

这次课程的课程文档和在线体验实验,都是 obdiag 的研发同学靖顺专门为这期课程设计的。
感谢靖顺老哥!
写在开头
你是否还在为 OceanBase 数据库的诊断而头疼不已?
是否还在深夜里对着电脑屏幕,熬夜到天明,只为了追踪那一闪即逝的性能瓶颈?
面对信息收集交互时间长、根因分析不知道从何下手、卡合并的困扰、频繁的锁冲突、飙升的 CPU 高负载、突如其来的内存爆满以及不断攀升的 RT 响应时间,是否已经让你愁到秃头?
每一次故障排查都像是在黑暗中摸索,熬白了发、熬垮了精神、熬干了热情。
当分布式系统的复杂性被交织在一起时,问题定位变得异常艰难:是哪里的信息更新不及时导致决策滞后?为何总是找不到问题的根本原因?

在本期课程中,就给大家推荐一款 OceanBase 官方推出的敏捷诊断工具 obdiag,会帮助大家提高对 OceanBase 数据库进行诊断时的工作效率。

边学边练,效果拔群
正所谓 “纸上得来终觉浅,实践才能出真知”,强烈推荐大家点击下面的链接,根据在线体验页面左边的实验文档,亲手体验一把如何通过 obdiag 来进行 OceanBase 集群诊断。
-
在线实验地址:《通过敏捷诊断工具 obdiag 快速诊断 OceanBase 集群》
- 这个实验可以使用以下连接串连接数据库:
obclient -h127.0.0.1 -uroot@sys -P2881 -Dtestdb -A
说明:
因为是实验环境,所以可以偷懒使用 sys 租户。
但生产环境中尽量不要在 sys 租户里直接创建数据库对象,尽量在用户租户里进行相关操作。
-
大家在实验环境中,可以尽可能地去通过搞破坏,来构造一些异常场景,然后试试用 obdiag 能分析出哪些信息。
- 例如在实验环境中,可以尝试用 obdiag 这个工具,去解决一下《遇到 OBServer 中非预期报错的排查方法》实验中的非预期报错。
CREATE TABLE t1 (
c1 TIMESTAMP
CHECK(c1 + UNIX_TIMESTAMP() > '2025-07-30 01:02:03'));
- 如果比较极端和激进的话,甚至可以考虑手动杀死 observer 进程,然后看看用 obdiag 能够获取哪些信息?
# 用 top 看下 observer 进程的 PID(进程 ID)
top
# 用 kill -9 PID 手动杀死 observer 进程
kill -9 1234
-
课后小测地址:【DBA 实战营】OceanBase 敏捷诊断工具 obdiag
- 大家完成课后小测,并在小测中上传实验截图,判卷通过后就会自动获取 10 积分,并自动获得抽奖资格。有机会获得实体礼物或高额积分奖励。

小提示:
- 需要先登录 OceanBase 账号,才能初始化屏幕右边的实验环境进行实验。
- 在实验环境里,干什么都可以。大家不要受限于屏幕左边的实验手册,可以天马行空地做一些你感兴趣的事情,或者验证一些你对 OceanBase 官网文档的疑问、以及自己的猜想等等(甚至可以尝试怎么搞能把这个实验环境里的 OBServer 给弄崩)。
- 欢迎大家平时在学习 OceanBase 的过程中,也都能充分利用在线体验页面为您提供的一些实验环境,来体验 OceanBase 中您感兴趣的新特性。
闲言少叙,正文开始。
obdiag 介绍
OceanBase 是原生分布式数据库系统,故障根因分析通常是比较繁琐的,因为涉及的因素可能有很多,如机器环境、配置参数、运行负载等等。
专家在排查问题的时候需要获取大量的信息来分析故障,如何高效的获取故障场景下分散在各个节点的信息,挖掘出其中的关联性,这便是 OceanBase 诊断工具 (OceanBase Diagnostic Tool,简称 obdiag) 需要解决的问题。

obdiag 特性简介
obdiag 被定位为 OceanBase 敏捷诊断工具。整体使用上具备以下的特点:
- 极致轻量:提供 rpm 包和 OBD 上部署的模式,均可一键部署安装,rpm 包不到 30MB 大小。可以选择部署到任意一台能连接到集群各个节点的上。部署 obdiag 的机器可以在跳板机上、管控机器上,不一定要部署到 OBServer 所在的节点。
- 简单易用:一条命令搞定安装,一键集群巡检、一键信息收集、一键诊断分析、一键根因分析等功能全部可以通过一条命令搞定,简单易用。
- 完全开源:obdiag 是 python 代码开发的,源代码 100% 开源,详见:github 仓库地址。
- 高度可扩展:obdiag 的一键巡检功能、一键场景化信息收集功能、一键根因分析功能都是插件化的,用户可自行低成本的添加场景来定制化诊断的场景。

obdiag 功能简介
obdiag 现有功能包含了对于 OceanBase 日志、SQL Audit 以及 OceanBase 进程堆栈等信息进行扫描、收集、分析、诊断,可以在 OceanBase 集群不同的部署模式下(OCP,OBD 或用户根据文档手工部署)实现一键诊断执行。obdiag 的功能如下:

