
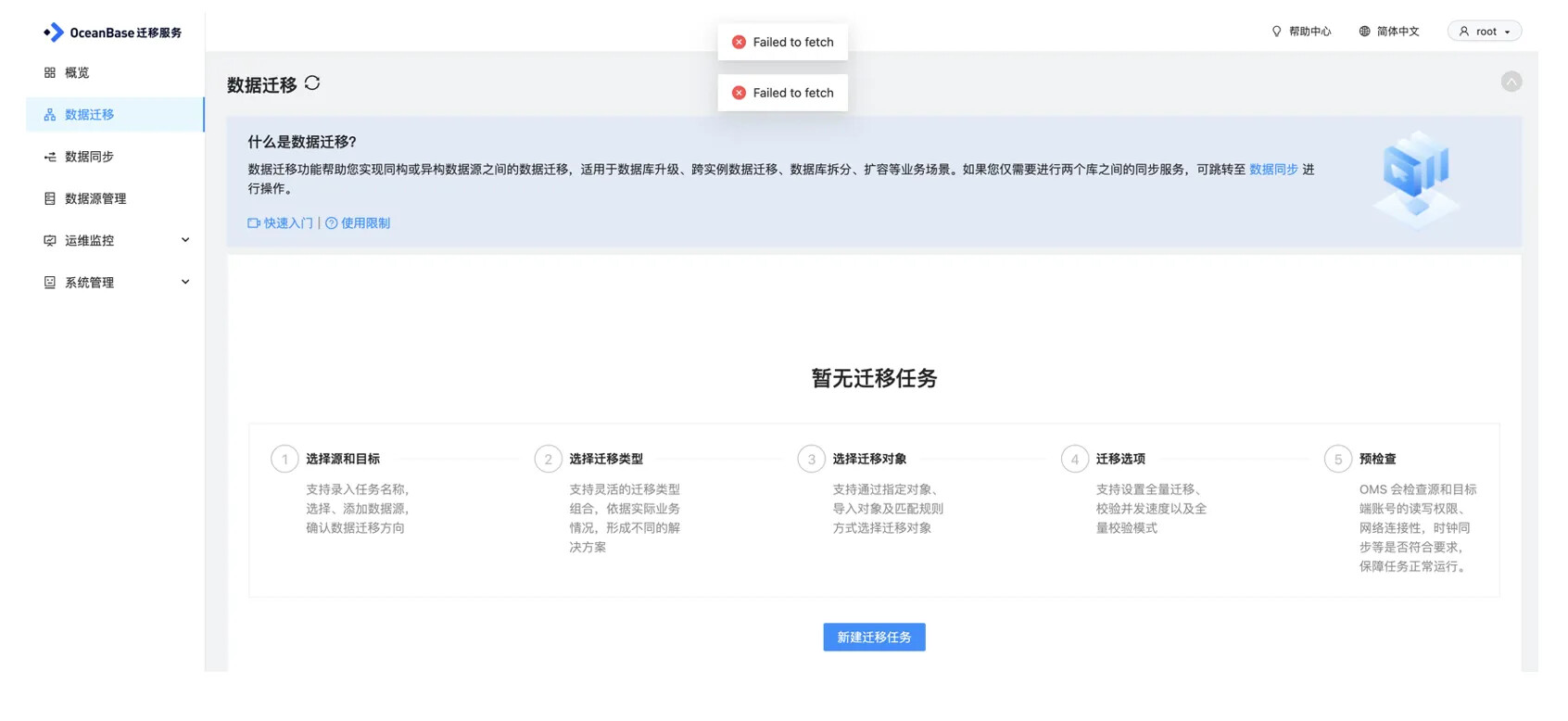
【问题描述】安装完成后,打开 OMS 页面,可能会弹出 failed to fetch。
【问题原因】查看是否启用快速回收机制。查看 tcp_tw_recycle 参数,1 表示开启,0 表示关闭。
【解决办法】
sysctl -a |grep tcp_tw_recycle
sysctl -w net.ipv4.tcp_tw_recycle=0
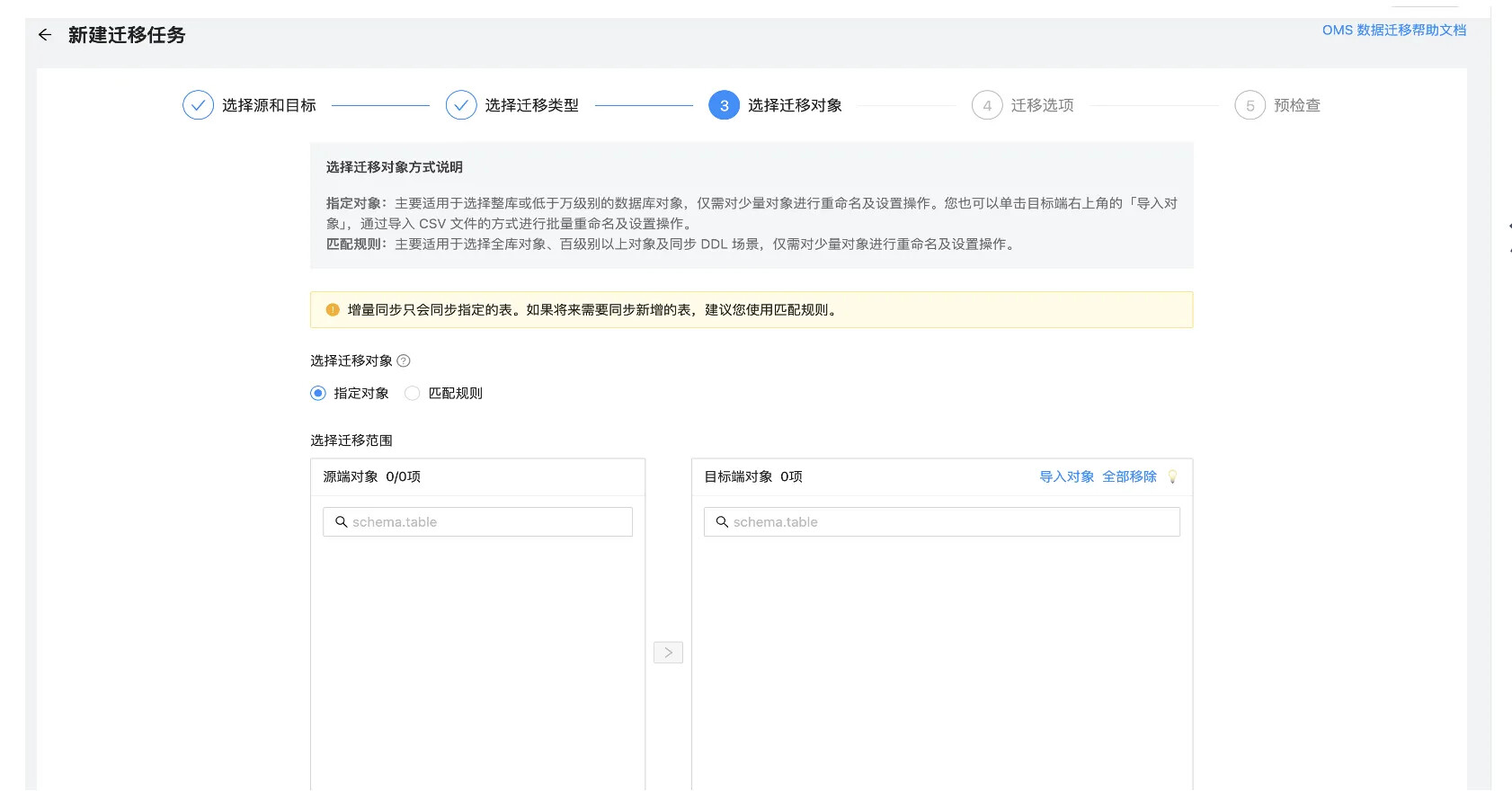
【问题描述】在新建迁移任务时,选择迁移对象步骤无法找到需要迁移的表,即下图选择迁移对象列表中没有需要迁移的表。
【问题原因】数据源使用用户权限不足。
【解决办法】检查数据源使用的用户权限并进行授权。
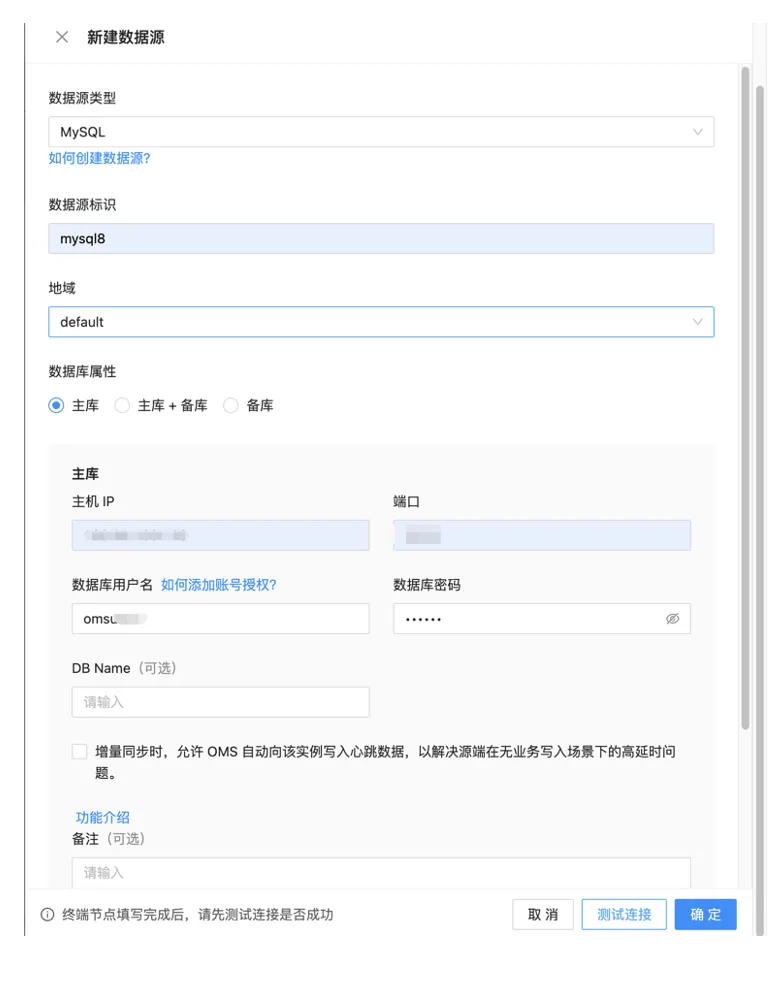
【问题描述】新建数据源类型时,新建数据源标识为8时报错连接失败。
【解决办法】使用 MySQL_native_password 参数修改用户密码:ALTER USER ‘user’@’%’ IDENTIFIED WITH MySQL_native_password BY ‘xxx’;
【问题描述】全量、增量、store 未创建成功。