- 一键集群巡检:使用 obdiag check 命令可对 OceanBase 数据库集群相关状态进行巡检,目前支持从系统内核参数、内部表等方式对 OceanBase 的集群进行分析,发现可能会导致集群出现异常问题的点并给出运维建议。
- 一键诊断分析:使用 obdiag analyze 命令可对 OceanBase 数据库相关的诊断信息进行分析,目前支持对 OceanBase 的日志进行一键分析,找出发生过的错误信息;一键全链路诊断分析,展示全链路诊断树,定位链路慢在何处。
- 一键信息收集:使用 obdiag gather 命令可对 OceanBase 数据库相关的诊断信息进行收集。目前支持基础诊断信息收集和基于场景的诊断信息一键收集。
- 一键根因分析:使用 obdiag rca 命令可对 OceanBase 数据库相关的诊断信息进行分析,目前支持对 OceanBase 的异常场景进行分析,找出可能导致问题的原因。
安装部署
安装
obdiag 工具可以独立部署使用也可以通过 OBD 来使用,以下讲述一下独立部署的使用方法。
obdiag 独立部署使用
如果您的待诊断集群是通过其他方式部署(非 OBD 部署),可以下面的方式进行安装部署 obdiag。
- 在线部署(可访问外网的情况下可选择)
sudo yum install -y yum-utils
sudo yum-config-manager \
--add-repo https://mirrors.aliyun.com/oceanbase/OceanBase.repo
sudo yum install -y oceanbase-diagnostic-tool
source /opt/oceanbase-diagnostic-tool/init.sh
- 离线部署(不可访问外网的情况下可选择) OceanBase官网 下载页 下载新版的 OceanBase 数据库定制的敏捷诊断工具(obdiag)。
yum install -y oceanbase-diagnostic-tool*.rpm
source /opt/oceanbase-diagnostic-tool/init.sh
- debian系(如 Ubuntu)部署 OceanBase官网 下载页 下载新版的 OceanBase 数据库定制的敏捷诊断工具(obdiag)。
apt-get update
apt-get install alien -y
alien --scripts --to-deb oceanbase-diagnostic-tool*.rpm # 转为 deb 包
dpkg -i oceanbase-diagnostic-tool*.deb
source /opt/oceanbase-diagnostic-tool/init.sh
配置
obdiag 配置文件的路径有两个,一个是用户侧的配置文件,支持自定义路径。一个是 obdiag 自用的系统配置文件,一般情况下无需修改。下面分别介绍这两个配置文件:
用户侧配置文件
用户侧配置文件可通过 obdiag config 命令快速生成或者直接编辑配置文件,文件的默认路径是 ~/.obdiag/config.yml,其样板文件位于 ~/.obdiag/example。
obdiag config -h <db_host> -u <sys_user> [-p password] [-P port]
配置项说明如下:
| 参数名称 | 是否必须 | 说明 |
|---|---|---|
| db_host | 是 | OceanBase 集群 sys 租户的连接地址 |
| sys_user | 是 | OceanBase 集群sys 租户的连接用户,为避免权限问题建议使用 ‘root@sys’。当通过 obproxy 进行连接时,需要附带加上集群名(如 ‘root@sys#obtest’ )。 |
| -p password | 否 | OceanBase 集群 sys 租户的连接密码,默认为空 |
| -P port | 否 | OceanBas e集群 sys 租户的端口,默认为 2881 |
例子:
# 密码非空例子
obdiag config -hx.x.x.xx -uroot@sys -p***** -P2881
# 空密码场景
obdiag config -hx.x.x.xx -uroot@sys -P2881
# 通过 obproxy 场景
obdiag config -hx.x.x.xx -uroot@sys#obtest -p***** -P2883
执行完成后在 ~/.obdiag/config.yml 中会生成一份新的配置,如果原来 ~/.obdiag/config.yml 存在内容,将会将老配置备份到 ~/.obdiag/backup_conf 目录下。
Tips:
- 如何管理多个集群的配置文件?
# 生成多个集群的配置,使用obdiag的时候直接指定对应的集群配置即可,比如
obdiag gather log –c cluster_1.yaml
obdiag gather log –c cluster_2.yaml
- obd 部署的集群,在使用 obdiag 的时候无需额外生成配置文件,直接使用功能即可。obd 上使用 obdiag 需要在 obdiag 的命令前面增加 obd 命令,并且加上具体的集群名,例如:obdiag gather log 即变成 obd obdiag gather log <cluster_name>, obd 会负责生成 obdiag 的配置。
系统配置文件
位于 /opt/oceanbase-diagnostic-tool/conf/inner_config.yml
obdiag:
basic:
config_path: ~/.obdiag/config.yml # 用户侧的配置文件路径
# 通过 obdiag config 命令执行时,老配置文件会进行备份,备份路径
config_backup_dir: ~/.obdiag/backup_conf
file_number_limit: 20 # 对单台远程主机执行一次采集命令回传的文件数量上限
file_size_limit: 2G # 对单台远程主机执行一次采集命令回传的文件大小上限
logger:
log_dir: ~/.obdiag/log # obdiag 自身的执行日志存储路径
log_filename: obdiag.log # obdiag 自身的执行日志存储文件名
file_handler_log_level: DEBUG # obdiag 自身的执行日志输出的最低级别
log_level: INFO # obdiag 自身的执行日志级别
mode: obdiag
stdout_handler_log_level: INFO # obdiag 打印到屏幕上的最低日志级别
check: # 巡检所需配置,一般场景下不需要变更
ignore_version: false # 忽略 OceanBase 的版本
report:
report_path: "./check_report/" # 巡检报告输出路径
export_type: table # 巡检报告输出类型
package_file: "~/.obdiag/check_package.yaml" # 巡检套餐文件路径
tasks_base_path: "~/.obdiag/tasks/" # 巡检任务的基础目录
gather:
scenes_base_path: "~/.obdiag/gather/tasks" # gather 场景的目录
rca:
result_path: "./rca/" # rca结果存储路径
Tips:
- 经常修改的配置:obdiag.basic.file_number_limit 和 obdiag.basic.file_size_limit,在日志收集功能使用时遇到提示远程主机的日志超过一定数量或者压缩文件超过一定大小,可以通过调整这两个参数来完成收集日志。
使用说明
一键集群巡检
使用 obdiag check 命令可帮助 OceanBase 数据库集群相关状态巡检,目前支持从系统内核参数、内部表等方式对 OceanBase 的集群进行分析,发现已存在或可能会导致集群出现异常问题的原因分析并提供运维建议。
巡检场景清单

一键巡检
# 默认执行除filter组里的所有巡检项
obdiag check
# 部署环境检查
obdiag check --cases=build_before
# 执行sysbench时的巡检任务集合
obdiag check --cases=sysbench_run
# 执行sysbench前的巡检任务集合
obdiag check --cases=sysbench_free
# obproxy 版本检查
obdiag check --obproxy-cases=proxy
# 针对ob-operator部署在k8s中的OB集群
obdiag check run --cases=k8s_basic
obdiag check run --cases=k8s_performance
一键分析功能
使用方法
obdiag analyze <analyze type> [options]
analyze type 包含如下:
- log:一键分析 OceanBase 的日志。
- flt_trace: 一键全链路诊断。
一键日志分析
使用该命令可以一键在线分析 OceanBase 集群的日志,或者通过 --files 开启离线分析模式。
# 在线分析最近一小时的日志
# 该指令执行的时候会从远程主机上拉取最近一小时的日志进行分析,诊断出出现过的错误
obdiag analyze log --since 1h
# 在线分析最近 30 分钟的日志,
# 该指令执行的时候会从远程主机上拉取最近 30 分钟的日志进行分析,诊断出出现过的错误
obdiag analyze log --since 30m
# 离线分析指定的日志文件
obdiag analyze log --files observer.log.20230831142211247
# 离线分析日志文件夹
obdiag analyze log --files ./test/
一键全链路诊断
全链路诊断是什么:OceanBase 数据库是分布式数据库,因此调用链路复杂,当出现超时问题时,往往无法快速定位是 OceanBase 内部组件或是网络的问题,运维人员只能根据经验和 observer 日志进行分析。
OceanBase 内核在 4.0 新增了 trace.log 日志,可以用于分析全链路诊断。全链路有两条路径,一条是从应用通过客户端(JDBC 或 OCI 等)下发请求给 ODP(代理服务器)访问 OBServer,访问结果返回给应用;另一条是从应用通过客户端(JDBC 或 OCI 等)直接访问 OBServer,访问结果返回给应用。全链路诊断是对全链路所有组件进行问题定位的诊断。
obdiag 全链路诊断做了什么:

obdiag 全链路诊断用法
obdiag analyze flt_trace [options]
Step 1: 查找疑似慢的 SQL
在 gv$ob_sql_audit中,如果有明确的 SQL 语句可以通过 query_sql 查到疑似慢 sql 的 flt_trace_id, 例如:
select query_sql, flt_trace_id
from oceanbase.gv$ob_sql_audit
where query_sql like 'select @@version_comment limit 1';
+----------------------------------+-------------------------------+
| query_sql | flt_trace_id |
+----------------------------------+-------------------------------+