【问题原因】OMS 对资源有防御性检测,当 CPU、内存、磁盘超出80%时无法创建链路。
【解决办法】
在 OMS 运维监控-机器页面中查看 OMS 机器资源情况,如果使用超过 80% 则释放部分不必要的服务或链路或增加资源。
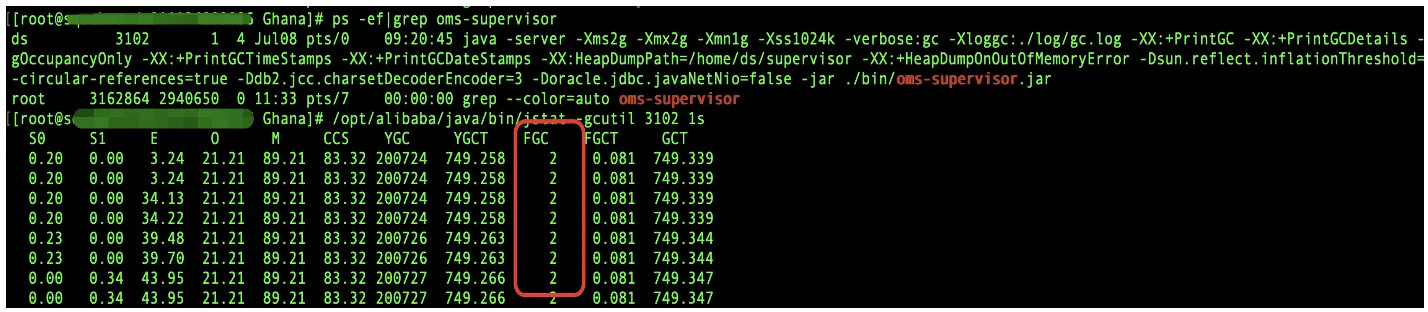
查看 OMS 管控相关的组件是否存在 fullgc 情况:
如果存在 fullgc 情况,则编辑对应启动脚本中的 jvm 内存配置,在 /etc/supervisor/conf.d 中的配置文件可以找到对应的启动脚本。
重启存在 fullgc 情况的 OMS 组件。
查看组件名命令:supervisorctl status
重启命令:supervisorctl restart 组件名
【问题描述】
【问题原因】OMS 链路状态由 supervisor 组件采集链路状态汇报管控,大多数可能是 supervisor 等组件内存不足导致。
【解决办法】
【问题描述】
全量 + 增量链路,在全量初始化的数据量非常大的情况下,全量迁移耗费很长时间,增量启动时候发现增量 store 数据已经不存在。
【解决办法】在迁移前评估大概数据量,如果全量迁移数据量比较大的情况下,在迁移前后不同阶段可以通过如下三种方式进行调节:
【问题描述】全量迁移中,存在如下情况的表的迁移速度很慢:
【问题原因】
【解决办法 1】
【解决办法 2】
【问题描述】
源表字段和目标表字段不一致。
【解决办法 1】修改目标表字段,改成和源端表一致。
【解决办法 2】忽略不一致的字段,配置:sink.ignoreRedunantColumnsReplicate=true
【问题描述】目标非空异常报错
【问题原因】在目标表已存在部分数据的情况下,为防止出现用户选错目标库目标表导致数据写入错误,OMS 会默认报错,目的是使用户确认目标表已有数据情况是否正常。
【解决办法】需要用户自行判断目标表中已经有数据了是否正常,如果正常,恢复任务继续运行即可。
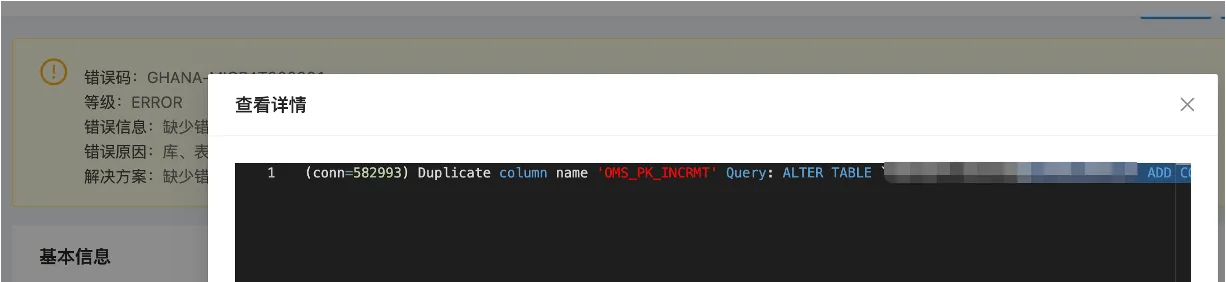
【问题描述】源端 OceanBase 有额外字段 OMS_PK_INCRMT 导致迁移失败。
【问题原因】当源端是 OceanBase 数据库时,当表中出现 OMS_PK_INCRMT 保留字段名,说明源端表之前是从其他库迁移而来,并且是无主键和唯一键的表,一般这种情况下在 OMS 中做了正向切换步骤时会自动删除 OMS_PK_INCRMT 字段。
【解决办法】当前源端库中删除 OMS_PK_INCRMT 字段。
【问题描述】