| select @@version_comment limit 1 | 00060aa3-d607-f5f2-328b-388e |
+----------------------------------+-------------------------------+
1 row in set (0.001 sec)
其中 flt_trace_id为00060aa3-d607-f5f2-328b-388e17f687cb。
或者你也可从 obproxy、oceanbase 的 trace.log 日志中找到 flt_trace_id。
head trace.log
[2023-12-07 22:20:07.242229] [489640][T1_L0_G0][T1]
[YF2A0BA2DA7E-00060BEC28627BEF-0-0]
{"trace_id":"00060bec-275e-9832-e730-7c129f2182ac",
"name":"close_das_task","id":"00060bec-2a20-bf9e-56c9-724cb467f859",
"start_ts":1701958807240606,"end_ts":1701958807240607,
"parent_id":"00060bec-2a20-bb5f-e03a-5da01aa3308b","is_follow":false}
其中 00060bec-275e-9832-e730-7c129f2182ac 就是其flt_trace_id。
Step 2: 执行全链路诊断命令
obdiag analyze flt_trace --flt_trace_id 000605b1-28bb-c15f-8ba0-1206bc
root node id: 000605b1-28bb-c15f-8ba0-1206bc
TOP time-consuming leaf span:
+---+----------------------------------+-------------+------------------+
| ID| Span Name | Elapsed Time| NODE |
+---+----------------------------------+-------------+------------------+
| 18| px_task | 2.758 ms | OBSERVER(x.x.x.1)|
| 5 | pc_get_plan | 52 μs | OBSERVER(x.x.x.1)|
| 16| do_local_das_task | 45 μs | OBSERVER(x.x.x.1)|
| 10| do_local_das_task | 17 μs | OBSERVER(x.x.x.1)|
| 17| close_das_task | 14 μs | OBSERVER(x.x.x.1)|
+---+----------------------------------+-------------+------------------+
Tags & Logs:
-------------------------------------
18 - px_task Elapsed: 2.758 ms
NODE:OBSERVER(x.x.x.1)
tags: [{'group_id': 0}, {'qc_id': 1}, {'sqc_id': 0}...]
5 - pc_get_plan Elapsed: 52 μs
NODE:OBSERVER(x.x.x.1)
16 - do_local_das_task Elapsed: 45 μs
NODE:OBSERVER(x.x.x.3)
10 - do_local_das_task Elapsed: 17 μs
NODE:OBSERVER(x.x.x.1)
17 - close_das_task Elapsed: 14 μs
NODE:OBSERVER(x.x.x.3)
Details:
+---+----------------------------------+-------------+------------------+
| ID| Span Name | Elapsed Time| NODE |
+---+----------------------------------+-------------+------------------+
| 1 | TRACE | - | - |
| 2 | └─com_query_process | 5.351 ms | OBPROXY(x.x.x.1) |
| 3 | └─mpquery_single_stmt | 5.333 ms | OBSERVER(x.x.x.1)|
| 4 | ├─sql_compile | 107 μs | OBSERVER(x.x.x.1)|
| 5 | │ └─pc_get_plan | 52 μs | OBSERVER(x.x.x.1)|
| 6 | └─sql_execute | 5.147 ms | OBSERVER(x.x.x.1)|
| 7 | ├─open | 87 μs | OBSERVER(x.x.x.1)|
| 8 | ├─response_result | 4.945 ms | OBSERVER(x.x.x.1)|
| 9 | │ ├─px_schedule | 2.465 ms | OBSERVER(x.x.x.1)|
| 10| │ │ ├─do_local_das_task | 17 μs | OBSERVER(x.x.x.1)|
| 11| │ │ ├─px_task | 2.339 ms | OBSERVER(x.x.x.2)|
| 12| │ │ │ ├─do_local_das_task | 54 μs | OBSERVER(x.x.x.2)|
| 13| │ │ │ └─close_das_task | 22 μs | OBSERVER(x.x.x.2)|
| 14| │ │ ├─do_local_das_task | 11 μs | OBSERVER(x.x.x.1)|
| 15| │ │ ├─px_task | 2.834 ms | OBSERVER(x.x.x.3)|
| 16| │ │ │ ├─do_local_das_task | 45 μs | OBSERVER(x.x.x.3)|
| 17| │ │ │ └─close_das_task | 14 μs | OBSERVER(x.x.x.3)|
| 18| │ │ └─px_task | 2.758 ms | OBSERVER(x.x.x.1)|
| 19| │ ├─px_schedule | 1 μs | OBSERVER(x.x.x.1)|
| 20| │ └─px_schedule | 1 μs | OBSERVER(x.x.x.1)|
| ..| ...... | ... | ...... |
+---+----------------------------------+-------------+------------------+