OceanBase store 由于数据库版本比 cdc 高导致失败,部分版本的在日志中报 check_ OceanBase server_version_valid_fail 关键错误信息。
【解决办法】
【问题描述】start lsn locate fail 或者 -4016
OceanBase store clog 中无数据字典信息,通常报错 start lsn locate fail 或者 -4016。
【解决办法1】
缩短数据字典 dump 时间:alter system set dump_data_dictionary_to_log_interval = ‘1h‘,等待1小时后再次启动 store。
【解决办法2】
手动触发 CALL DBMS_DATA_DICT.TRIGGER_DUMP()
【解决办法3】
出现-4016错误码的可能原因可能是 clog 磁盘资源不足被清理了,4.x 可以通过如下 SQL 判断 clog 是否被清理:
WITH palf_log_stat AS (
SELECT
tenant_id,
MAX(begin_scn) AS palf_available_start_scn,
MIN(end_scn) AS palf_available_latest_scn,
SCN_TO_TIMESTAMP(MAX(begin_scn)) AS palf_available_start_scn_display,
SCN_TO_TIMESTAMP(MIN(end_scn)) AS palf_available_latest_scn_display
FROM GV$OB_LOG_STAT
WHERE tenant_id & 0x01 = 0 or tenant_id = 1
GROUP BY tenant_id
),
archivelog_stat AS (
SELECT
a.tenant_id AS tenant_id,
MIN(b.start_scn) AS archive_start_scn,
a.checkpoint_scn AS archive_latest_scn,
a.checkpoint_scn_display AS archive_available_latest_scn_display
FROM CDB_OB_ARCHIVELOG a
LEFT JOIN CDB_OB_ARCHIVELOG_PIECE_FILES b
ON a.tenant_id = b.tenant_id AND a.round_id = b.round_id
AND b.file_status != 'DELETED' AND a.STATUS = 'DOING'
GROUP BY a.tenant_id
)
SELECT