For more details, please run cmd
' cat analyze_flt_result/000605b1-28bb-c15f-8ba0-1206bcc08aa3.txt '
一键信息采集功能
obdiag 的信息采集功能包括一键基础信息的采集和一键场景化信息采集。
一键常规信息的采集
使用方式:
obdiag gather <gather type> [options]
gather type 包含如下:
- log:一键收集所属 OceanBase 集群的日志。
- sysstat:一键收集所属 OceanBase 集群主机信息。
- clog:一键收集所属 OceanBase 集群的 clog 日志。
- slog:一键收集所属 OceanBase 集群的 slog 日志。
- plan_monitor:一键收集所属 OceanBase 集群指定 trace_id 的并行 SQL 的执行详情信息。
- stack:一键收集所属 OceanBase 集群的堆栈信息。
- perf:一键收集所属 OceanBase 集群的 perf 信息。
- obproxy_log:一键收集所属 OceanBase 集群所依赖的 ODP 的日志。
- all:一键统一收集所属 OceanBase 集群的诊断信息,包括收集 OceanBase 集群日志、主机信息、OceanBase 集群堆栈信息、OceanBase 集群 perf 信息。
一键场景化信息采集
使用obdiag gather scenes 命令可以一键执行将某些问题场景所需要的排查信息统一捞回,解决分布式节点信息捞取难的痛点。
支持场景
使用 obdiag gather scene list 命令

一键场景信息采集
使用方法
obdiag gather scene run --scene={SceneName}
# 应用报错问题
obdiag gather scene run --scene=other.application_error
# obproxy 无故重启
obdiag gather scene run --scene=obproxy.restart
# 数据备份问题
obdiag gather scene run --scene=observer.backup
# 备份清理问题
obdiag gather scene run --scene=observer.backup_clean
# clog 盘满
obdiag gather scene run --scene=observer.clog_disk_full
# 合并问题
obdiag gather scene run --scene=observer.compaction
# CPU 高
obdiag gather scene run --scene=observer.cpu_high
# 主备库延迟
obdiag gather scene run --scene=observer.delay_of_primary_and_backup
# 日志归档问题
obdiag gather scene run --scene=observer.log_archive
# 长事务
obdiag gather scene run --scene=observer.long_transaction
# 内存问题
obdiag gather scene run --scene=observer.memory
# SQL 性能问题, 此处 env 中的 trace_id 对应 gv$ob_sql_audit 的 trace_id
obdiag gather scene run --scene=observer.perf_sql \
--env "{db_connect='-hxx -Pxx -uxx -pxx -Dxx', trace_id='xx'}"
# 数据恢复问题
obdiag gather scene run --scene=observer.recovery
# observer无故重启
obdiag gather scene run --scene=observer.restart
# 有主改选或者无主选举的切主
obdiag gather scene run --scene=observer.rootservice_switch
# SQL 执行出错,此处 env 中的 trace_id 对应 gv$ob_sql_audit 的 trace_id
obdiag gather scene run --scene=observer.sql_err \
--env "{db_connect='-hxx -Pxx -uxx -pxx -Dxx', trace_id='xx'}"
# 悬挂事务
obdiag gather scene run --scene=observer.suspend_transaction
# unit迁移/缩小 副本不均衡问题
obdiag gather scene run --scene=observer.unit_data_imbalance
# 未能明确问题的场景
obdiag gather scene run --scene=observer.unknown
# SQL PX 收集报错源节点日志,两个参数:
# trace_id:必填,会根据该trace_id去搜集 px 的日志
# estimated_time:选填,默认为当前时间,会搜这个时间点以前一周的日志
obdiag gather scene run --scene=observer.px_collect_log \
--env "{trace_id='Yxx', estimated_time='2024-04-19 14:46:17'}"
一键根因分析功能
使用 obdiag rca 命令可帮助 OceanBase 数据库相关的诊断信息分析,目前支持对 OceanBase 的异常场景进行分析,找出可能导致问题的原因。
支持场景清单
使用该命令可以获取根因分析目前支持的场景
obdiag rca list

一键根因分析
使用如下命令可一键分析根因
obdiag rca run --scene=<scene_name>
例子:
obdiag rca run --scene=ddl_disk_full --env tenant_name=test1 \
--env table_name=t555 --env action_type=add_index \
--env index_name=k1 --env database_name=xxxx
结果:

从输出中可发现节点存在空间不足的问题,分别为 -4.32 TB 和 -4.31 TB,由此为依据进行对应节点的扩容即可。
诊断场景添加
本章介绍如何自定义扩充诊断场景,用以快速适应自身集群的诊断需求。
一键巡检场景添加
巡检场景所在目录~/.obdiag/check;展开后可看到已有的巡检场景目录如下,其中obproxy_check_package.yaml和observer_check_package.yaml分别存的是obproxy和observer的巡检项集合。
#tree
.
├── obproxy_check_package.yaml
├── observer_check_package.yaml
└── tasks
├── obproxy
│ └── version
│ └── bad_version.yaml
└── observer
├── cluster
│ ├── core_file_find.yaml
│ ├── data_path_settings.yaml
│ ├── deadlocks.yaml
│ ├── ...
├── cpu
│ └── oversold.yaml
├── disk
│ ├── clog_abnormal_file.yaml
│ ├── disk_full.yaml
│ ├── disk_hole.yaml
│ ├── ...
├── err_code
│ ├── find_err_4000.yaml
│ ├── ...
├── sysbench
│ ├── sysbench_free_test_cpu_count.yaml
│ ├── sysbench_free_test_memory_limit.yaml
│ ├── sysbench_free_test_network_speed.yaml
│ ├── ...
├── system
│ ├── aio.yaml
│ ├── dependent_software_swapon.yaml
│ ├── dependent_software.yaml
│ ├── ...
└── version
├── bad_version.yaml
└── old_version.yaml
其中tasks文件夹存储了已经有的巡检项,一个大的巡检项目就是一个yaml文件。我们所说的自定义巡检项,其实就是按照一定的规则去编写一个yaml文件的task。
task 文件的示例如下:
info: testinfo
task:
- version: "[3.1.0,3.2.4]"
steps:
{steps_object}
- version: "[4.2.0.0,4.3.0.0]"
steps:
{steps_object}
说明:
| 参数名 | 是否必填 | 描述 |
|---|---|---|
| info | 是 | 声明这个 yaml 使用的场景,方便维护。 |
| version | 否 | 表示适用的版本,用 Str 的形式表示范围,需要完整的数字的版本号。 |
OceanBase 数据库 V3.x 版本为三位,例如 [3.1.1,3.2.0]。
OceanBase 数据库 V4.x 版本为四位,例如:[4.1.0.0,4.2.0.0]。|
|steps|是|所执行步骤,为 list 结构。|
具体编写教程参见官网文档:https://www.oceanbase.com/docs/common-obdiag-cn-1000000000691956
一键信息采集场景添加
场景所在目录 ~/.obdiag/gather/tasks,展开后可看到已有的巡检场景目录如下,其中 obproxy 目录下为 obproxy 的采集场景,observer 目录下为针对 observer 的采集场景,other 目录下一般是指其他组件的诊断采集场景。
#tree
.
├── obproxy
│ ├── obproxy_parameter.yaml
│ └── restart.yaml
├── observer
│ ├── backup_clean.yaml
│ ├── backup.yaml
│ ├── base.yaml
│ ├── clog_disk_full.yaml
│ ├── cluster_down.yaml
│ ├── compaction.yaml
│ ├── cpu_high.py
│ ├── delay_of_primary_and_backup.yaml
│ ├── io.yaml
│ ├── log_archive.yaml
│ ├── long_transaction.yaml
│ ├── memory.yaml
│ ├── perf_sql.py
│ ├── px_collect_log.py
│ ├── recovery.yaml
│ ├── restart.yaml
│ ├── rootservice_switch.yaml
│ ├── sql_err.py
│ ├── suspend_transaction.yaml
│ ├── topsql.yaml
│ ├── unit_data_imbalance.yaml
│ └── unknown.yaml
└── other
└── application_error.yaml
诊断信息收集的场景 yaml 增加和前面的巡检场景类似,本节不做赘述,下面给个例子。
#cat backup.yaml
info_en: "[backup problem]"
info_cn: "[数据备份问题]"
command: obdiag gather scene run --scene=observer.backup
task:
- version: "[2.0.0.0, 4.0.0.0]"
steps:
- type: sql
sql: "show variables like 'version_comment';"
global: true
- type: sql
sql: "SELECT * FROM oceanbase.v$ob_cluster"
global: true
- type: sql
sql: "SELECT * FROM oceanbase.__all_zone WHERE name='idc';"
global: true
- type: sql
sql: "select svr_ip,zone,with_rootserver,status,block_migrate_in_time,start_service_time,stop_time,build_version from oceanbase.__all_server order by zone;"
global: true
- type: sql
sql: "SELECT zone, concat(svr_ip, ':', svr_port) observer, cpu_capacity, cpu_total, cpu_assigned, cpu_assigned_percent, mem_capacity, mem_total, mem_assigned, mem_assigned_percent, unit_Num, round(`load`, 2) `load`, round(cpu_weight, 2) cpu_weight, round(memory_weight, 2) mem_weight, leader_count FROM oceanbase.__all_virtual_server_stat ORDER BY zone,svr_ip;"
global: true
- type: sql
sql: "select tenant_id,tenant_name,primary_zone,compatibility_mode from oceanbase.__all_tenant;"
global: true
- type: sql
sql: "show parameters like '%syslog_level%';"
global: true
- type: sql
sql: "show parameters like '%syslog_io_bandwidth_limit%';"
global: true
- type: sql
sql: "select count(*),tenant_id,zone_list,unit_count from oceanbase.__all_resource_pool group by tenant_id,zone_list,unit_count;"
global: true
- type: sql
sql: "show parameters like '%auto_delete_expired_backup%';"
global: true
- type: sql
sql: "select * from oceanbase.__all_virtual_backup_task;"