pls.tenant_id,
pls.palf_available_start_scn,
pls.palf_available_latest_scn,
pls.palf_available_start_scn_display AS palf_available_start_scn_display,
pls.palf_available_latest_scn_display AS palf_available_latest_scn_display,
als.archive_start_scn AS archive_available_start_scn,
als.archive_latest_scn AS archive_available_latest_scn,
CASE WHEN als.archive_start_scn IS NOT NULL THEN SCN_TO_TIMESTAMP(als.archive_start_scn) ELSE NULL END AS archive_available_start_scn_dispalay,
als.archive_available_latest_scn_display
FROM palf_log_stat pls
LEFT JOIN archivelog_stat als ON pls.tenant_id = als.tenant_id
GROUP BY pls.tenant_id, pls.palf_available_start_scn;
【问题描述】binlog 没有更新提示,store 位点不再前进。
【解决办法】数据源新建时需要勾选心跳选项。
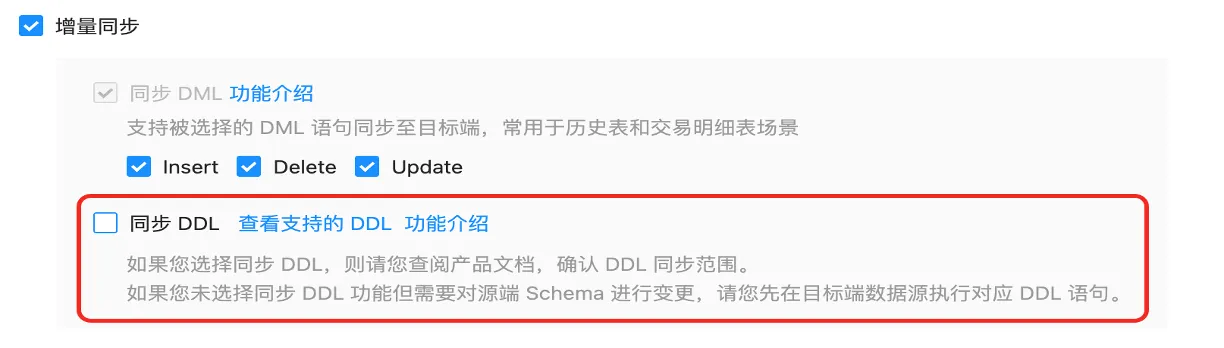
【问题描述】增量同步过程中报目标表字段不存在。
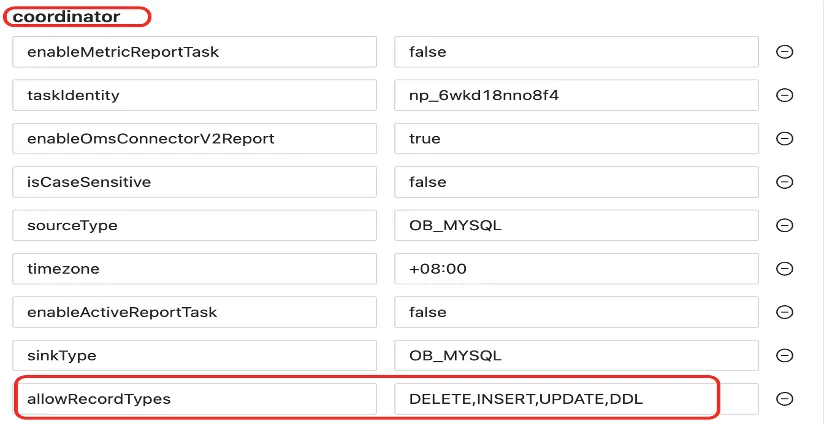
【问题原因】大多数情况下是因为链路创建时没有勾选“同步DDL”选项,导致源端新增字段后,目标端没有同步新增。
【解决办法】在 Incr-Sync 增量组件配置 coordinator. allowRecordTypes 中增加 DDL,如 coordinator. allowRecordTypes=DELETE,INSERT,UPDATE,DDL。
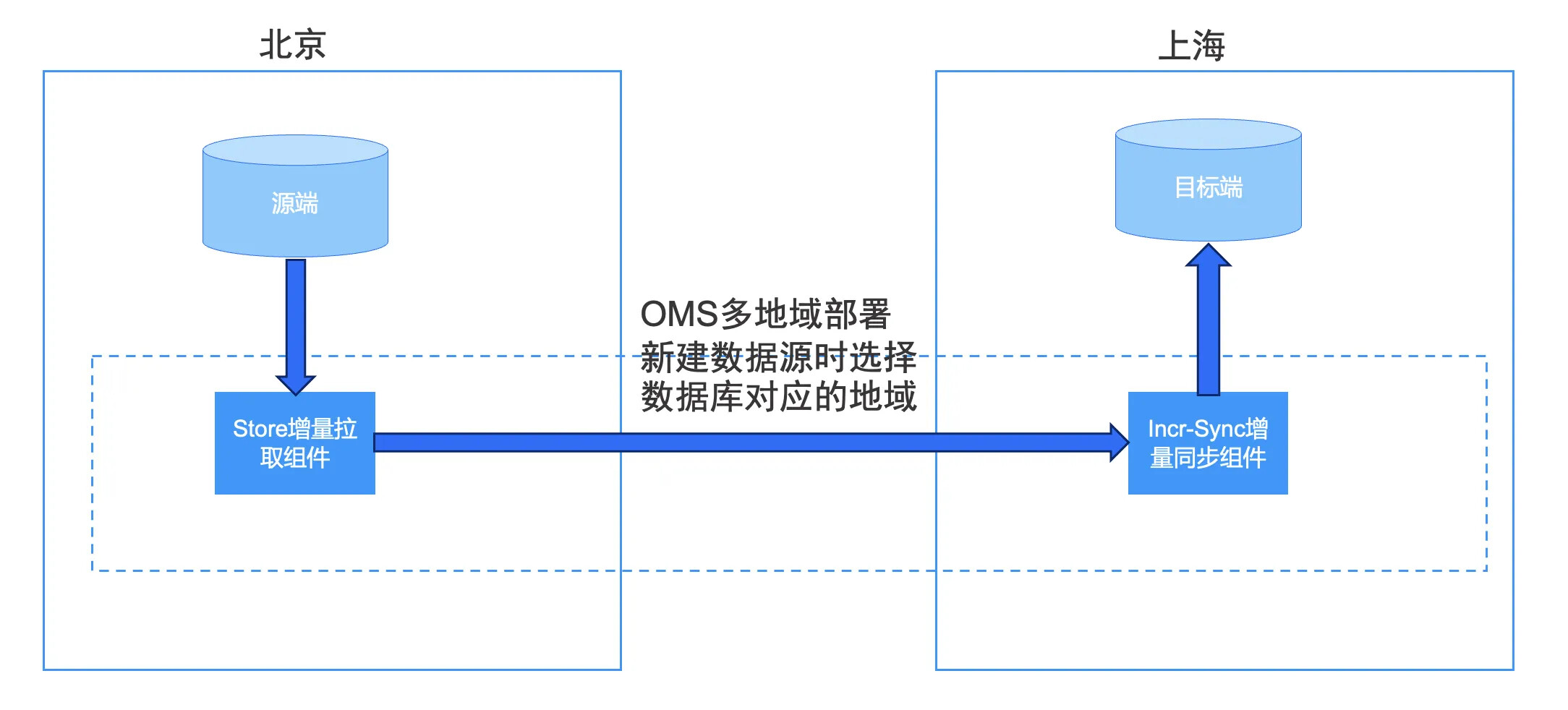
由于跨机房场景对带宽要求较高有限,在数据迁移过程中,数据写入目标端或读取源端数据可能会出现延迟和性能慢的情况,因此跨机房数据迁移通常需要采用 OMS 多地域部署。