global: true
- type: sql
sql: "select * from oceanbase.__all_virtual_backup_info;"
global: true
- type: sql
sql: "select * from oceanbase.__all_virtual_sys_task_status where comment like '%backup%';"
global: true
- type: sql
sql: "select count(*),status from oceanbase.__all_virtual_pg_backup_task group by status;"
global: true
- type: sql
sql: "select svr_ip, log_archive_status, count(*) from oceanbase.__all_virtual_pg_backup_log_archive_status group by svr_ip, log_archive_status;"
global: true
- type: sql
sql: "select * from oceanbase.__all_rootservice_event_history where gmt_create > ${from_time} and gmt_create < ${to_time} order by gmt_create desc;"
global: true
- type: sql
sql: "select b.* from oceanbase.__all_virtual_pg_backup_log_archive_status a,oceanbase.__all_virtual_pg_log_archive_stat b where a.table_id=b.table_id and a.partition_id=b.partition_id order by log_archive_cur_ts limit 5;"
global: true
- type: log
global: false
grep: ""
- type: sysstat
global: false
sysstat: ""
- version: "[4.0.0.0, *]"
steps:
- type: sql
sql: "show variables like 'version_comment';"
global: true
- type: sql
sql: "SELECT * FROM oceanbase.DBA_OB_ZONES;"
global: true
- type: sql
sql: "SELECT * FROM oceanbase.DBA_OB_SERVERS;"
global: true
- type: sql
sql: "SELECT * FROM oceanbase.GV$OB_SERVERS;"
global: true
- type: sql
sql: "SELECT * FROM oceanbase.DBA_OB_UNIT_CONFIGS;"
global: true
- type: sql
sql: "SELECT * FROM oceanbase.DBA_OB_RESOURCE_POOLS;"
global: true
- type: sql
sql: "SELECT * FROM oceanbase.DBA_OB_TENANTS;"
global: true
- type: sql
sql: "SELECT c.TENANT_ID, e.TENANT_NAME, concat(c.NAME, ': ', d.NAME) `pool:conf`,concat(c.UNIT_COUNT, ' unit: ', d.min_cpu, 'C/', ROUND(d.MEMORY_SIZE/1024/1024/1024,0), 'G') unit_info FROM oceanbase.DBA_OB_RESOURCE_POOLS c, oceanbase.DBA_OB_UNIT_CONFIGS d, oceanbase.DBA_OB_TENANTS e WHERE c.UNIT_CONFIG_ID=d.UNIT_CONFIG_ID AND c.TENANT_ID=e.TENANT_ID AND c.TENANT_ID>1000 ORDER BY c.TENANT_ID;"
global: true
- type: sql
sql: "SELECT a.TENANT_NAME,a.TENANT_ID,b.SVR_IP FROM oceanbase.DBA_OB_TENANTS a, oceanbase.GV$OB_UNITS b WHERE a.TENANT_ID=b.TENANT_ID;"
global: true
- type: sql
sql: "show parameters like '%syslog_level%';"
global: true
- type: sql
sql: "show parameters like '%syslog_io_bandwidth_limit%';"
global: true
- type: sql
sql: "show parameters like '%backup%';"
global: true
- type: sql
sql: "show parameters like '%ha_low_thread_score%';"
global: true
- type: sql
sql: "SELECT * FROM oceanbase.CDB_OB_BACKUP_PARAMETER"
global: true
- type: sql
sql: "SELECT * FROM oceanbase.CDB_OB_BACKUP_JOBS limit 20;"
global: true
- type: sql
sql: "SELECT * FROM oceanbase.DBA_OB_ROOTSERVICE_EVENT_HISTORY WHERE module='backup_data' AND event ='start_backup_data';"
global: true
- type: sql
sql: "SELECT * FROM oceanbase.CDB_OB_BACKUP_TASKS limit 20;"
global: true
- type: sql
sql: "SELECT * FROM oceanbase.__all_virtual_backup_schedule_task limit 20"
global: true
- type: sql
sql: "SELECT * from oceanbase.CDB_OB_BACKUP_JOB_HISTORY where STATUS = 'FAILED' limit 20;"
global: true
- type: log
global: false
grep: ""
- type: sysstat
global: false
sysstat: ""
说明:
- info_en:英文描述,在 obdiag gather scene list 的时候展示的英文描述就出自于此;
- info_cn: 中文描述,在 obdiag gather scene list 的时候展示的中文描述就出自于此;
- command:执行命令
- task.version: 诊断组件的版本适用范围
- task.steps.type: 执行的类型,目前支持 ssh/sql/log/obproxy_log/sysstat 几种;
- task.steps.type.global: 相对于节点来说是否是全局采集项,global 值为 true 的只会在第一个节点上执行一次,global 为 false 的会在每个节点上都执行。
根因分析场景添加
根因分析场景的目录为 ~/.obdiag/rca, 展开后里边是 python 文件,根因分析场景的添加稍微复杂一点,需要在 python 代码中处理根因分析的具体链路逻辑,更多详情参见 obdiag 开发者文档。
#tree
.
├── clog_disk_full.py
├── ddl_disk_full.py
├── ddl_failure.py
├── delete_server_error.py
├── disconnection.py
├── index_ddl_error.py
├── lock_conflict.py
├── log_error.py
├── major_hold.py
├── memory_full.py
├── oms_full_trans.py
├── oms_obcdc.py
├── replay_hold.py
├── suspend_transaction.py
├── transaction_disconnection.py
├── transaction_execute_timeout.py
├── transaction_not_ending.py
├── transaction_other_error.py
├── transaction_rollback.py
├── transaction_wait_timeout.py
└── unit_gc.py
总结
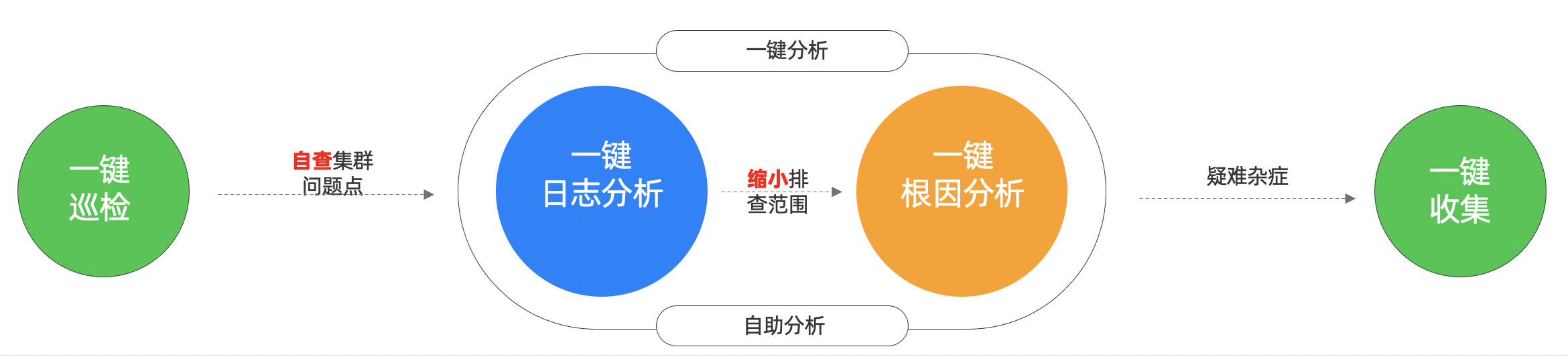
数据库自助诊断三板斧:
- 一键巡检自查集群问题点,按照诊断报告修复集群。
- 在不明确问题场景的情况下先进行一键日志分析,去缩小排查范围,如果明确场景的情况下直接进行根因分析,通过根因分析报告查看问题根因。
- 如果以上两个步骤都没能解决你的问题,那么请直接执行一键信息收集,将问题排查需要的故障诊断信息打包回传给社区问答区或者前线支持人员。
写在最后
为了进一步提升用户体验并简化对 OceanBase 数据库进行诊断的过程,敏捷诊断工具 obdiag SIG(Special Interest Group,特别兴趣小组)应运而生。

此特别兴趣小组致力于汇聚广大开发者的力量,我们热诚邀请广大开发者加入到这个充满活力与创新精神的社区中来!无论你是经验丰富的资深开发者还是刚刚起步的技术新手,只要你对 OceanBase 数据库抱有热情,并希望通过自己的努力让数据库的诊断过程更加直观简单~