在 OMS 多地域部署场景中,新建数据源时,只要选择数据库对应地域新建链路,OMS 会自动将store 组件在源端新建,其次写入目标端的增量同步组件会在目标端自动新建。
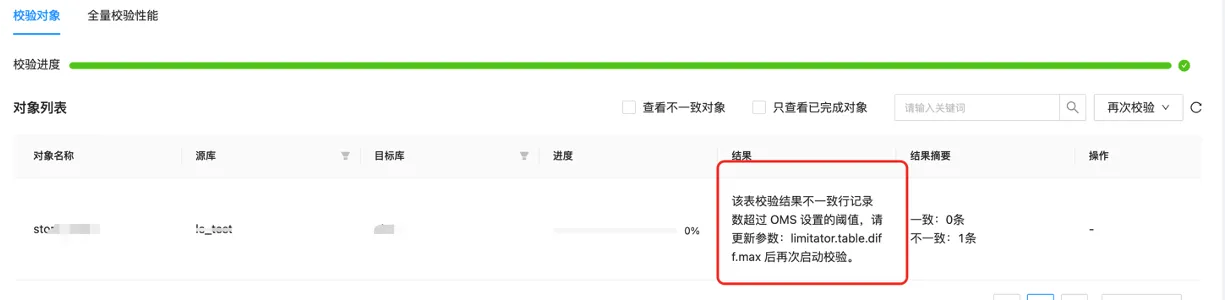
【问题描述】该表校验结果不一致行记录数超过 OMS 设置的阈值。
【解决办法】
调大 limitator.table.diff.max 参数,默认10000。
调大 task.checker_jvm_param 参数控制的 jvm 参数,改大 limitator.table.diff.max 后一般需要同时调大 jvm 内存。
内存溢出 java heap space oom 错误,也需要调整 jvm 参数。
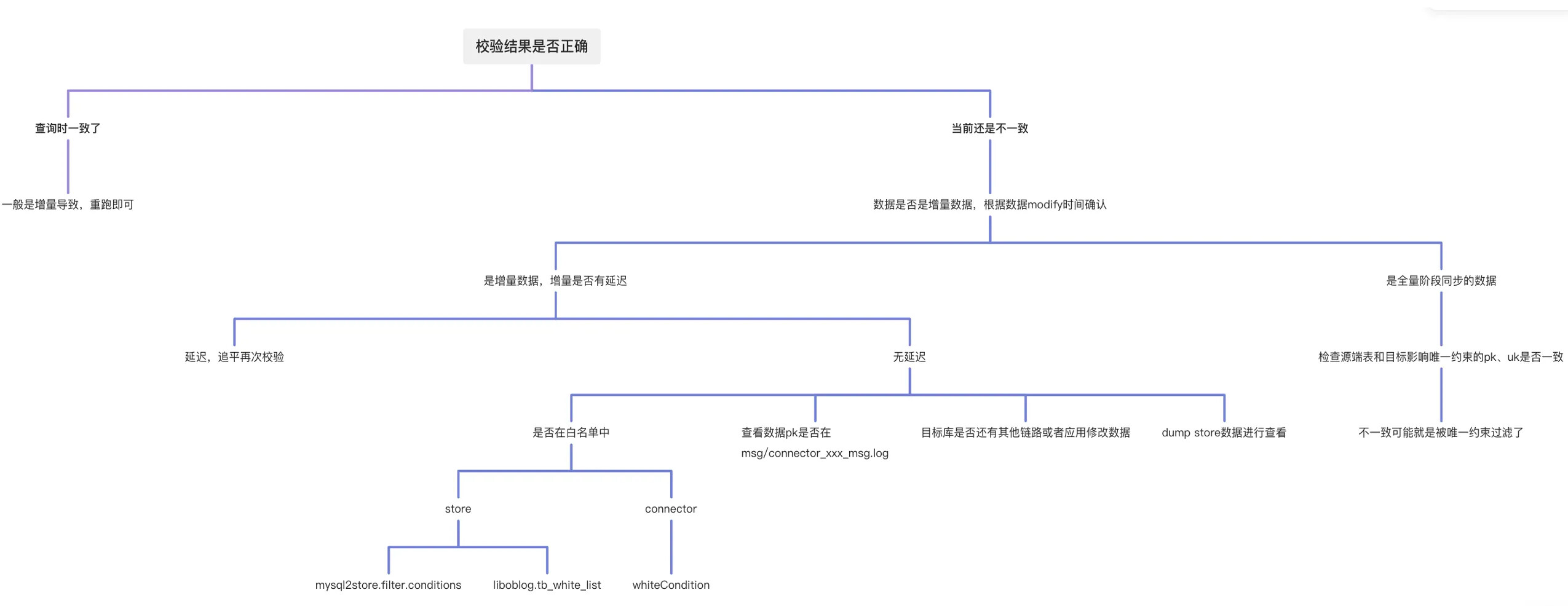
数据不一致是全量校验阶段比较常见的问题,当数据校验结果出现两边数据不一致的情况时,首先需要查看不一致的原因。
【解决方法】
查找到校验结果不一致的组件,分别去源端和目标端再次查询确认,人工比对后:
![]()
![]()
![]()
学习
![]()
![]()
![]()
学习打卡
学习学习
打卡学习
感谢分享,必须要学习!!!
一起努力
继续打卡学习,考试券在召唤 ![]()
![]()
11
111
222
感谢
更新
11
11
学习打卡
学习打卡